
# cs231n (三)優化問題及方法
cs231n (三)優化問題及方法
標籤(空格分隔): 神經網路
0.回顧
cs231n (一)影象分類識別講了KNN
cs231n (二)講了線性分類器:SVM和SoftMax
回顧上次的內容,其實就會發現,雖然我們構造好了損失函式,可以簡單使用導數的定義解決損失函式優化問題,但是並不高效啊,現在探索一下唄。
1.引言
之前(二部分),我們介紹了影象分類任務中的兩個關鍵部分
- 評分函式----> 原始影象畫素直接對映為評分值:線性函式
- 損失函式----> 根據分類評分和實際視覺分類差別衡量那個權重矩陣的好壞:SoftMax,SVM.
線性函式的形式是
SVM實現的公式是:
L 越小,說明這個權重矩陣W越好唄,那麼什麼時候最小?
很聰明嘛!我們這次講的就是最優化問題, 這裡可真是大(shu)學問。
2. 損失函式是什麼東東?
這裡討論的是高維空間重中的:
大聲告訴我:CIFAR-10的線性分類權重矩陣大小是多啊?
10x3073唄 (Class X Dimension)另加了一個1.
我能不能看到啊?
比較困難,但我們可以:在1個維度或者2個維度的方向上對高維空間進行分割
-
例如,隨機生成一個權重矩陣W,該矩陣就與高維空間中的一個點對應
然後沿著某個維度方向前進----> 同時記錄損失函式值的變化。 -
生成一個隨機的方向 並且沿著此方向計算損失值,計算方法是根據不同的a 值來計算。
這個過程將生成一個圖表,其x軸是a值,y軸是損失函式值。同樣的方法還可以用在兩個維度上,通過改變a,b來計算損失值 ,從而給出二維的影象。在影象中,a,b可以分別用x和y軸表示,而損失函式的值可以用顏色變化表示:
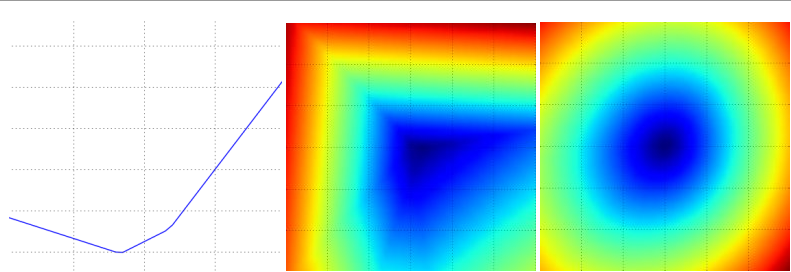
一個無正則化的SVM的損失函式就是看上面,左中分別有一個數據,右是10個
左:a值漸變時,及某個維度方向上對應的的損失值變化
中右:藍色部分是低損失值區域,紅色部分是高損失值區域
對於一個影象資料,損失函式的計算公式如下:
假設有一個簡單的資料集,其中包含有3個只有1個維度的點,資料集資料點有3個類別。那麼完整的無正則化SVM的損失值計算如下:
對於一維資料,和權重都是數字,從,可以看到上面的式子中一些項是的線性函式,且每一項都會與0比較,取兩者的最大值。
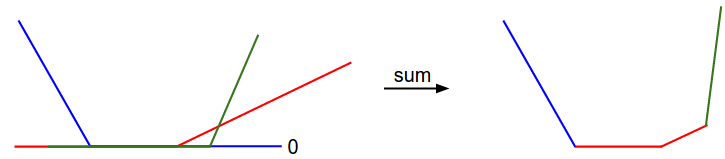
那麼:x軸方向就是一個權重,y軸就是損失值
每個部分 1.是某個權重的獨立部分,2.是該權重的線性函式與0閾值的比較。完整的SVM資料損失就是這個形狀的30730維版本(3073*10).
對:就是凸函式 ,人家還出了課程:最優化凸函式
由於max,則SVM函式產生不可導的點,那麼這個損失函式不可微,所以梯度沒有意義,這裡用到了次梯度。
3. 最優化
失函式可以量化某個具體權重集W的質量,最優化的目標:到能夠最小化損失函式值的W
辦法1:隨機搜尋(不好)
隨機嘗試很多不同的權重,然後看其中哪個最好,就是瞎蒙唄,你想想能好麼?
# X_train的每一列都是一個數據樣本(3073 x 50000的陣列)
# Y_train是資料樣本的類別標籤(1x50000的陣列)
# 函式L即損失函式
bestloss = float("inf") # Python assigns the highest possible float value
for num in xrange(1000):
W = np.random.randn(10, 3073) * 0.0001 # generate random parameters
loss = L(X_train, Y_train, W) # get the loss over the entire training set
if loss < bestloss: # keep track of the best solution
bestloss = loss
bestW = W
print 'in attempt %d the loss was %f, best %f' % (num, loss, bestloss)
# in attempt 0 the loss was 9.401632, best 9.401632
# in attempt 1 the loss was 8.959668, best 8.959668
# in attempt 2 the loss was 9.044034, best 8.959668
# in attempt 3 the loss was 9.278948, best 8.959668
# in attempt 4 the loss was 8.857370, best 8.857370
# in attempt 5 the loss was 8.943151, best 8.857370
# in attempt 6 the loss was 8.605604, best 8.605604
# ... (trunctated: continues for 1000 lines)
結果可想而知,L是有大有小,不管怎麼樣,先用測試集試試
# Assume X_test is [3073 x 10000], Y_test [10000 x 1]
scores = Wbest.dot(Xte_cols) # 10 x 10000, the class scores for all test examples
# find the index with max score in each column (the predicted class)
Yte_predict = np.argmax(scores, axis = 0)
# and calculate accuracy (fraction of predictions that are correct)
np.mean(Yte_predict == Yte)
# returns 0.1555
表現最好的權重W跑測試集的準確率是15.5%,瞎蒙就是10%,好學生!
關鍵思路:迭代優化: 從一個隨機的W開始,然後迭代,每次都讓它的損失值變得更小一點, 還是在嘗試。
矇眼山林獵人:蒙著眼睛回家(山底), 那就滾唄,哈哈。
辦法2:隨機本地試探
還是蒙著眼睛,超每個方向都試一下,如果感覺自己下降了,那就走那個方向啦。
看專家怎麼說的:隨機的擾動$\delta W W+\delta$ W的損失值變低,我們才會更新損失。
嗯,大家都是凡人。
W = np.random.randn(10, 3073) * 0.001 # 隨機 初始值:W
bestloss = float("inf")
for i in xrange(1000):
step_size = 0.0001
Wtry = W + np.random.randn(10, 3073) * step_size
loss = L(Xtr_cols, Ytr, Wtry)
if loss < bestloss:
W = Wtry
bestloss = loss
print 'iter %d loss is %f' % (i, bestloss)
這個方法得到21.4%的分類準確率。這個比策略一好,但是依然過於浪費計算資源,但是累還耗時。
方法3:跟隨梯度—>望眼欲穿法
這次是睜開眼睛,你就往下看啊,越陡你下山越快,回家越快啊,小心別掉坑裡啊。
數學專家:從數學上計算出最陡峭的方向。這個方向就是損失函式的梯度(gradient),這個方法就好比是感受我們腳下山體的傾斜程度,然後向著最陡峭的下降方向下山。
在一維函式中,斜率是函式在某一點的瞬時變化率. 梯度是函式的斜率的一般化表達,它不是一個值,而是一個向量。在輸入空間中,梯度是各個維度的斜率組成的向量(或者稱為導數derivatives)。對一維函式的求導公式如下:
當函式有多個引數的時候,我們稱導數為偏導數。而梯度就是在每個維度上偏導數所形成的向量,多個引數的時候,我們稱導數為偏導數.(我就叫它偏頭痛)。哼~~~
4. 梯度計算
算梯度有兩種方法:一個是緩慢的近似方法(數值梯度法),但實現相對簡單。另一個方法(分析梯度法)計算迅速且精確,但是確實容易出錯,且需要使用微分。
大白話就是: 一個是慢一點像老頭一樣一點一點的挪,一個是很快啊縱深一躍,容易骨折我真的沒寫錯字,。
- 利用有限差值計算
下面程式碼輸入函式f和向量x,計算f的梯度的通用函式,返回函式f在點x處的梯度。
def eval_numerical_gradient(f, x):
"""
a naive implementation of numerical gradient of f at x
簡單的實現梯度
- f should be a function that takes a single argument
只有一個引數
- x is the point (numpy array) to evaluate the gradient at
計算梯度的位置
"""
# 原點計算函式值
fx = f(x) # evaluate function value at original point
grad = np.zeros(x.shape)
h = 0.00001
# iterate over all indexes in x
# 來啊, 挪啊(迭代啦~~)
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
# evaluate function at x+h
# 挪了一步之後的海拔(x+h處的值)
ix = it.multi_index
old_value = x[ix]
x[ix] = old_value + h # increment by h(再挪一步,更新)
fxh = f(x) # evalute f(x + h)
# 記住你的海拔,太重要了
x[ix] = old_value # restore to previous value (very important!)
# compute the partial derivative
# 計算偏導數
grad[ix] = (fxh - fx) / h # the slope
it.iternext() # step to next dimension
return grad
概括一下回家過程:先對所有維度進行迭代,每個維度上會產生一個很小的變化h,通過觀察函式值變化,計算函式在該維度上的偏導數,最後把所有的梯度儲存在變數grad中。
**實踐一下:**我們一般用 1e-5來表示h,反正就是很小啦,其實我們還可以用:更好,細節。
計算權重空間中的某些隨機點上,CIFAR-10損失函式的梯度:
# 要使用上面的程式碼我們需要一個只有一個引數的函式(直譯)
# 在這裡引數就是權重,所以包含X_train和Y_train
def CIFAR10_loss_fun(W):
return L(X_train, Y_train, W)
W = np.random.rand(10, 3073) *
相關推薦
# cs231n (三)優化問題及方法
cs231n (三)優化問題及方法
標籤(空格分隔): 神經網路
0.回顧
cs231n (一)影象分類識別講了KNN
cs231n (二)講了線性分類器:SVM和SoftMax
回顧上次的內容,其實就會發現,雖然我們構造好了損失函式,可以簡單使用導數的
python(三)Requests庫方法及HTTP協議
學習框架:1.Requests 自動爬取HTML頁面 自動網路請求提交2. robots.txt 網路爬蟲排除標準3.Beautiful Soup 解析HTML頁面4.Projects實戰專案A/B5.Re 正則表示式詳解 提取頁面關鍵資訊6.Scrapy 網路爬蟲原理介紹
mysql慢查詢原因分析與解決(三)——索引及查詢優化
索引的型別
Ø 普通索引:這是最基本的索引型別,沒唯一性之類的限制。
Ø 唯一性索引:和普通索引基本相同,但所有的索引列值保持唯一性。
Ø 主鍵:主鍵是一種唯一索引,但必須指定為”PRIMARY KEY”。
Ø 全文索引:MYSQL從3.23.23開始支援全
AndroidStudio下加入百度地圖的使用 (三)——API基本方法及常量屬性
package com.jerehedu.administrator.baidumapapplication;
import android.app.Activity;
import android.os.Bundle;
import android.view.View;
import and
博世傳感器調試筆記(三)加速度及地磁傳感器BMC156
設計 fin 換算 byte 智能手機 jsb 傳感器 gis 操作 一. 器件簡介:1. BMC 156是一款整合三軸地磁傳感器與三軸(12bit)加速度傳感器於一體的傳感器,以BMC 150 電子羅盤模塊為基礎, 並與Bosch Sensortec 2x2平
(三)使用Pipe方法通信
size and become others logs dup res 參數 corrupt
from multiprocessing import Process,Pipe
import random
import time, os
def proc_send(pip
Redis深入學習筆記(三)RDB及AOF流程
del 每秒調用 查看 單個 一個 重寫 use 物理內存 深入學習 RDB是Redis持久化數據的一種方式,是執行時間點的Redis內存快照,redis數據還原時加載rdb文件,Redis的主從數據同步也是基於RDB實現的。
RDB流程:
JavaScript複習筆記(三)陣列及陣列API
一、陣列
分為兩種 關聯陣列:可以自己定義下標名稱的陣列
索引陣列:自動生成下標的陣列都是索引陣列
1、建立、賦值和取值
①建立:4種:
CSS基礎(三)--樣式及選擇器
1、 樣式分類
在CSS的樣式中,存在內聯式、嵌入式以及外部式三種引用方式。
&n
學生資訊管理系統總結(三)——優化篇
enter,esc鍵設定
確定按鈕屬性default------→true 取消按鈕屬性cancel------→true
窗體中心位置展現
首先將窗體介面通過滑鼠拖拽,達到介面大小適中 接著檢視屬性中的height,width屬性數值,將該數值填入下面程式碼中 from中新增以
MYSQL系列筆記(三)——優化專題
一、首先mysql得先開啟慢查詢日誌。不會的可以網上查。 1.1 環境準備: perl環境,因為mysql自帶的mysqldumpslow優化工具以及pt-query-digest工具分析都是perl檔案。 curl環境,因為mysql安裝版沒有帶pt-query-digest工具,所以想要
EventBus原始碼分析(三):post方法釋出事件【獲取事件的所有訂閱者,反射呼叫訂閱者事件處理方法】(2.4版本)
EventBus維護了一個重要的HashMap,這個HashMap的鍵是事件,值是該事件的訂閱者列表,因此post事件的時候就能夠從此HashMap中取出事件的訂閱者列表,對每個訂閱者反射呼叫事件處理方法。
private final Map<Cla
Lucene7.2.1系列(三)查詢及高亮
系列文章:
一 準備
建立專案並新增Maven依賴
<dependency>
<groupId>junit</groupId>
<
影象超解析度重構(一)原理及方法總結
超解析度(Super-resolution)概念理解:
百科:超解析度(Super-Resolution)通過硬體或軟體的方法提高原有影象的解析度,通過一系列低解析度的影象來得到一幅高解析度的影象過
MyBatis 筆記(三)——優化配置
在之前的講解中,不難發現 MyBatis 的配置有些笨重,這一節就講 MyBatis 的配置優化。毫無疑問,主要是兩方面:
1. 優化 MyBatis 基礎配置檔案。
2. 優化 MyBatis 對映檔案。
優化 MyBatis 基礎配置檔案
在 M
資料結構(三)——佇列及實現、迴圈佇列實現
一、佇列 佇列是一種特殊的線性表,它只允許在表的前端(front)進行刪除操作,而在表的後端(rear)進行插入操作。進行插入操作的端稱為隊尾,進行刪除操作的端稱為隊頭。佇列中沒有元素時,稱為空佇
Flask入門(三)~補充及虛擬環境
上篇文章中有幾個點不全面,在這裡補充幾點以及入門的幾個小方法:
上篇文章中使用jsonify模組讓網頁直接顯示json資料,返回的是二進位制碼,
如何解碼呢?以及開啟debug的幾個小方法:
程式碼如下:
方法一:
在py檔案中配置
# #解決中文亂碼問題,將json
Ansible使用介紹(三)templates及Roles角色
role內各目錄中可用的檔案
tasks目錄:至少應該包含一個名為main.yml的檔案,其定義了此角色的任務列表;此檔案可以使用include包含其他的位於此目錄中的task檔案;
files目錄:存放由copy或script等模組呼叫的檔案;
templates目錄
springCloud入門(三)遠端呼叫方法
新建一個客戶端呼叫已經註冊的遠端伺服器方法:
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xml
多執行緒和併發(三)使用join方法讓執行緒按順序執行
一.執行緒的join方法作用
join方法把指定的執行緒新增到當前執行緒中,可以不給引數直接thread.join(),也可以給一個時間引數,單位為毫秒thread.join(500)。事實上join方法是通過wait方法來實現的。比如執行緒A中加入了執行緒B.join方法