Java底層之HashMap底層實現原理
HashMap簡介
HashMap 是一個散列表,它儲存的內容是鍵值對(key-value)對映。 HashMap 繼承於AbstractMap,實現了Map、Cloneable、java.io.Serializable介面。 HashMap 的實現不是同步的,這意味著它不是執行緒安全的。它的key、value都可以為null。此外,HashMap中的對映不是有序的。 HashMap 的例項有兩個引數影響其效能:“初始容量” 和 “載入因子”。容量 是雜湊表中桶的數量,初始容量只是雜湊表在建立時的容量,大小為16。載入因子 是雜湊表在其容量自動增加之前可以達到多滿的一種尺度,大小為0.75。當雜湊表中的條目數超出了載入因子與當前容量的乘積時,則要對該雜湊表進行 rehash 操作(即重建內部資料結構),從而雜湊表將具有大約兩倍的桶數。
原始碼解析
HashMap底層使用EMPTY_TABLE陣列來儲存key/value
//HashMap使用Entry型別的陣列儲存
static final Entry<?,?>[] EMPTY_TABLE = {};
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;Entry類結構,當存在hash衝突時,entry的next變數指向衝突連結串列的下一entry
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; //指向連結串列的下一個entry節點 int hash; //此entry的hash值 Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; } public final K getKey() { return key; } public final V getValue() { return value; } //修改當前entry的value,返回舊的value public final V setValue(V newValue) { V oldValue = value; value = newValue; return oldValue; } //判斷兩個entry是否相等 public final boolean equals(Object o) { if (!(o instanceof Map.Entry)) return false; Map.Entry e = (Map.Entry)o; Object k1 = getKey(); Object k2 = e.getKey(); //比較key if (k1 == k2 || (k1 != null && k1.equals(k2))) { Object v1 = getValue(); Object v2 = e.getValue(); //比較value if (v1 == v2 || (v1 != null && v1.equals(v2))) return true; } return false; } //計算hash值--key和value的hash值的二進位制異或作為entry的hash值 public final int hashCode() { return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue()); } public final String toString() { return getKey() + "=" + getValue(); } void recordAccess(HashMap<K,V> m) { } void recordRemoval(HashMap<K,V> m) { } }
1. 當建立一個HashMap物件時,初始化一個存放Entry的陣列,大小為16;
//陣列容量的初始大小為16,1左移4位 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //陣列的最大容量為1073741824 static final int MAXIMUM_CAPACITY = 1 << 30; //載入因子為0.75,當陣列容量*載入因子小於Entry的個數(size)時,擴大陣列的容量為當前陣列大小的兩倍,全部entry重新進行Hash值計算進行雜湊 static final float DEFAULT_LOAD_FACTOR = 0.75f; //當前HashMap儲存的entry個數 transient int size;
2. put方法及其呼叫方法
(1)put方法
//put方法
public V put(K key, V value) {
//此處相當於懶載入,當陣列未建立時,進行陣列的初始化,大小為16
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//當key為null時,放在陣列的第一位,即Table[0]
if (key == null)
return putForNullKey(value);
//根據key計算hash值
int hash = hash(key);
//根據hash值和陣列的長度計算entry需要放置的陣列下標,方法見(2)
int i = indexFor(hash, table.length);
//迴圈遍歷當前位置的連結串列,如果存在key相同的,則用新的value替換掉舊的value
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
//修改次數增加,用於執行緒安全判定
modCount++;
//增加元素,方法見(3)
addEntry(hash, key, value, i);
return null;
}(2)indexFor 方法,計算存放的下標
/**
* @param h Hash值
* @param length HashMap底層陣列長度
* index的計算方式為二進位制&運算,因為陣列的下標為0-15,所以用length-1進行運算;
* 其次length的數值為16為基礎,逐次2倍擴大。以16為例,二進位制為10000,當10000與其它數字進行與運算時,產生的值只有0或者16,會產生大量的Hash衝突;當採用15時,1111和其它數值&計算結果會分佈較為均勻。
*/
static int indexFor(int h, int length) {
return h & (length-1);
}(3)addEntry:增加元素,判斷是否需要擴容
/**
* @param hash 經過key計算出來的hash
* @param key 插入的元素的key
* @param value 插入元素的value
* @param bucketIndex 插入陣列的下標
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
// threshold = capacity * loadFactor,即陣列長度 * 載入因子(0.75),作為閾值
if ((size >= threshold) && (null != table[bucketIndex])) {
//達到閾值,陣列擴容為原來的2倍,方法見(4)
resize(2 * table.length);
//因為陣列改變,重新進行計算hash值和陣列索引
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
//沒有達到閾值,增加元素, 方法見(5)
createEntry(hash, key, value, bucketIndex);
}(4)resize 方法:擴容,重新生成陣列進行所有元素的雜湊
/**
* @param newCapacity 新陣列的大小
*/
void resize(int newCapacity) {
//取到原陣列
Entry[] oldTable = table;
//原陣列長度
int oldCapacity = oldTable.length;
//最大長度
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//建立一個新陣列,長度為原陣列的2倍
Entry[] newTable = new Entry[newCapacity];
//所有元素進行hash值和陣列索引的計算,重新雜湊
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
//重新計算閾值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}(5)createEntry 方法:新增元素,並解決hash衝突
/**
* @param hash 經過key計算出來的hash
* @param key 插入的元素的key
* @param value 插入元素的value
* @param bucketIndex 插入陣列的下標
* 插入元素,並解決hash衝突
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
//如果當前節點存在其它元素,則發生hash衝突,由新插入的元素頂掉原位置的元素,新元素的next指向被頂掉的舊元素,即新元素是從連結串列頭部插入,e為連結串列的頭元素
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
//元素個數增加
size++;
}3. get方法及其呼叫方法
(1)get方法
/**
* @param key 要獲取元素的key
*/
public V get(Object key) {
//如果key為null,從儲存key=null的位置獲取元素,方法見(2)
if (key == null)
return getForNullKey();
//獲取key,方法見(3)
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}(2)getForNullKey 方法:由put方法可知,key=null的元素都放在陣列下標為0的位置
private V getForNullKey() {
//如果HashMap沒有儲存元素,返回null
if (size == 0) {
return null;
}
//取到陣列下標為0的連結串列,遍歷獲取key為null元素返回
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}(3)getEntry 方法
final Entry<K, V> getEntry(Object key) {
//如果HashMap沒有儲存元素,返回null
if (size == 0) {
return null;
}
//計算key的hash值
int hash = (key == null) ? 0 : hash(key);
//通過key的hash值,計算陣列儲存的下標,迴圈遍歷下標位置儲存的連結串列,返回key相等的元素
for (Entry<K, V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) {
return e;
}
}
return null;
}4. 關於jdk1.7與1.8 HashMap的差異
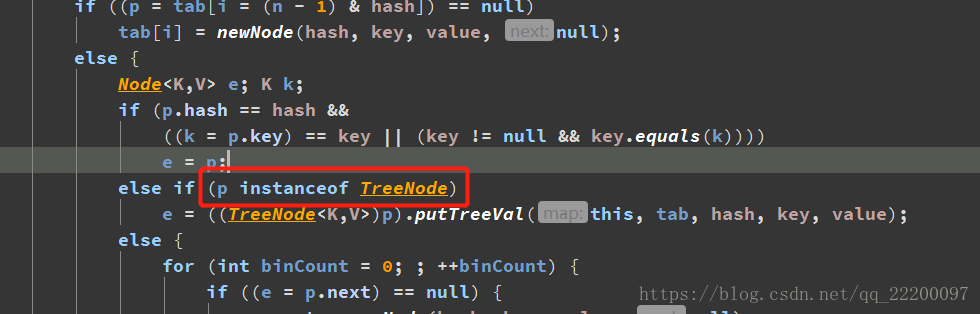
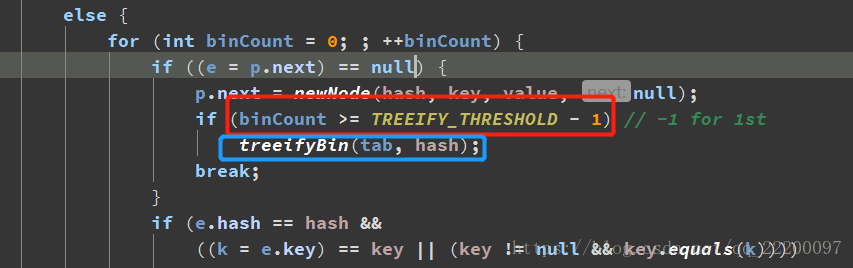
由上所見,1.7解決hash衝突採用的是連結串列結構,而到了1.8,原始碼如下所示,插入元素時,首先判斷插入的是否是樹型別,如果不是,則判斷衝突位置處的連結串列長度是否達到閾值(TREEIFY_THRESHOLD = 8),即連結串列長度達到8時,連結串列轉為紅黑樹儲存,未達到8時,則依舊採用連結串列結構。