
pyhanlp 提取關鍵詞、自動摘要、新詞識別
關鍵詞提取
- 說明
- 內部採用
TextRankKeyword實現,使用者可以直接呼叫TextRankKeyword.getKeywordList(document, size)
- 內部採用
部分內容如下
談起自動摘要演算法,常見的並且最易實現的當屬TF-IDF,但是感覺TF-IDF效果一般,不如TextRank好。
TextRank是在Google的PageRank演算法啟發下,針對文本里的句子設計的權重演算法,目標是自動摘要。它利用投票的原理,讓每一個單詞給它的鄰居(術語稱視窗)投贊成票,票的權重取決於自己的票數。這是一個“先有雞還是先有蛋”的悖論,PageRank採用矩陣迭代收斂的方式解決了這個悖論。TextRank也不例外:
PageRank的計算公式:
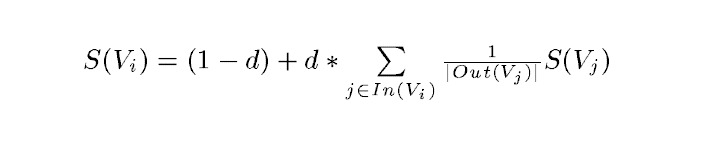
正規的TextRank公式
正規的TextRank公式在PageRank的公式的基礎上,引入了邊的權值的概念,代表兩個句子的相似度:
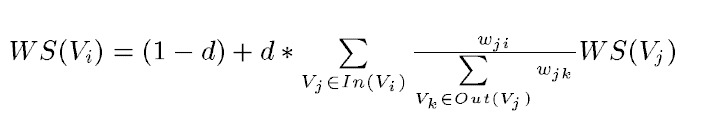
但是很明顯我只想計算關鍵字,如果把一個單詞視為一個句子的話,那麼所有句子(單詞)構成的邊的權重都是0(沒有交集,沒有相似性),所以分子分母的權值w約掉了,演算法退化為PageRank。所以說,這裡稱關鍵字提取演算法為PageRank也不為過。
另外,如果你想提取關鍵句(自動摘要)的話,請參考姊妹篇《TextRank演算法自動摘要的Java實現》。
pyhanlp中的使用方法如下
from pyhanlp import *# 關鍵詞提取 [程式設計師, 人員, 程式, 分為, 開發]
自動摘要
- 說明
- 內部採用
TextRankSentence實現,使用者可以直接呼叫TextRankSentence.getTopSentenceList(document, size)。
- 內部採用
原文部分內容
所謂自動摘要,就是從文章中自動抽取關鍵句。何謂關鍵句?人類的理解是能夠概括文章中心的句子,機器的理解只能模擬人類的理解,即擬定一個權重的評分標準,給每個句子打分,之後給出排名靠前的幾個句子。
TextRank公式
TextRank的打分思想依然是從PageRank的迭代思想衍生過來的,如下公式所示:
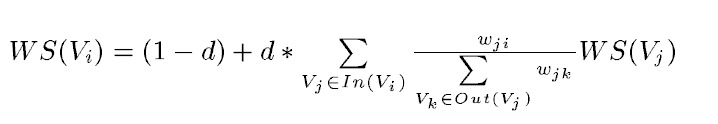
等式左邊表示一個句子的權重(WS是weight_sum的縮寫),右側的求和表示每個相鄰句子對本句子的貢獻程度。與提取關鍵字的時候不同,一般認為全部句子都是相鄰的,不再提取視窗。
求和的分母wji表示兩個句子的相似程度,分母又是一個weight_sum,而WS(Vj)代表上次迭代j的權重。整個公式是一個迭代的過程。
相似程度的計算
而相似程度wji的計算,推薦使用BM25
BM25演算法,通常用來作搜尋相關性平分。一句話概況其主要思想:對Query進行語素解析,生成語素qi;然後,對於每個搜尋結果D,計算每個語素qi與D的相關性得分,最後,將qi相對於D的相關性得分進行加權求和,從而得到Query與D的相關性得分。
pyhanlp中使用自動摘要
# 自動摘要
document = '''水利部水資源司司長陳明忠9月29日在國務院新聞辦舉行的新聞釋出會上透露,
根據剛剛完成了水資源管理制度的考核,有部分省接近了紅線的指標,
有部分省超過紅線的指標。對一些超過紅線的地方,陳明忠表示,對一些取用水專案進行區域的限批,
嚴格地進行水資源論證和取水許可的批准。
'''
TextRankSentence = JClass("com.hankcs.hanlp.summary.TextRankSentence")
sentence_list = HanLP.extractSummary(document, 3)
print(sentence_list)
sentence_list = HanLP.extractSummary(document, 2)
print(sentence_list)
sentence_list = HanLP.extractSummary(document, 1)
print(sentence_list)
sentence_list = HanLP.getSummary(document, 50)
print(sentence_list)
sentence_list = HanLP.getSummary(document, 30)
print(sentence_list)
sentence_list = HanLP.getSummary(document, 20)
print(sentence_list)
[嚴格地進行水資源論證和取水許可的批准, 有部分省超過紅線的指標, 水利部水資源司司長陳明忠9月29日在國務院新聞辦舉行的新聞釋出會上透露]
[嚴格地進行水資源論證和取水許可的批准, 有部分省超過紅線的指標]
[嚴格地進行水資源論證和取水許可的批准]
水利部水資源司司長陳明忠9月29日在國務院新聞辦舉行的新聞釋出會上透露。有部分省超過紅線的指標。
有部分省超過紅線的指標。嚴格地進行水資源論證和取水許可的批准。
有部分省超過紅線的指標。