
Spark中的Join型別
常規連線:

左半連線:

左半連線結果集:僅僅保留右邊表中的行,這些行的joinkey出現在右邊表中!!!(類似於leftTable.joinKey in (rightTable.joinKeys)).這種join是會出重的,當左邊表join到一個之後便返回不在繼續join。
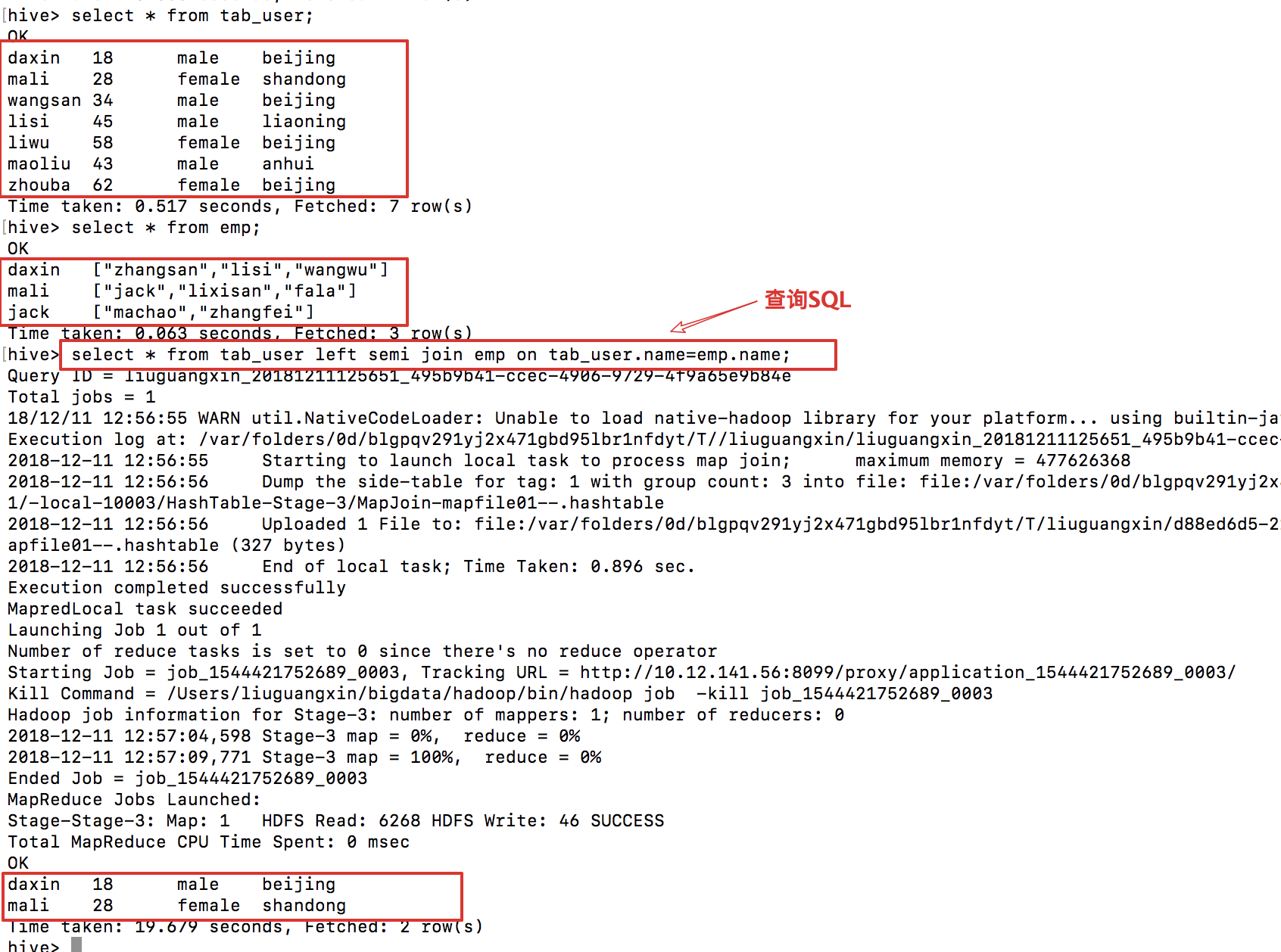
左反連線:

結果集是:joinKey不在右表之中!
相關推薦
spark中join的簡單操作
(1)RDD之間的join import org.apache.spark.sql.SparkSession object joinDemo { //BroadcastHashJoin def main(args: Array[String]): Unit = { val
Spark中的Join型別
常規連線: 左半連線: 左半連線結果集:僅僅保留右邊表中的行,這些行的joinkey出現在右邊表中!!!(類似於leftTable.joinKey in (rightTable.joinKeys)).這種join是會出重的,當左邊表join到一個之後便返回不在繼續join。
Spark DataFrame中的join型別
Spark DataFrame中join與SQL很像,都有inner join, left join, right join, full join; 那麼join方法如何實現不同的join型別呢? 看其原型 def join(right : DataFra
Spark中的3中Join
Broadcast Join 大家知道,在資料庫的常見模型中(比如星型模型或者雪花模型),表一般分為兩種:事實表和維度表。維度表一般指固定的、變動較少的表,例如聯絡人、物品種類等,一般資料有限。而事實表一般記錄流水,比如銷售清單等,通常隨著時間的增長不斷膨脹。
資料基礎---spark中的資料型別
mllib中的資料型別 本文是對官方文件的翻譯整理 1、資料型別 Local vector(本地向量) Labeled point(帶標籤資料點) Local matrix(本地矩陣) Distrubuted matrix(分散式矩陣):RowM
Spark中常見join操作
spark中的連線操作 (1)join 如果熟悉sql的同學應該很熟悉join,這裡的join和sql中的inner join操作很相似,返回結果是前面一個集合和後面一個集合中匹配成功的,過濾掉關聯不上的。 def join[W](other: RDD
spark讀取elasticsearch中陣列型別的欄位
之前做的一個專案需要用sparksql讀取elasticsearch的資料,當讀取的型別中包含陣列時報錯. 讀取方式大概是 val options = Map("pushdown" -> "true", "strict" -> "false", "
Spark 中關於Parquet的應用與性能初步測試
spark 大數據 hadoop hive parquetSpark 中關於Parquet的應用Parquet簡介 Parquet是面向分析型業務的列式存儲格式,由Twitter和Cloudera合作開發,2015年5月從Apache的孵化器裏畢業成為Apache頂級項目http://parquet.apa
Spark中經常使用工具類Utils的簡明介紹
run max news register 令行 刪除 exist bstr chan 《深入理解Spark:核心思想與源代碼分析》一書前言的內容請看鏈接《深入理解SPARK:核心思想與源代碼分析》一書正式出版上市 《深入理解Spark:核心思想與源代碼分析》
【轉載】Spark學習——spark中的幾個概念的理解及參數配置
program submit man 聯眾 tail 進行 orb 數據源 work 首先是一張Spark的部署圖: 節點類型有: 1. master 節點: 常駐master進程,負責管理全部worker節點。2. worker 節點: 常駐worker進程,負責管理
Microsoft dynamic sdk中join應該註意的問題.
per order 問題 bean lec note exp amp collect QueryExpression queryNextSeq = new QueryExpression { EntityName =
spark中的scalaAPI之RDDAPI常用操作
appname 轉換 成了 size pre esc atm rgs new package com.XXX import org.apache.spark.storage.StorageLevel import org.apache.spark.{SparkConf,
spark中flatMap函數用法--spark學習(基礎)
比較 一次 ica 例子 tail details word fix spark spark中flatMap函數用法--spark學習(基礎) 在spark中map函數和flatMap函數是兩個比較常用的函數。其中 map:對集合中每個元素進行操作。 fl
Spark中使用Java編程的常用方法
廣播 新的 json lambda表達式 aslist rom collect spl nal 原文引自:http://blog.sina.com.cn/s/blog_628cc2b70102w9up.html 一、初始化SparkContext System.setPr
Spark中groupBy groupByKey reduceByKey的區別
分享 red htm key-value com length .html () str groupBy 和SQL中groupby一樣,只是後面必須結合聚合函數使用才可以。 例如: hour.filter($"version".isin(version:
【Spark篇】---Spark中Transformations轉換算子
pack gpo rds color boolean long als sam park 一、前述 Spark中默認有兩大類算子,Transformation(轉換算子),懶執行。action算子,立即執行,有一個action算子 ,就有一個job。 通俗些來說由RDD變成
python3多線程應用詳解(第三卷:圖解多線程中join,守護線程應用)
圖解 pytho inf bubuko post 圖片 clas info blog python3多線程應用詳解(第三卷:圖解多線程中join,守護線程應用)
【Spark】篇---Spark中yarn模式兩種提交任務方式
方式 div -s and clas client 命令 yarn 模式 一、前述 Spark可以和Yarn整合,將Application提交到Yarn上運行,和StandAlone提交模式一樣,Yarn也有兩種提交任務的方式。 二、具體 1、yarn
【Spark篇】---Spark中資源調度源碼分析與應用
部分 app post 類名 inf master 執行過程 efault spark 一、前述 Spark中資源調度是一個非常核心的模塊,尤其對於我們提交參數來說,需要具體到某些配置,所以提交配置的參數於源碼一一對應,掌握此節對於Spark在任務執行過程中的資源分配會更上
python threading queue模塊中join setDaemon及task_done的使用方法及示例
獨立 pro span put 安全 with 錯誤信息 strong 消費 threading: t.setDaemon(True) 將線程設置成守護線程,主進行結束後,此線程也會被強制結束。如果線程沒有設置此值,則主線程執行完畢後還會等待此線程執行。