
知識圖譜---本體匹配(基於結構)
基於相似度的本體匹配
2.1.sf(similiarity flooding)
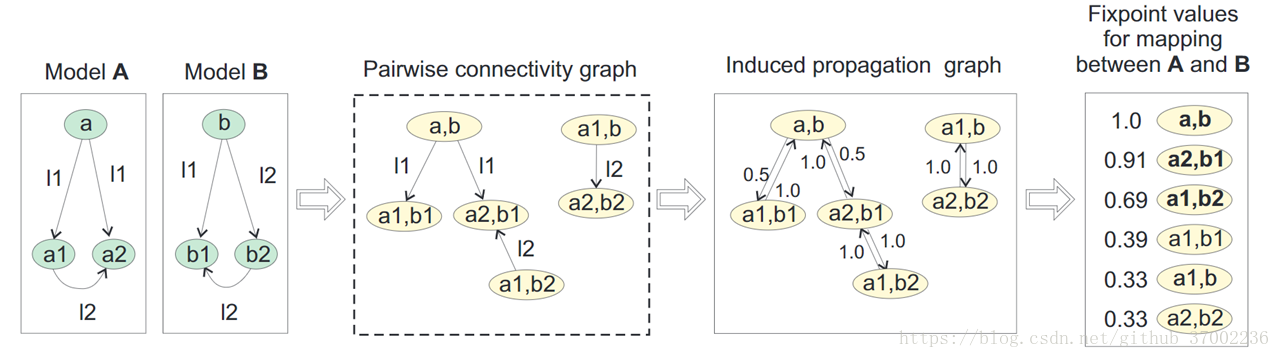
1)pairwise connectivity graph(PCG) : ((x; y); p; (x'; y')) 屬於 PCG(A;B)<==>(x; p; x') € A and (y; p; y') € B。 關鍵是p要相同,也就是邊的名字一樣。式子從右向左推導,就可以A、B從兩個模型建立起它們的PCG。圖中的每個節點,都是A和B中的元素構成的2元組,叫做map pairs。
2)induced propagation graph。從PCG推導而來,加上了反向的邊,邊上註明了[傳播係數],值為 1/n,n為相應的邊的數目。
3)每次迭代中,ó-values 都會根據其鄰居paris的 ó-values 乘以[傳播係數] 來增加。例如,在第一次迭代 ó1(a1; b1) = ó0(a1; b1) + ó0(a; b) * 0.5 = 1.5。類似的,ó1(a, b) = ó0(a, b) + ó0(a1; b1) * 1.0 + ó0(a2, b1) *1.0 = 3.0。接下來,所有 ó 值進行正規化,比如除以當前迭代的 ó 的最大值,保證所有 ó 都不大於1。所以在正規化以後,ó1(a; b) = 1.0, ó1(a1, b1) = 1.5/3.0 = 0.5。
sf方法缺陷
相似性只能傳播到“等邊”的元素,演算法中並沒有考慮邊的相似
在繁殖圖中,為雙向邊賦值繁殖係數,繁殖係數根據點對的出度均勻分配,相似度的計算只是簡單地利用繁殖系進行迭代,因此元素的相似度只由與它同邊的相似對決定而忽略了其他元素自身的某種聯絡。
2.2.改進sf
演算法的主要流程為:
1)利用WordNet對元素相似度進行初始化.挑選出一組可信度較高的相似對種子;
2)基於改進的SF演算法發現可能的相似對;
3)根據元素的特徵(如元素的父類、子類、屬性等)綜合計算相似對的相似度;
4)更新相似對種子,迭代地用相似度傳播演算法發現相似對,計算相似度,直到收斂;
5)從最終的相似度矩陣中提取出匹配對。