
記一次jstack 處理堆疊溢位
jstack 應用
首先通過:ps -ef|grep java
得到java pid
檢視哪個執行緒佔用最多資源:
找出該程序內最耗費CPU的執行緒,可以使用ps -Lfp pid或者ps -mp pid -o THREAD, tid, time或者top -Hp pid 命令檢視這個程序下面的所有執行緒佔用情況。
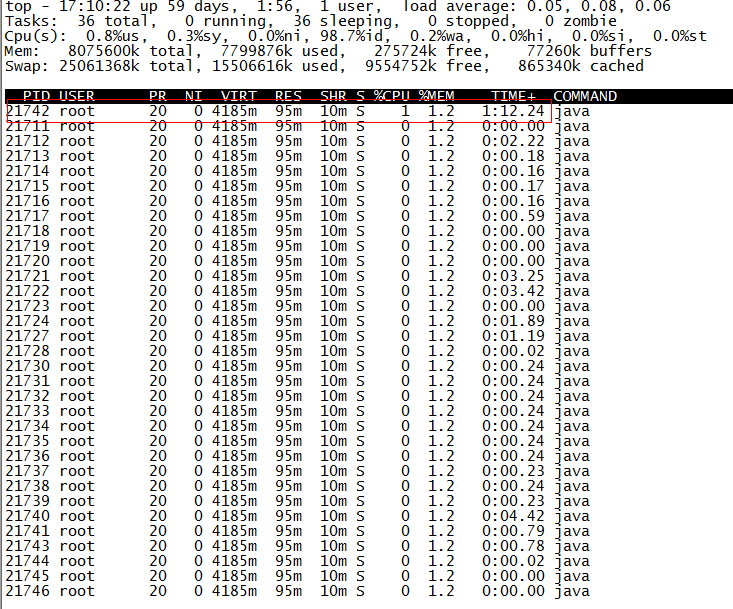
發現執行緒21742佔用最多。
將剛剛發現佔用cpu最多的執行緒id(21742)換算成16進位制
命令:printf "%x\n" 21742 的到 執行緒值 :54ee
檢視jstack 生成的檔案:
jstack pid | grep tid
如:jstack 21711 | grep 54ee
下面可以看出是哪行程式碼導致,檢視那行程式碼發現有死迴圈。跟蹤解決完畢。
例項:
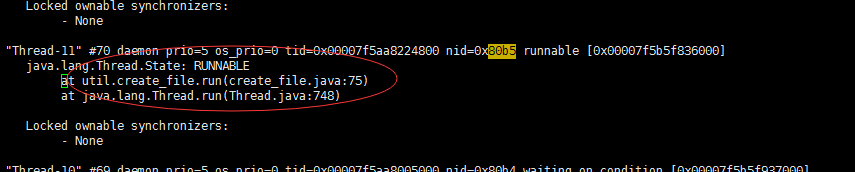
通過上面的步驟可以看出一個執行緒裡面的create_file.java的75行程式碼cpu和記憶體消耗嚴重。
 這個map是一個支援併發的map,裡面快取的資料太多導致一直變大。只要檢視map處理的程式碼就行了。
這個map是一個支援併發的map,裡面快取的資料太多導致一直變大。只要檢視map處理的程式碼就行了。
相關推薦
記一次jstack 處理堆疊溢位
jstack 應用 首先通過:ps -ef|grep java 得到java pid 檢視哪個執行緒佔用最多資源: 找出該程序內最耗費CPU的執行緒,可以使用ps -Lfp pid或者ps -mp pid -o THREAD, tid, time或者top -Hp pid &nb
記一次hive的記憶體溢位(OutOfMemoryError: Java heap space)排查
轉載請註明出處:http://blog.csdn.net/gklifg/article/details/50418109 剛剛從java組轉崗找資料組,學習大資料的知識,開發語言也從java轉到python新奇之外也遇到了諸多問題,其中最令我頭疼的就是在hive上的統計任務
開會時CPU 飆升100%同事們都手忙腳亂記一次應急處理過程
# 告警 正在開會,突然釘釘告警聲響個不停,同時市場人員反饋客戶在投訴系統登不進了,報504錯誤。檢視釘釘上的告警資訊,幾臺業務伺服器節點全部報CPU超過告警閾值,達100%。 趕緊從會上下來,SSH登入伺服器,使用 top 命令檢視,幾個Java程序CPU佔用達到180%,190%,這幾個Java程序對
記一次公司JVM堆溢位抽絲剝繭定位的過程
## 背景 公司線上有個tomcat服務,裡面合併部署了大概8個微服務,之所以沒有像其他微服務那樣單獨部署,其目的是為了節約伺服器資源,況且這8個服務是屬於邊緣服務,併發不高,就算宕機也不會影響核心業務。 因為併發不高,所以線上一共部署了2個tomcat進行負載均衡。 這個tomcat剛上生產線,執行挺
記一次jstack命令定位問題
今天天氣不錯,但是趕上惡意加班心情就不爽,懷著不爽的心情幹活,總能創造出更多的問題,這不,今天就自己挖了一個坑,自己跳進去了,好在上來了 經過是這樣的,開始除錯canal採集binlog時,由於添加了一個上報數量大小,隨手列印了一個日誌 logger.info("batchData:{}", batchDa
記一次服務器IO過高處理過程
linux 服務器 緩沖區 io負載 記一次服務器IO過高處理過程 一、背景 在一次上線升級後,發現兩臺tomcat服務器的IOwait一直超過100ms,高峰時甚至超過300ms,檢查服務器發現CPU負載,內存的使用率都不高。問題可能出現在硬盤讀寫,而且那塊硬盤除了寫日誌外,沒有其他
記一次database cpu high的處理
業務 read 需要 十分 時有 一次 -1 技術 ima 基本上,我們的數據庫實例每次cpu飆升都是因read而起,很少有write導致的cpu高。這說明read,隨機讀,排序,都會占用cpu。而寫入主要是io行為,尤其是順序寫,不需要占cpu。 今次問題,rds在三個小
記一次truncate導致的鎖表處理
需要 表現 cti 分析 慢查詢 ces sql 業務 復雜 一個不是很大的表,由數據分析部門生成並用於業務。由於代碼發了新版需要第一次運行,所以在業務低峰期讓數據部門執行了,邏輯是先truncate再insert重建。由於一直以來都沒問題,覺得不會出錯。結果過一會兒悲劇了
【troubleshooting】記一次Kafka集群重啟導致消息重復消費問題處理記錄
進程 pid 導致 set pic 方法 sum tails log 因需要重啟了Kafka集群,重啟後發現部分topic出現大量消息積壓,檢查consumer日誌,發現消費的數據竟然是幾天前的。由於平時topic消息基本上無積壓,consumer消費的數據都是最新的,明顯
記一次Ceph日誌損壞的分析處理過程
Ceph 日誌 1、故障現象 今天下午看到群友在說一個問題,說ceph的某個osd處於down的狀態,我大概整理下他的處理過程 1、查看OSD的狀態2、查看日誌信息3、啟動對應的ceph-osd服務4、檢查集群健康狀態 2、日誌損壞了,如何讓osd重新上線 思路:重建日誌a、先把/var/lib/ce
記一次http網站換成https的處理
tomcat nginx https今天對原來的網站做證書加密處理,就是http轉換成https。配置好nginx後發現網頁打開有部分頁面卻還是http協議,這樣將導致https網頁無法加載http的內容。嘗試了網上各種配置,都不行。最後的解決辦法是修改程序代碼。原來代碼:<c:set var=&quo
記一次網絡攻擊處理
table eth1 term iptable p地址 網絡 默認 oca 運行 Linux security 記網絡攻擊 首先需要確定是哪一張網卡的帶寬跑滿,可以通過sar -n DEV 1 5 命令來獲取網卡級別的流量圖,命令中 1 5 表示每一秒鐘取 1 次值,一共取
記一次測試環境Hbase數據備份恢復以及恢復後部分表無法刪除的問題處理
localhost mkdir folder max 一個表 任務 spa file config 一、Hbase數據備份恢復說明:因為測試環境要修改hadoop配置文件hdfs-site.xml的參數hdfs.rootdir修改前的配置 <property>
記一次OOM查詢處理過程
poi pri eve ctime oop spa 進行 無需 頻繁 記一次OOM查詢處理過程 問題的爆出及分析排查現場 排查後的解決方案 項目的jvm參數 總結 一、問題的爆出及分析排查現場 服務偶爾會出現不可用的情況,導致出現time o
記一次腦殘的故障處理-萬兆網卡驅動升級
問題解決 細節 更改 版本 題解 centos 6 重復 早已 地址 環境 centos 6.5 x64 83599ES 萬兆網卡 旁路流量送到萬兆網卡 升級萬兆網卡驅動 重復過一萬次的操作,一鍵搞定;這裏有一個小細節,intel官網驅動有版本升級,之前的地址不能用了,
記一次SQLSERVER2008R2資料庫查詢超時問題處理
資料庫環境: WINDOWS2008R2 SQLSERVER2008R2 應用程式環境: REDHAT6.5 TOMCAT JAVA 一、故障現象 某系統應用查詢超時 相關SQL: SELECT v.OBarcode Ba
記一次800多萬XML文字檔案預處理經歷
一.背景 由於某些需求,現需對系統在最近幾個月生成的xml檔案進行預處理,提取<text>標籤內的資料進行分析。這些需要預處理的資料大概有280GB左右880多萬,存放在gysl目錄下,gysl的下一層按天命名,分為若干個目錄,接下來一層目錄下又有多個目錄,我們所需的xml目錄就在這一層。我們現
記一次800多萬XML文本文件預處理經歷
超過 random while 表達式 range utf-8 test 現在 其他 一.背景 由於某些需求,現需對系統在最近幾個月生成的xml文件進行預處理,提取<text>標簽內的數據進行分析。這些需要預處理的數據大概有280GB左右880多萬,存放在gys
記一次使用crontab計劃任務執行python指令碼所遇問題及處理的過程
今天把一個python指令碼遷移到Centos7,用crontab執行,期間遇到很多錯誤,最終把所遇問題一一處理,感覺有必要把處理過程記錄下來 1、問題環境 Centos7 x64 python2.7 和python 3.5 有安裝virtualenvwrappe
記一次痛苦的編碼問題處理
上線前我們沒有關注 oracle的編碼,測試環境一直是chinese utf-8,而生產庫oracle叢集配置的是AMERICAN_AMERICA.AL32UTF8, 導致上線後系統新增資料到後臺變為亂碼,通過校驗 後臺處理邏輯為 iso8859-1的時候轉化gbk是正確