論文筆記:CNN經典結構2(WideResNet,FractalNet,DenseNet,ResNeXt,DPN,SENet)
阿新 • • 發佈:2018-12-11
###前言
本文承接之前的一篇[論文筆記:CNN經典結構1](https://www.cnblogs.com/liaohuiqiang/p/9606901.html)。前文主要講了2012-2015年的一些經典CNN結構,從AlexNet,ZFNet,OverFeat到VGG,GoogleNetv1-v4,ResNetv1-v2。
本文主要講解2016-2017年的一些經典CNN結構,WideResNet,FractalNet,DenseNet,ResNeXt,DPN,SENet。
###WideResNet( WRN )
1. **motivation**:ResNet的跳連線,導致了只有少量的殘差塊學到了有用資訊,或者大部分殘差塊只能提供少量的資訊。於是作者探索一種新的網路WideResNet(在ResNet的基礎上減小深度,增加寬度)。
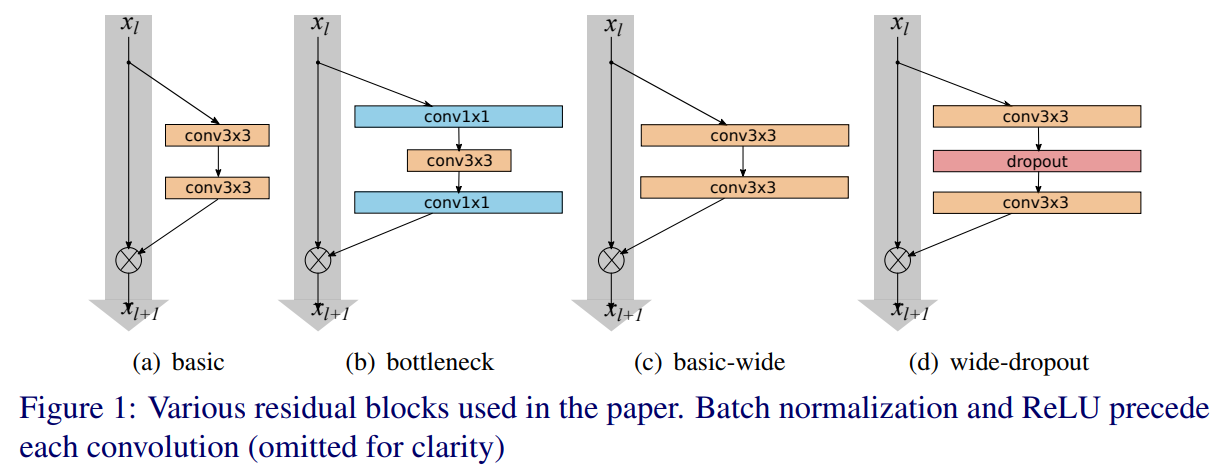
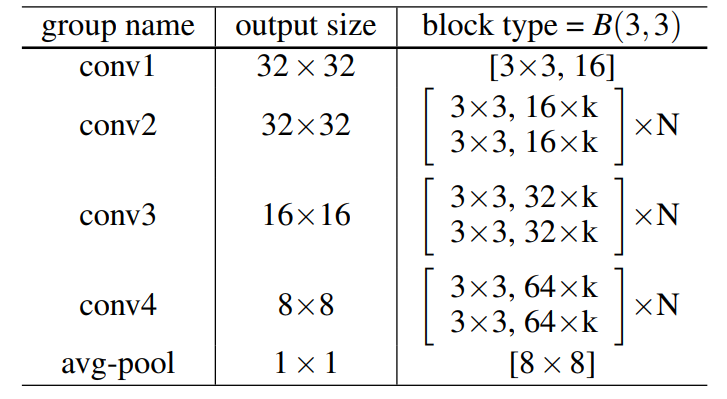
2. **網路結構**:在ResNetv2的基礎上改進,增大每個殘差塊中的卷積核數量。如下**兩個圖**所示。其中B(3,3)表示一個兩個3x3卷積,k表示一個寬度因子,當k為1時卷積核個數和ResNetv2相等,k越大網路越寬。另外WRN在卷積層之間加入dropout(下一個卷積層之前的bn和relu之後),如下第一個圖的圖(d)所示(在ResNetv2中把dropout放在恆等對映中實驗發現效果不好於是放棄了dropout)。用WRN-n-k來表示一個網路,n表示卷積層的總數,k表示寬度因子。
3. **訓練配置**:SGD,momentum為0.9,學習率為0.1,權重衰減為0.0005,batch size為128。
4. **實驗**:在CIFAR,SVHN,COCO資料集上取得了state-of-the-art的結果,同時在ImageNet上也表現優秀(比某些ResNet表現好,並沒有超越ResNet的最優結果)。作者根據實驗結果認為ResNet的主要能力來自於殘差塊,而深度的效果只是一個補充。
###FractalNet
1. **motivation**:WideResNet通過加寬ResNet得到state-of-the-art的表現,推測ResNet的主要能力來自於殘差塊,深度不是必要的。相比之下,分形網路則是直接認為ResNet中的殘差結構也不是必要的,網路的路徑長度(有效的梯度傳播路徑)才是訓練深度網路的基本組建。
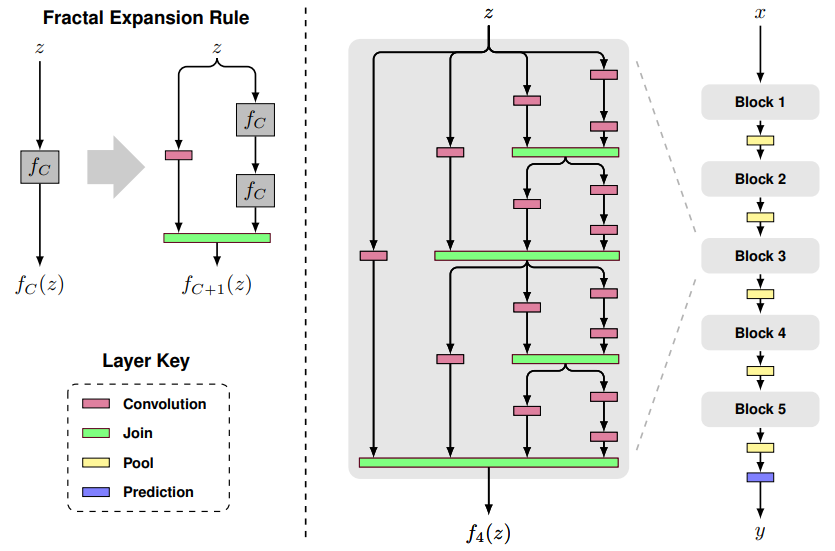
2. **網路結構**:如**下圖**所示,分形網路是通過不同長度的子路經組合,讓網路自身選擇合適的子路經集合,另外分形網路還提出了drop paht的方法。其中local drop就是join模組以一定概率drop每個輸入,但至少留下一個。global drop就是對整個網路只留下一列。
3. **實驗**:在CIFAR和SVHN資料集上分形網路取得了優秀的結果(CIFAR上可以超越殘差網路的表現,但是比WRN的表現差)。在ImageNet上可以達到和ResNet差不多的結果(好那麼一丟丟,但是隻對比了一種ResNet結構)。
4. **更多細節**:具體內容我在另一篇[論文筆記:分形網路](https://www.cnblogs.com/liaohuiqiang/p/9218445.html)中有所提及。
###DenseNet
1. **motivation之stochastic depth**:這是作者黃高之前的一篇論文,因為ResNet中大部分殘差塊只提供少量資訊,所以在ResNet基礎上隨機丟棄一些層,發現可以提高ResNet的泛化能力。隨機丟棄一些層網路依然奏效,帶來了兩點啟發,一是網路中的某一層可以不僅僅依賴於前層特徵而依賴於更前層的特徵。二是ResNet具有比較明顯的冗餘,網路的每一層只提取了很少的有用特徵。基於以上兩點DenseNet提出讓網路的每一層和前面的所有層相連,同時把每一層設計地特別窄,學習很少的特徵圖以此降低冗餘性。聽起來密集連線似乎會大大增加引數量,但實際上不是,因為網路變窄了。
2. **motivation之設計捷徑**:深層網路中,輸入的資訊或者梯度通過很多層之後會逐漸丟失,之前的ResNet和FractalNet的一個共同特徵在於,建立一個前層和後層捷徑。沿著這個思路DenseNet讓網路的所有層之間做一個全連線,保證所有層之間都兩兩連線,這麼做可以加強feature的傳遞,更有效地利用feature(每一層可以依賴更前層的特徵,每一層的特徵都直接連線到輸出層),減小梯度消失的問題。另外為了保留資訊在連線多個輸入時並沒有像ResNet一樣使用addition,而是使用concat。
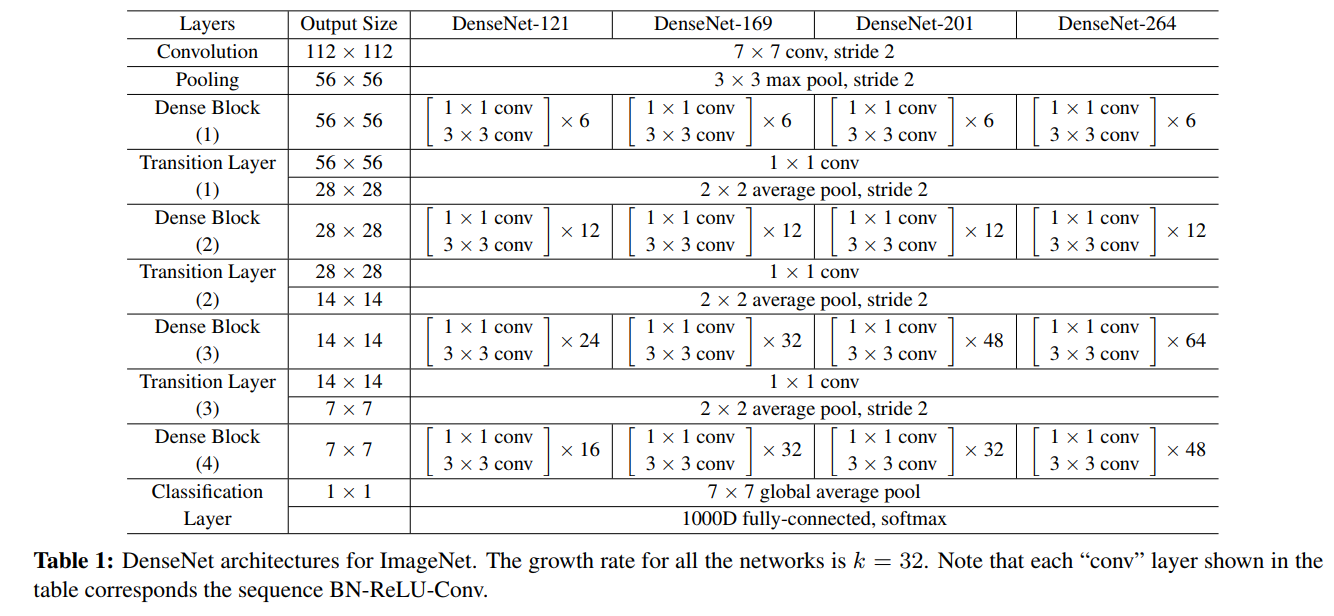
3. **DenseNet結構**:每一層都和所有前層相連線,第一層連輸入層有1個前連線,第二層就有2個前連線,那麼對於L層就有1+2+...+L也就是L(1+L)/2個連線。因為feature map大小不同的時候concat並不可行,DenseNet把網路分成了幾個Dense塊,中間用transition layer(用來改變feature map大小)連線起來。如下**第一個圖**所示。Dense塊中為多個“BN-ReLU-Conv3x3"(這一連串操作稱為一個$H_l$的單元操作)。DenseNet的具體結構見論文闡述。
4. **DenseNet-BC結構**:其中B表示bottleneck結構,把3x3替換成(1x1, 3x3),$H_l$單元操作為“BN-ReLU-Conv1x1-Conv3x3"。C表示壓縮,在transition層設一個引數$\theta$來減小feature map個數(通道數),論文中取值為0.5,每次transition時通道數減半。結構如下**第二個圖**所示,其中k表示Dense塊中$H_l$產生的feature map個數,k越小,Dense塊越窄,由於k越大會導致後層concat後通道越大,論文中也稱之為growth rate。進入Dense塊之前使用了2k個7x7卷積。實驗中1x1的卷積產生4k個feature map。
5. **實驗**:在CIFAR和SVHN上超越了前人的表現(超越WRN和FractalNet),在ImageNet上和ResNet達到差不多的表現但引數量不到一半,計算量為ResNet的一半。
6. **訓練配置**:SGD,權重衰減為0.0001,momentum為0.9。CIFAT和SVHN的batch size為64,學習率為0.1,50%和75%的epoch時除以10。在CIFAR上300個epoch,在SVHN上40個epoch。ImageNet上epoch為90,batch size為256,學習率為0.1,在30輪和60輪降為原來的1/10。原生的DenseNet實現對記憶體的利用效率不高(大量的concat會給視訊記憶體帶來高負荷),作者另外寫了一個技術報告來介紹如何提升DenseNet的記憶體使用效率,同時提供torch,pytorch,mxnet以及caffe的實現。
7. **網路表現比較**:根據幾篇論文的最優結果(忽略引數量不相同等因素),大體上看,CIFAR和SVHN上DenseNet優於WRN優於FractalNet。ImageNet上WRN優於DenseNet優於FractalNet。
8. **mark**:黃高還提出了一個多尺度DenseNet,主要思想是用淺層特徵來預測簡單圖片,深層特徵來預測較難的圖片,Multi-Scale Dense Convolutional Networks for Efficient Prediction這篇論文在這裡做個標記,有空的話好好拜讀一下。

###ResNeXt(2016年ImageNet分類任務的亞軍)
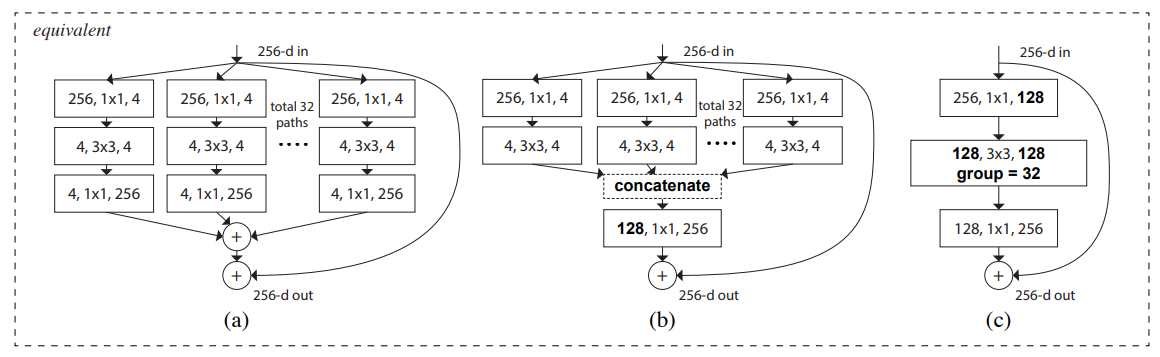
1. **motivation**:視覺識別的研究已經從“人工設計的特徵工程”轉移到“網路結構設計的網路工程”上。於是作者同時借鑑了VGG和ResNet的“堆疊相同shape子結構”思想和Inception的"split-transform-merge"思想,提出了ResNeXt的結構,把ResNet中殘差塊的結構改成如下**第一個圖**的圖右那種結構,類似Inception塊,但是裡面的每個小塊又是相同的結構,而且最後是addition而不是concat,通過堆疊這樣的ResNeXt塊來構建ResNeXt網路。
2. **網路結構**:如下**第二個圖**所示,三個子圖的結構是等價的,最後一個子圖用了組卷積技術使得結構更加緊湊簡潔,模型實現使用的是最後一個子圖的結構。BN-Relu的使用遵循的是原始的ResNetv1,在每個卷積後加BN-Relu,到block的輸出時(最後一個BN-Relu)把relu放在addition的後面。shortcut都用恆等對映,除了要用對映(projection)增維的時候。
3. **ImageNet預處理和預測**:預處理遵循VGG的做法來裁剪影象,所有消融學習中使用single-crop-224進行預測。
4. **ImageNet訓練配置**:SGD,batch size為256,權重衰減為0.0001,momentum為0.9,學習率為0.1,遵循ResNet的實現做三次除以10的衰減,何凱明初始化。
5. **實驗**:實驗表示,保持同樣的複雜度,增加“cardinality”(這個詞下圖中有解釋,相同於一個ResNeXt塊的分支數)可以提高準確率,另外,增加模型容量時,增加“cardinality”比增加深度或寬度更加有效。101-layer ResNeXt準確率比ResNet-200更高,同時花費一半的複雜度(Flops)。
6. **網路表現比較**:根據幾篇論文的最優結果(忽略引數量不相同等因素),大體上看,CIFAR上DenseNet優於ResNeXt優於WRN優於FractalNet。ImageNet上ResNeXt優於WRN優於DenseNet優於FractalNet。考慮到引數,網路的不同模型結構(比如DenseNet和DenseNet-BC)等因素,這個比較不是確切的,比如ResNeXt在CIFAR上是優於某些DenseNet只是差於某一個DenseNet-BC,具體資料回論文看。

###DPN(2017年ImageNet定位任務的冠軍)
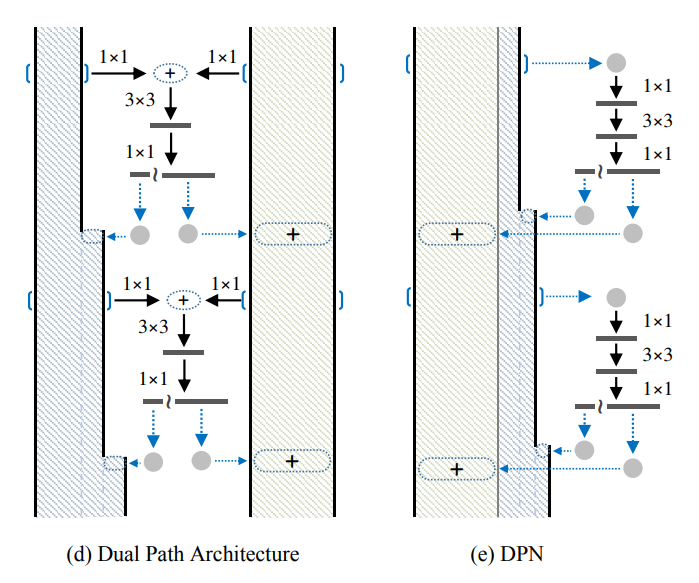
1. **motivation**:結合ResNet的優點(重用特徵)和DenseNet的優點(在重用特徵上存在冗餘,但是利於探索新特徵),提出一種新的網路結構,稱為對偶路徑網路(Dual Path Network)。
2. **網路結構**:如**下圖所示**,d和e等價,網路分為residual path和densely connected path在卷積塊最後的1x1將輸出切為兩路,一路連到residual path上加起來,一路練到densely connected path上concat起來。
3. **實驗**:ImageNet(分類)上表現超過ResNeXt,而且模型更小,計算複雜度更低。另外在VOC 2007的目標檢測結果和VOC 2012的語義分割結果也超越了DenseNet,ResNet和ResNeXt。
###SENet(2017年ImageNet分類任務的冠軍)
1. **motivation**:已經很多工作在空間維度上提升網路效能,比如Inception嵌入多尺度資訊,聚合多種不同感受野上的特徵來獲得性能增益。那麼網路是否可以從其它層面去提升效能,比如考慮特徵通道之間的關係,基於這一點作者提出了SENet(Squeeze-and-Excitation Network),通過學習的方式獲取每個通道的重要程度,從而進行特徵重標定。
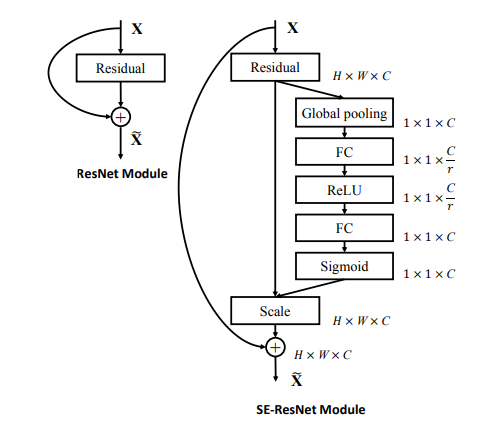
2. **網路結構**:如下**第一個圖**所示,$F_{tr}$表示transformation(比如一系列的卷積操作),$F_{sq}$表示squeeze操作,產生一個通道描述符,表徵特徵通道上響應的全域性分佈。$F_{ex}$表示excitation操作,通過引數w來為每個特徵通道生成權重,建模特徵通道間的重要性。$F_{scale}$表示一個reweight操作,將excitation輸出的權重(特徵通道的重要性)逐個乘到先前的特徵,完成特徵重標定。
3. **SE-ResNet模組**:如下**第二個圖**是SE嵌入到ResNet中的一個例子,這裡使用全域性均值池化作為squeeze操作,使用兩個FC組成的bottleneck結構作為excitation操作。SE可以嵌入到任意網路中得到不同種類的SENet,比如SE-ReNeXt,SE-BN-Inception,SE-Inception-ResNet-v2等等。
4. **訓練配置**:跟隨VGG的標準設定進行資料增強。輸入影象使用通道均值相減。使用了資料平衡策略用於mini-batch取樣(這個策略引用於另一篇論文Relay bp for effective learning of deep cnn)。SGD,momentum為0.9,mini-batch為1024,學習率0.6,每30輪除以10,訓練100輪,何凱明初始化。預測時使用center crop。
5. **實驗**:ImageNet分類中,在ResNet,ResNeXt,VGG,BN-Inception,Inception-ResNet-v2,mobileNet,shuffleNet上都做了實驗,發現加入SE後表現提升。此外還在場景分類和目標檢測中做了實驗,加入SE後表現提升。