
YOLO更新的相關記錄(YOLOv3)
前言:
{
}
正文:
{
第二節中提到了相關改變。
當與標籤框非最佳匹配的框先驗(box prior)的預測與標籤框的覆蓋沒有超過一個閾值時,此預測只參與目標性得分的損失計算(即其目標性為0);並且當與標籤框非最佳匹配的框先驗的預測與標籤框的覆蓋超過一個閾值時,此預測不參與損失計算。即下式的最後一行被改變了,現在的標籤目標性只有0和1。
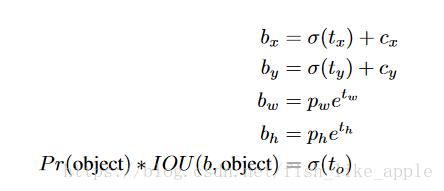
其中b為標準框的各種屬性,t為網路輸出的各種框屬性,p為框先驗的屬性,即anchor box的高和寬,並且σ()為修正函式。
取消了類預測的softmax,現在每個框可以屬於多個類了(用閾值來判定類?文章這裡沒說明。)。
使用了一種類似金字塔結構的結構,對最終特徵圖和前面某2層的經過上取樣的特徵圖進行concate,以形成新的特徵圖,之後又加了幾層卷積層,因此得到新的最終特徵圖。(這裡有點不明白,文章上說對最終尺度還有額外的設計,但是所有尺度的預測不都是在一起的嗎?)
特徵提取網路變成了Darknet-53,如表1。
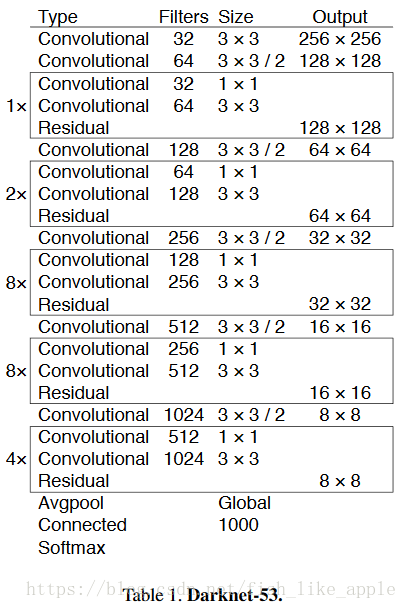
新特徵提取網路更深,也使用了殘差單元。此特徵提取網路與其他特徵提取網路的比較如表2。
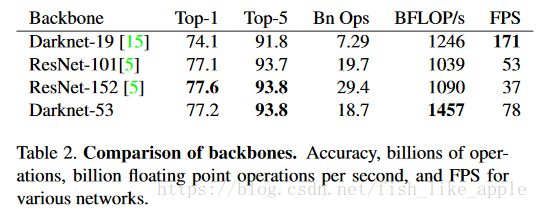
可見在保證效果的情況下,新特徵提取網路也達到了較快的速度。
第三節說了YOLOv3的一些問題:1,不能很精確地定位,因為提高上述閾值會顯著降低效果;2,之前是檢測小目標有問題,現在是檢測較大目標有問題,因為使用了類金字塔結構。
第四節提到了行不通的方法,有2個方面,1是輸出的表示方式,2是損失函式。看樣子輸出的表示方式也是很重要的(尤其是選擇線性形式還是對數形式)。
最後附上橫向比較結果,見表3。
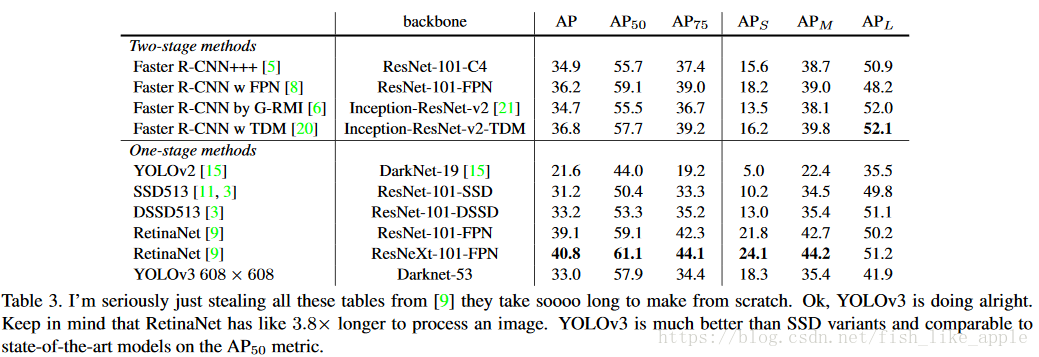
}
結語:
{
從表3可以看出,效果最好的目標檢測結構是RetinaNet,如果不考慮速度的話,RetinaNet更值得考慮。
這篇文章的風格很隨意,也很簡潔,有耳目一新的感覺。
很多都是個人理解,如有不當歡迎指出。
}