
資料倉庫的詳細解析
資料倉庫的架構與設計
2017年04月01日 17:52:19 Trigl 閱讀數:377241. 什麼是資料倉庫
1.1 資料倉庫的概念
官方定義
資料倉庫是一個面向主題的、整合的、隨時間變化的、但資訊本身相對穩定的資料集合,用於對管理決策過程的支援。
這個定義的確官方,但是卻指出了資料倉庫的四個特點。
特點
面向主題:資料倉庫都是基於某個明確主題,僅需要與該主題相關的資料,其他的無關細節資料將被排除掉 整合的:從不同的資料來源採集資料到同一個資料來源,此過程會有一些ETL操作 隨時間變化:關鍵資料隱式或顯式的基於時間變化 資訊本身相對穩定:資料裝入以後一般只進行查詢操作,沒有傳統資料庫的增刪改操作
個人理解
資料倉庫就是整合多個數據源的歷史資料進行細粒度的、多維的分析,幫助高層管理者或者業務分析人員做出商業戰略決策或商業報表。
1.2 資料倉庫的用途
- 整合公司所有業務資料,建立統一的資料中心
- 產生業務報表,用於作出決策
- 為網站運營提供運營上的資料支援
- 可以作為各個業務的資料來源,形成業務資料互相反饋的良性迴圈
- 分析使用者行為資料,通過資料探勘來降低投入成本,提高投入效果
- 開發資料產品,直接或間接地為公司盈利
- …
1.3 資料庫和資料倉庫的區別
| 差異項 | 資料庫 | 資料倉庫 |
|---|---|---|
| 特徵 | 操作處理 | 資訊處理 |
| 面向 | 事務 | 分析 |
| 使用者 | DBA、開發 | 經理、主管、分析人員 |
| 功能 | 日常操作 | 長期資訊需求、決策支援 |
| DB設計 | 基於ER模型,面向應用 | 星形/雪花模型,面向主題 |
| 資料 | 當前的、最新的 | 歷史的、跨時間維護 |
| 彙總 | 原始的、高度詳細 | 彙總的、統一的 |
| 檢視 | 詳細、一般關係 | 彙總的、多維的 |
| 工作單元 | 短的、簡單事務 | 複雜查詢 |
| 訪問 | 讀/寫 | 大多為讀 |
| 關注 | 資料進入 | 資訊輸出 |
| 操作 | 主鍵索引操作 | 大量的磁碟掃描 |
| 使用者數 | 數百到數億 | 數百 |
| DB規模 | GB到TB | >= |
| 優先 | 高效能、高可用性 | 高靈活性 |
| 度量 | 事務吞吐量 | 查詢吞吐量、響應時間 |
2. 資料倉庫的架構
2.1 當前架構
當前我們的資料倉庫架構很low,但是能實現基本功能,如下:
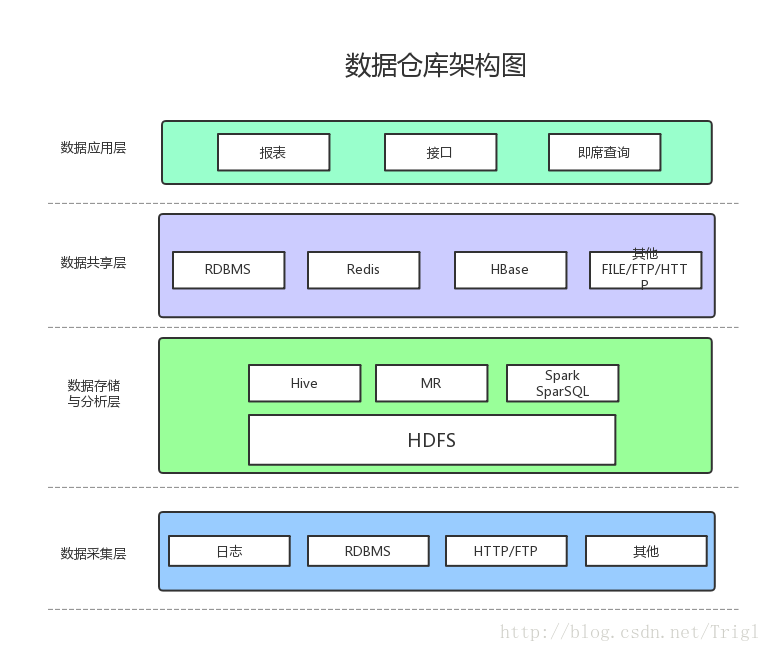
資料採集
資料採集層的任務就是把資料從各種資料來源中採集和儲存到資料儲存上,期間有可能會做一些ETL操作。
資料來源種類可以有多種:
- 日誌:所佔份額最大,儲存在備份伺服器上
- 業務資料庫:如Mysql、Oracle
- 來自HTTP/FTP的資料:合作伙伴提供的介面
- 其他資料來源:如Excel等需要手工錄入的資料
資料儲存與分析
HDFS是大資料環境下資料倉庫/資料平臺最完美的資料儲存解決方案。
離線資料分析與計算,也就是對實時性要求不高的部分,Hive是不錯的選擇。
使用Hadoop框架自然而然也提供了MapReduce介面,如果真的很樂意開發Java,或者對SQL不熟,那麼也可以使用MapReduce來做分析與計算。
Spark效能比MapReduce好很多,同時使用SparkSQL操作Hive。
資料共享
前面使用Hive、MR、Spark、SparkSQL分析和計算的結果,還是在HDFS上,但大多業務和應用不可能直接從HDFS上獲取資料,那麼就需要一個數據共享的地方,使得各業務和產品能方便的獲取資料。 這裡的資料共享,其實指的是前面資料分析與計算後的結果存放的地方,其實就是關係型資料庫和NOSQL資料庫。
資料應用
報表:報表所使用的資料,一般也是已經統計彙總好的,存放於資料共享層。
介面:介面的資料都是直接查詢資料共享層即可得到。
即席查詢:即席查詢通常是現有的報表和資料共享層的資料並不能滿足需求,需要從資料儲存層直接查詢。一般都是通過直接操作SQL得到。
2.2 理想架構
自己的架構這麼低階不能誤導了讀者,所以給出主流公司會用到的一個架構圖:
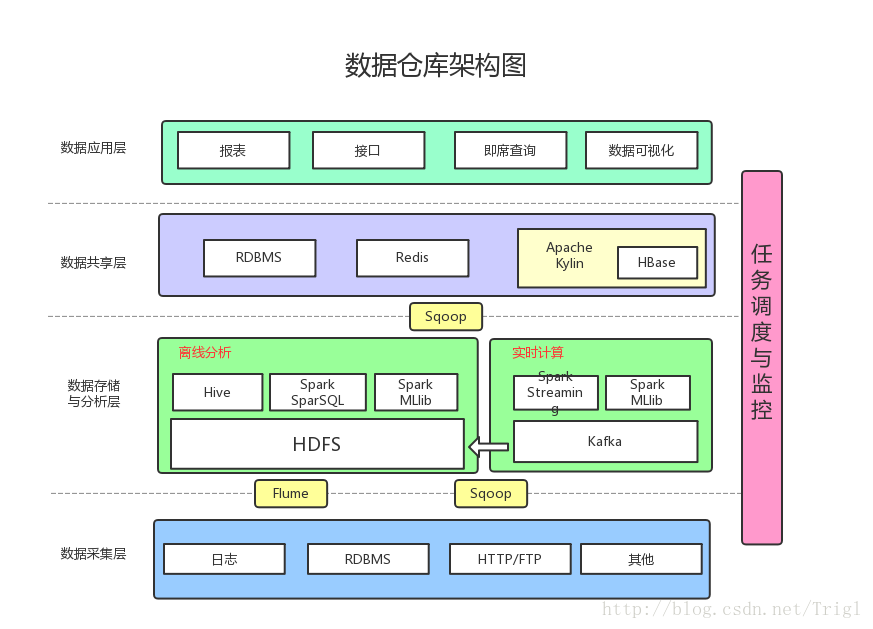
增加了以下內容:
資料採集:採用Flume收集日誌,採用Sqoop將RDBMS以及NoSQL中的資料同步到HDFS上
訊息系統:可以加入Kafka防止資料丟失
實時計算:實時計算使用Spark Streaming消費Kafka中收集的日誌資料,實時計算結果大多儲存在Redis中
機器學習:使用了Spark MLlib提供的機器學習演算法
多維分析OLAP:使用Kylin作為OLAP引擎
資料視覺化:提供視覺化前端頁面,方便運營等非開發人員直接查詢
3. 資料倉庫多維資料模型的設計
3.1 基本概念
主題(Subject)
主題就是指我們所要分析的具體方面。例如:某年某月某地區某機型某款App的安裝情況。主題有兩個元素:一是各個分析角度(維度),如時間位置;二是要分析的具體量度,該量度一般通過數值體現,如App安裝量。
維(Dimension)
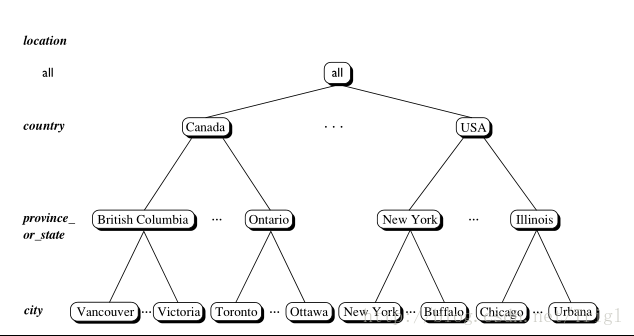
維是用於從不同角度描述事物特徵的,一般維都會有多層(Level:級別),每個Level都會包含一些共有的或特有的屬性(Attribute),可以用下圖來展示下維的結構和組成:
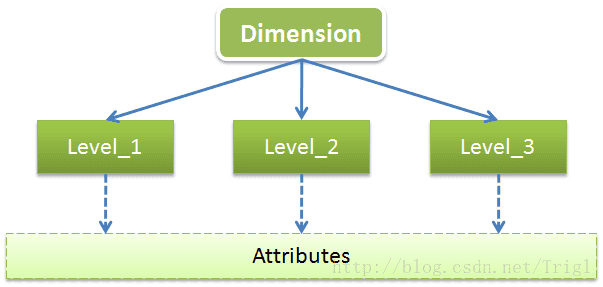
以時間維為例,時間維一般會包含年、季、月、日這幾個Level,每個Level一般都會有ID、NAME、DESCRIPTION這幾個公共屬性,這幾個公共屬性不僅適用於時間維,也同樣表現在其它各種不同型別的維。
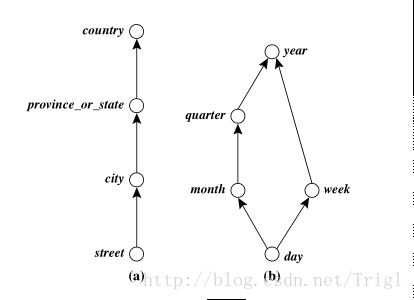
分層(Hierarchy)
OLAP需要基於有層級的自上而下的鑽取,或者自下而上地聚合。所以我們一般會在維的基礎上再次進行分層,維、分層、層級的關係如下圖:
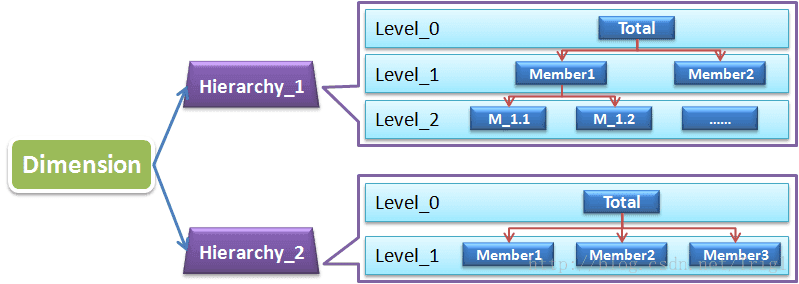
每一級之間可能是附屬關係(如市屬於省、省屬於國家),也可能是順序關係(如天週年),如下圖所示:
量度
量度就是我們要分析的具體的技術指標,諸如年銷售額之類。它們一般為數值型資料。我們或者將該資料彙總,或者將該資料取次數、獨立次數或取最大最小值等,這樣的資料稱為量度。
粒度 資料的細分層度,例如按天分按小時分。
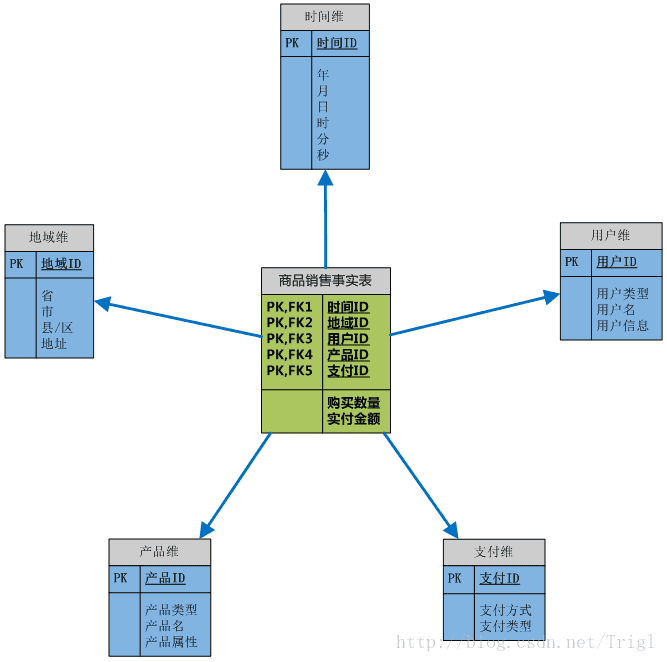
事實表和維表
事實表是用來記錄分析的內容的全量資訊的,包含了每個事件的具體要素,以及具體發生的事情。事實表中儲存數字型ID以及度量資訊。
維表則是對事實表中事件的要素的描述資訊,就是你觀察該事務的角度,是從哪個角度去觀察這個內容的。
事實表和維表通過ID相關聯,如圖所示:
星形/雪花形/事實星座
這三者就是資料倉庫多維資料模型建模的模式
上圖所示就是一個標準的星形模型。
雪花形就是在維度下面又細分出維度,這樣切分是為了使表結構更加規範化。雪花模式可以減少冗餘,但是減少的那點空間和事實表的容量相比實在是微不足道,而且多個表聯結操作會降低效能,所以一般不用雪花模式設計資料倉庫。
事實星座模式就是星形模式的集合,包含星形模式,也就包含多個事實表。
企業級資料倉庫/資料集市
企業級資料倉庫:突出大而全,不論是細緻資料和聚合資料它全都有,設計時使用事實星座模式
資料集市:可以看做是企業級資料倉庫的一個子集,它是針對某一方面的資料設計的資料倉庫,例如為公司的支付業務設計一個單獨的資料集市。由於資料集市沒有進行企業級的設計和規劃,所以長期來看,它本身的整合將會極其複雜。其資料來源有兩種,一種是直接從原生資料來源得到,另一種是從企業資料倉庫得到。設計時使用星形模型
3.2 資料倉庫設計步驟
1、確定主題
主題與業務密切相關,所以設計數倉之前應當充分了解業務有哪些方面的需求,據此確定主題
2、確定量度
在確定了主題以後,我們將考慮要分析的技術指標,諸如年銷售額之類。量度是要統計的指標,必須事先選 擇恰當,基於不同的量度將直接產生不同的決策結果。
3、確定資料粒度
考慮到量度的聚合程度不同,我們將採用“最小粒度原則”,即將量度的粒度設定到最小。例如如果知道某些資料細分到天就好了,那麼設定其粒度到天;但是如果不確定的話,就將粒度設定為最小,即毫秒級別的。
4、確定維度
設計各個維度的主鍵、層次、層級,儘量減少冗餘。
5、建立事實表
事實表中將存在維度代理鍵和各量度,而不應該存在描述性資訊,即符合“瘦高原則”,即要求事實表資料條數儘量多(粒度最小),而描述性資訊儘量少。
Refer
閱讀更多