MapReduce的原始碼分析中map端輸出的原始碼分析
阿新 • • 發佈:2018-12-11
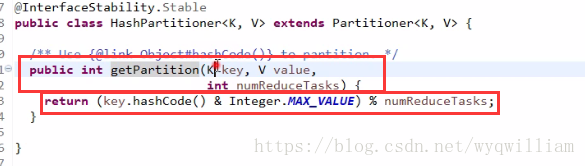
分割槽:
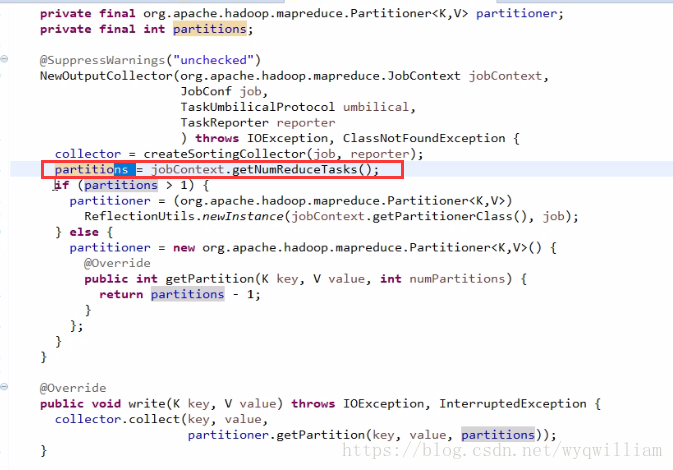
只有一個reduce的情況下,partition號為0
分割槽大有1的情況下,採用hash的方法:
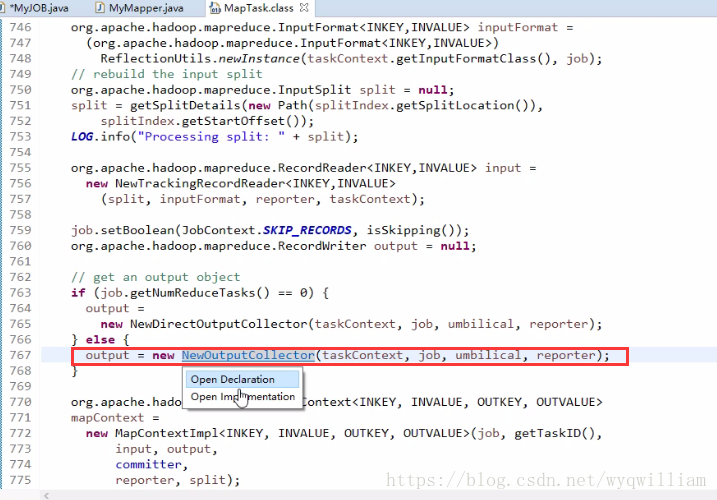
在輸入階段最核心的類是linerecorderReader()
在輸出階段最核心的類是mapoutputbuffer()
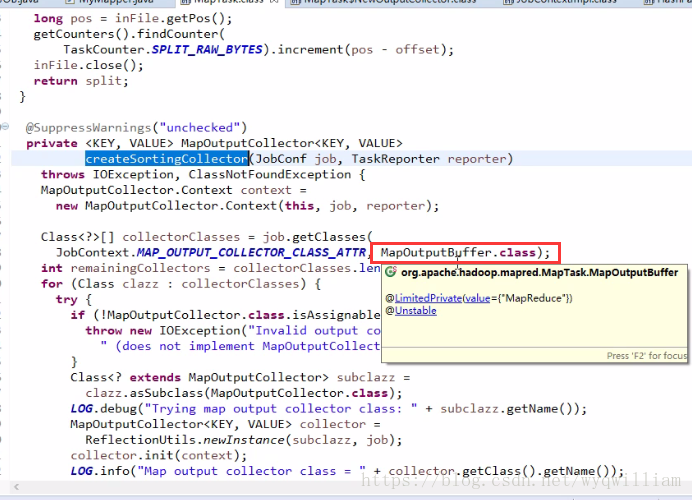
達到80%的時候會溢寫磁碟。
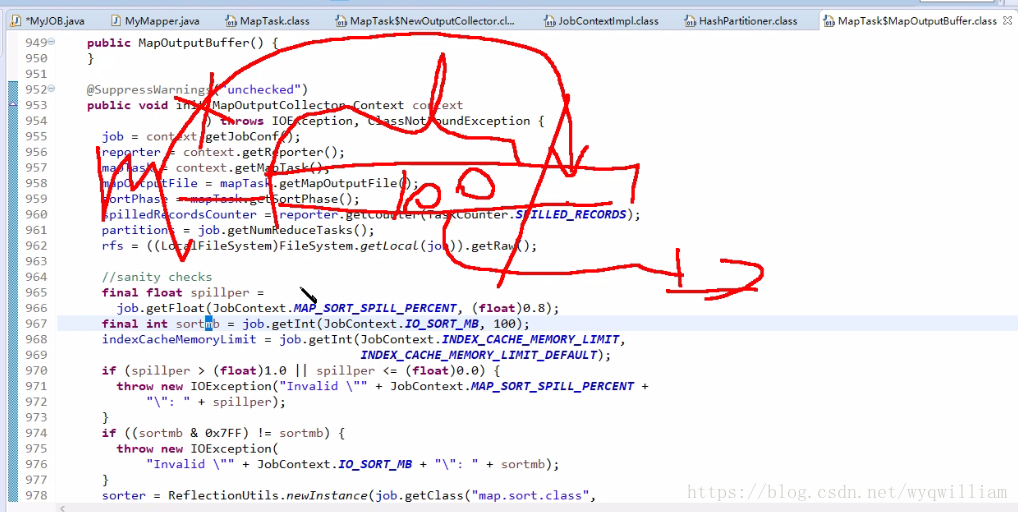
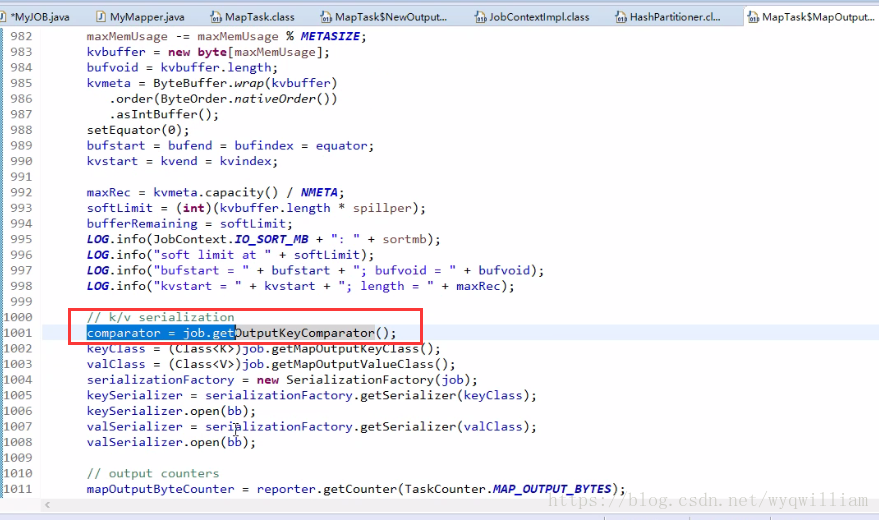
mapoutputkey做了三件事:

①:設定緩衝區溢寫磁碟的大小
②:準備了一個快排比較器,比較器底層看使用者定義的,如果使用者沒有定義,那麼就用系統預設的排序演算法
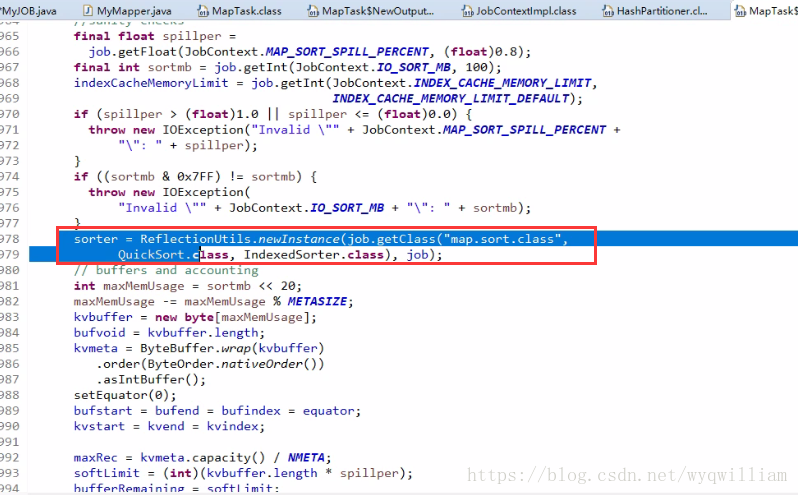
③:排序:
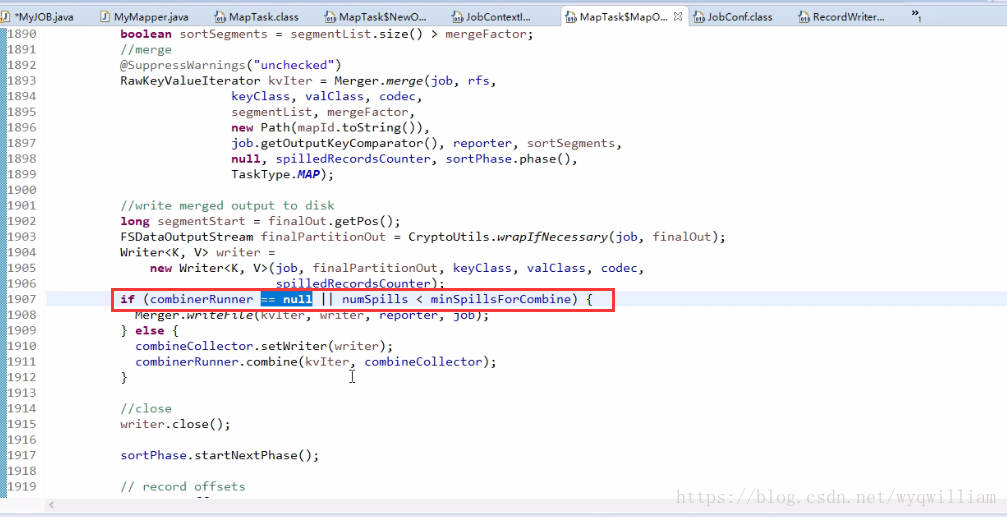
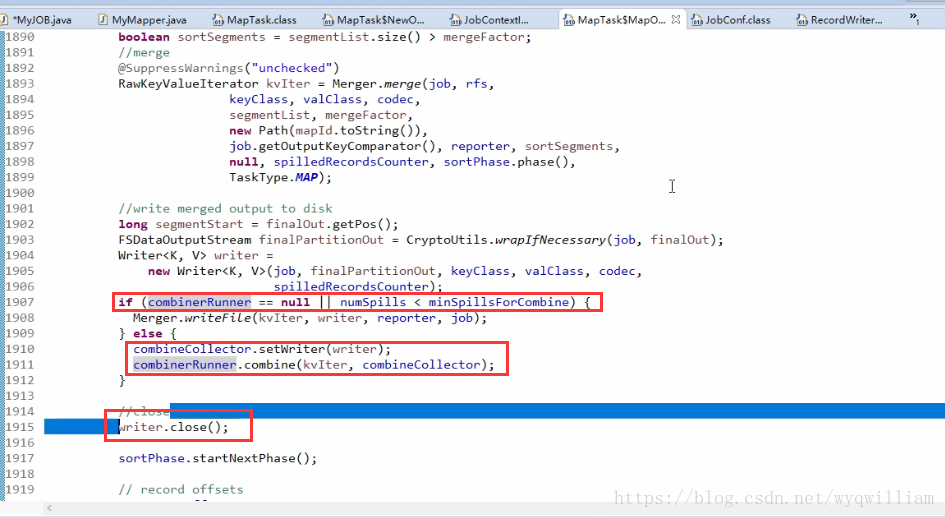
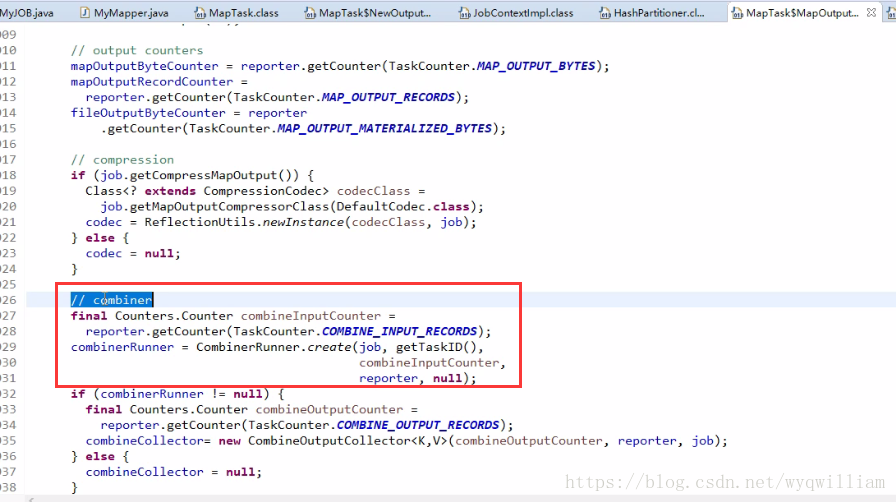
④:combiner:就是一個微縮版的reduce的實現
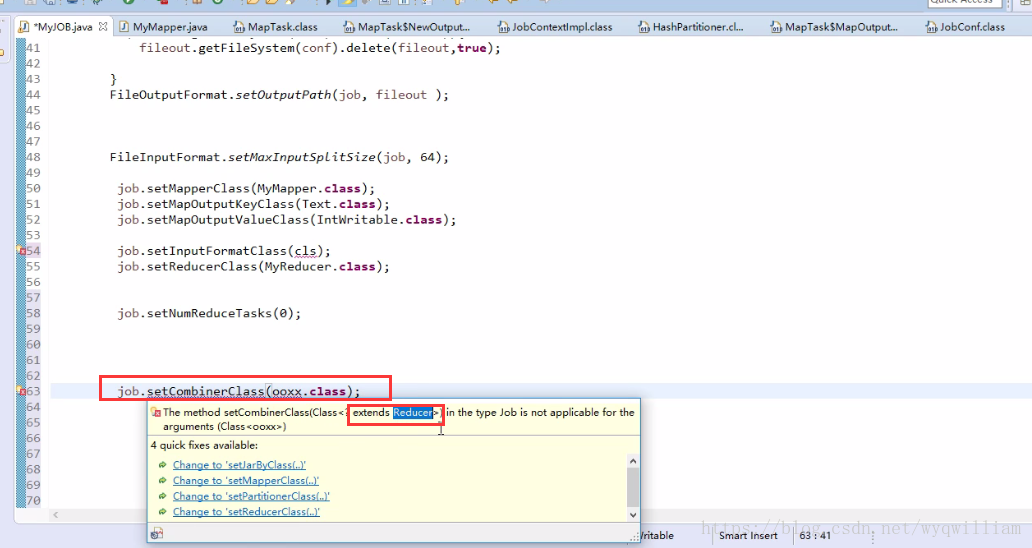
combiner可以設定,必須繼承reduce方法
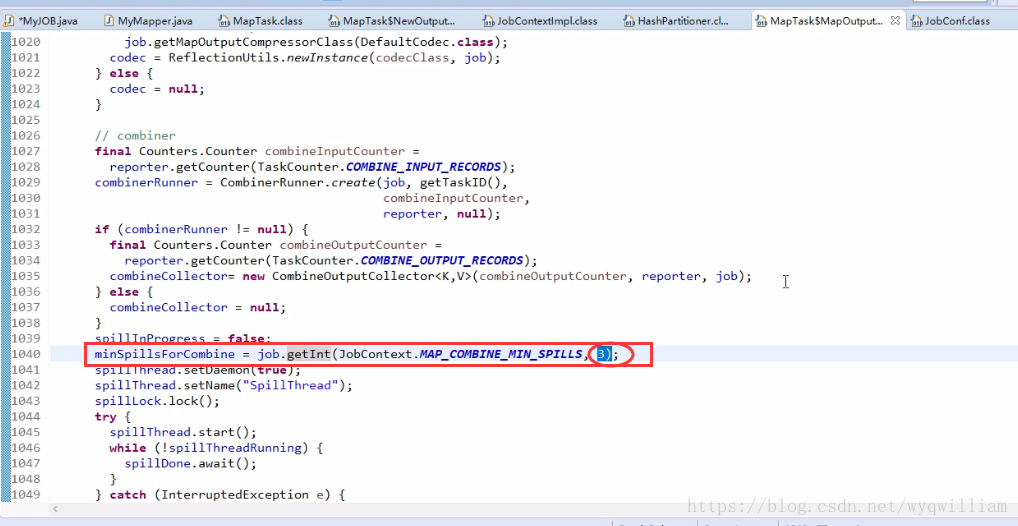
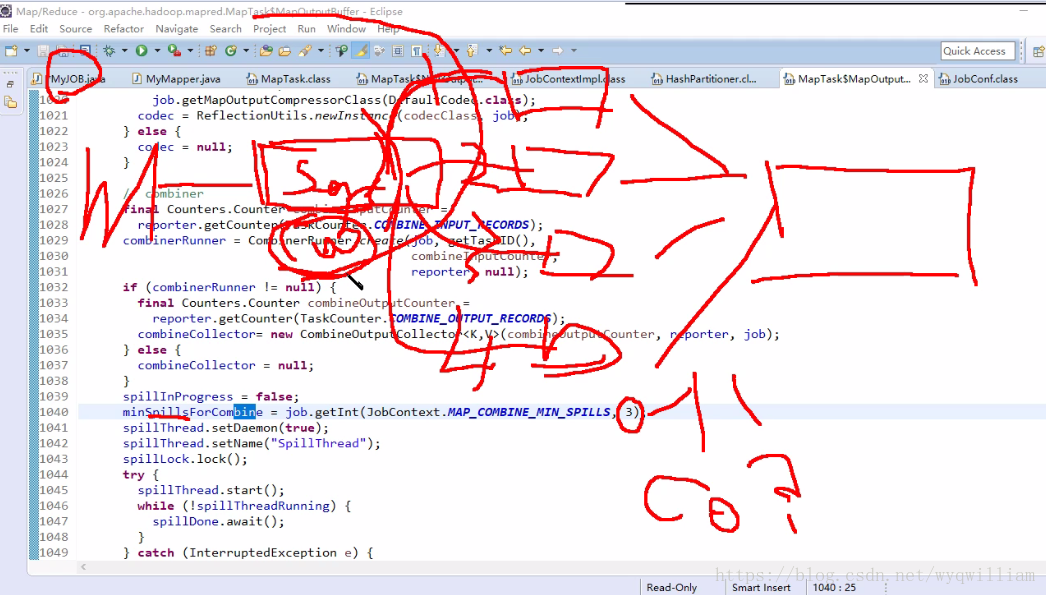
溢寫執行緒:

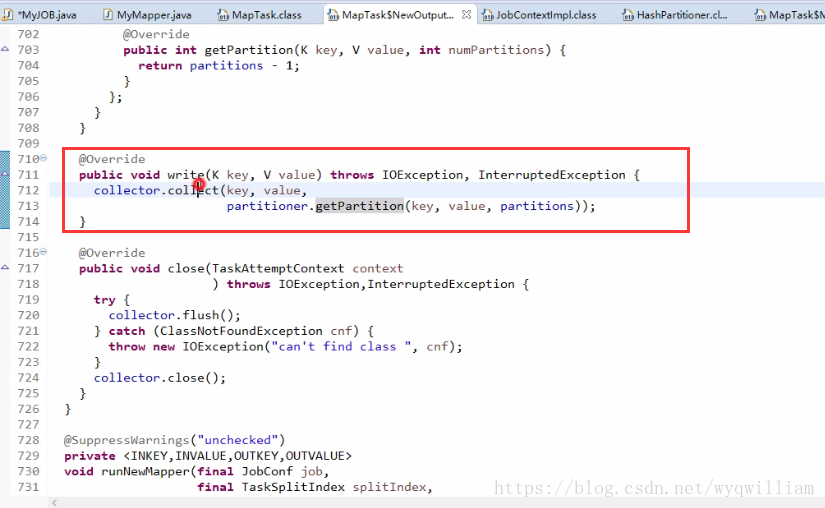
在map端的write最終會以序列化的形式溢寫在記憶體緩衝區中。


環形緩衝區:從零的位置開始放key和value,從另一個方向開始放索引,在剩下的部分:

按照赤道分開,繼續存放key,value和索引

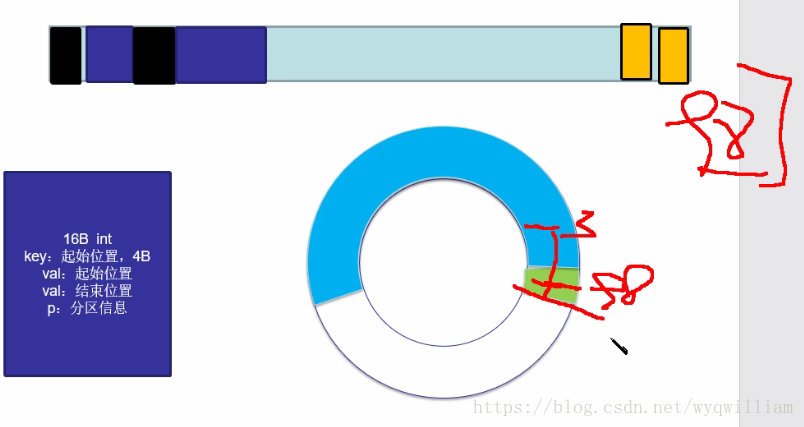
最終完成首位相接。
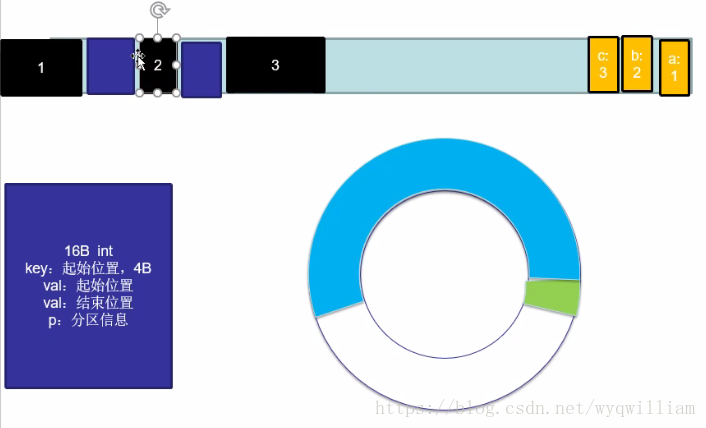
交換key,value的位置的時候,可以考慮交換索引的位置。

當達到80%的時候會溢寫磁碟,在溢寫磁碟之前會又一次sort排序

new map
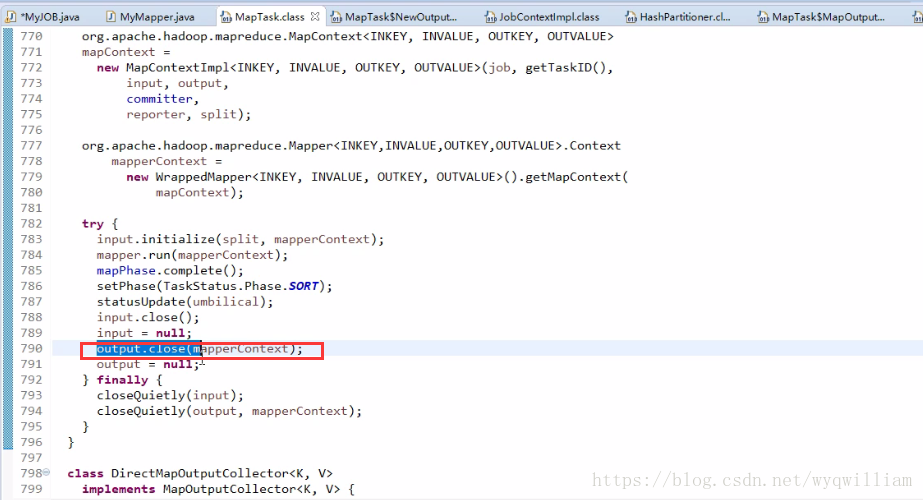
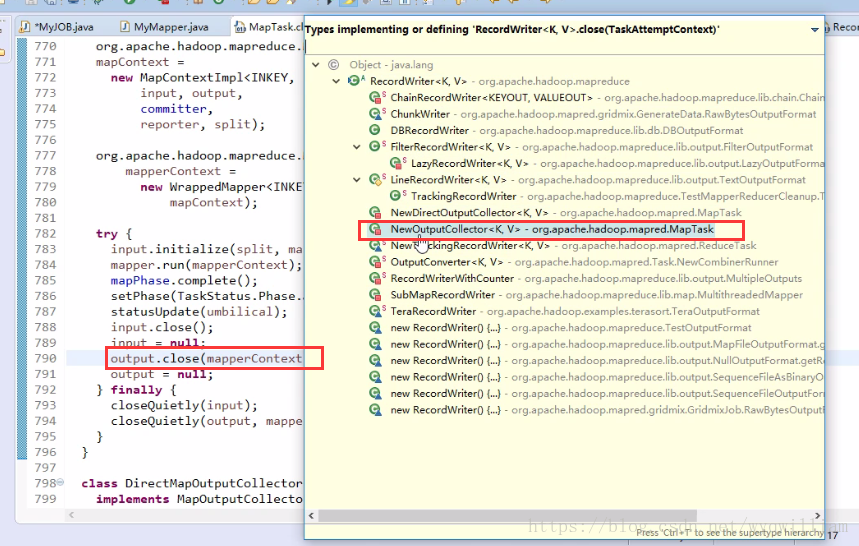
shuffle有一個sortandsplit
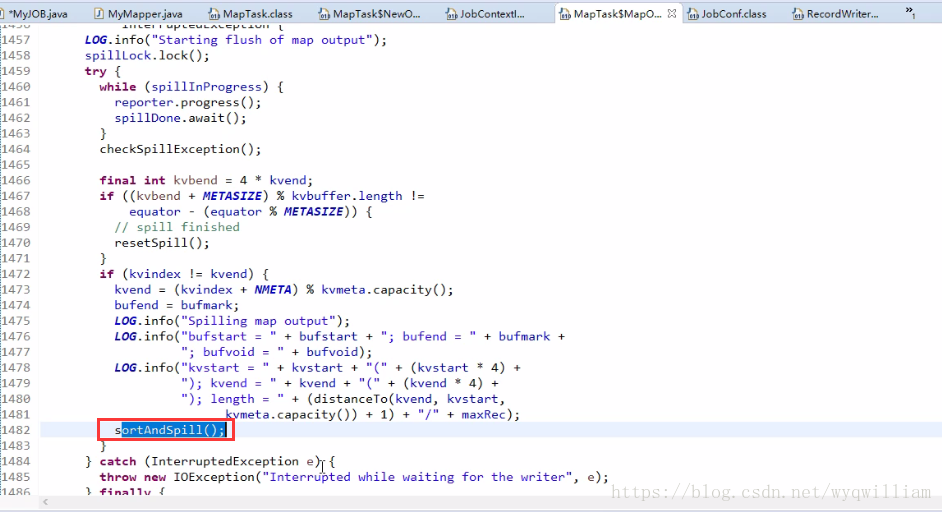
這才出發combiner