
高併發第九彈:逃不掉的Map --> HashMap,TreeMap,ConcurrentHashMap
平時大家都會經常使用到 Map,面試的時候又經常會遇到問Map的,其中主要就是 ConcurrentHashMap,在說ConcurrentHashMap.我們還是先看一下,
其他兩個基礎的 Map 類: HashMap 和 TreeMap
HashMap:
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable,Serializable { // 這裡有個很逗的事情 hashMap 繼承了AvstractMap 為什麼還要實現Map? 據說,作者說的 這只是個錯誤的寫法 Q_Q
TreeMap:
public class TreeMap<K,V> extends AbstractMap<K,V> implements NavigableMap<K,V>, Cloneable, java.io.Serializablepublic interface NavigableMap<K,V> extends SortedMap<K,V>
| 實現 | 儲存 | 遍歷 | 效能損耗 | 鍵值對 | 安全 | 效率 | |
| TreeMap | SortMap介面,基於紅黑樹 | 預設按鍵的升序排序 | Iterator遍歷是排序的 | 插入、刪除 | 鍵、值都不能為null | 非併發安全Map | 適用於在Map中插入、刪除和定位元素 |
| HashMap | 基於雜湊散列表實現 | 隨機儲存 | Iterator遍歷是隨機的 | 基本無 | 只允許鍵、值均為null | 非併發安全Map | 適用於按自然順序或自定義順序遍歷鍵(key) |
HashMap通常比TreeMap快一點(樹和雜湊表的資料結構使然),建議多使用HashMap,在需要排序的Map時候才用TreeMap。那麼現在就聊一下 HashMap和ConcurrentHashMap 我們都知道ConcurrentHashMap 是執行緒安全的.那為什麼HashMap就執行緒不安全了呢?這裡有很不錯的解釋https://my.oschina.net/hosee/blog/673521還有一個路徑太長了.給個短的 還可以的總結起來就是: 1. resize死迴圈
我們都知道HashMap初始容量大小為16,一般來說,當有資料要插入時,都會檢查容量有沒有超過設定的thredhold,如果超過,需要增大Hash表的尺寸,但是這樣一來,整個Hash表裡的元素都需要被重算一遍。這叫rehash,這個成本相當的大。在rehash的時候,在多執行緒的時候容易造成環形連結串列 2.fail-fast 如果在使用迭代器的過程中有其他執行緒修改了map,那麼將丟擲ConcurrentModificationException,這就是所謂fail-fast策略。
這個異常意在提醒開發者及早意識到執行緒安全問題,具體原因請檢視ConcurrentModificationException的原因以及解決措施 看了這個 我覺得需要去修改一下我原來說的CopyAndWriteArrayList 了
ConcurrentHashMap來了.面試以前遇到了很多次
(1)結構 [Java7與Java8不同]
JDK7
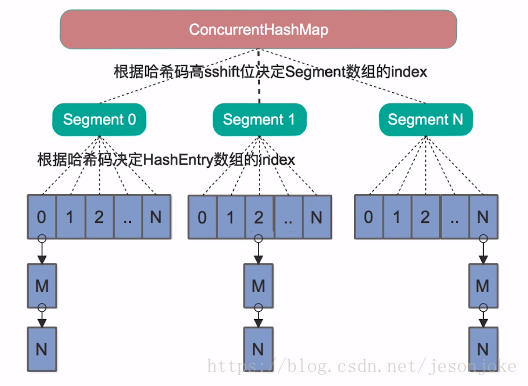
1.ConcurrentHashMap中的分段鎖稱為Segment,它即類似於HashMap(JDK7與JDK8中HashMap的實現)的結構,即內部擁有一個Entry陣列,陣列中的每個元素又是一個連結串列;同時又是一個ReentrantLock(Segment繼承了ReentrantLock)
2 . 當我們讀取某個Key的時候它先取出key的Hash值,並將Hash值得高sshift位與Segment的個數取模,決定key屬於哪個Segment。接著像HashMap一樣操作Segment。 為了保證不同的Hash值儲存到不同的Segment中,ConcurrentHashMap對Hash值也做了專門的優化。
3. 如果併發度設定的過小,會帶來嚴重的鎖競爭問題;如果併發度設定的過大,原本位於同一個Segment內的訪問會擴散到不同的Segment中,CPU cache命中率會下降,從而引起程式效能下降。(文件的說法是根據你併發的執行緒數量決定,太多會導效能降低)
2. JDK8中的實現
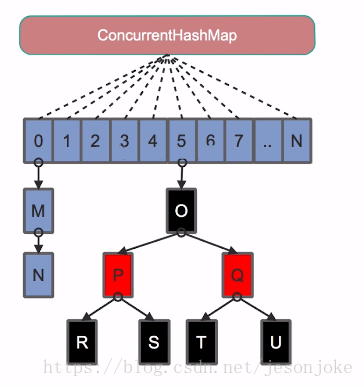
ConcurrentHashMap在JDK8中進行了巨大改動,很需要通過原始碼來再次學習下Doug Lea的實現方法。
它摒棄了Segment(鎖段)的概念,而是啟用了一種全新的方式實現,利用CAS演算法。它沿用了與它同時期的HashMap版本的思想,底層依然由“陣列”+連結串列+紅黑樹的方式思想(JDK7與JDK8中HashMap的實現),但是為了做到併發,又增加了很多輔助的類,例如TreeBin,Traverser等物件內部類。
總結
JDK6,7中的ConcurrentHashmap主要使用Segment來實現減小鎖粒度,把HashMap分割成若干個Segment,在put的時候需要鎖住Segment,get時候不加鎖,使用volatile來保證可見性,當要統計全域性時(比如size),首先會嘗試多次計算modcount來確定,這幾次嘗試中,是否有其他執行緒進行了修改操作,如果沒有,則直接返回size。如果有,則需要依次鎖住所有的Segment來計算。
jdk7中ConcurrentHashmap中,當長度過長碰撞會很頻繁,連結串列的增改刪查操作都會消耗很長的時間,影響效能,所以jdk8 中完全重寫了concurrentHashmap,程式碼量從原來的1000多行變成了 6000多 行,實現上也和原來的分段式儲存有很大的區別。
主要設計上的變化有以下幾點:
- 不採用segment而採用node,鎖住node來實現減小鎖粒度。
- 設計了MOVED狀態 當resize的中過程中 執行緒2還在put資料,執行緒2會幫助resize。
- 使用3個CAS操作來確保node的一些操作的原子性,這種方式代替了鎖。
- sizeCtl的不同值來代表不同含義,起到了控制的作用。
至於為什麼JDK8中使用synchronized而不是ReentrantLock,我猜是因為JDK8中對synchronized有了足夠的優化吧。
總結:
HashMap允許Key與Value為空,ConcurrentHashMap不允許
HashMap不允許通過迭代器遍歷的同時修改,ConcurrentHashMap允許。並且更新可見