
Scrapy爬蟲實戰:百度搜索找到自己
Scrapy爬蟲實戰:百度搜索找到自己
這裡我們演示從百度找到我自己來讓大家理解了解爬蟲的魅力。
背景
有啥不懂的問度娘,百度搜索引擎可以搜到我們想要的內容,這裡我們可以嘗試爬取百度搜索引擎搜出來的東西,然後找到我們想要的內容。
例如:我們可以這樣來搜尋 https://www.baidu.com/s?wd=靈動的藝術
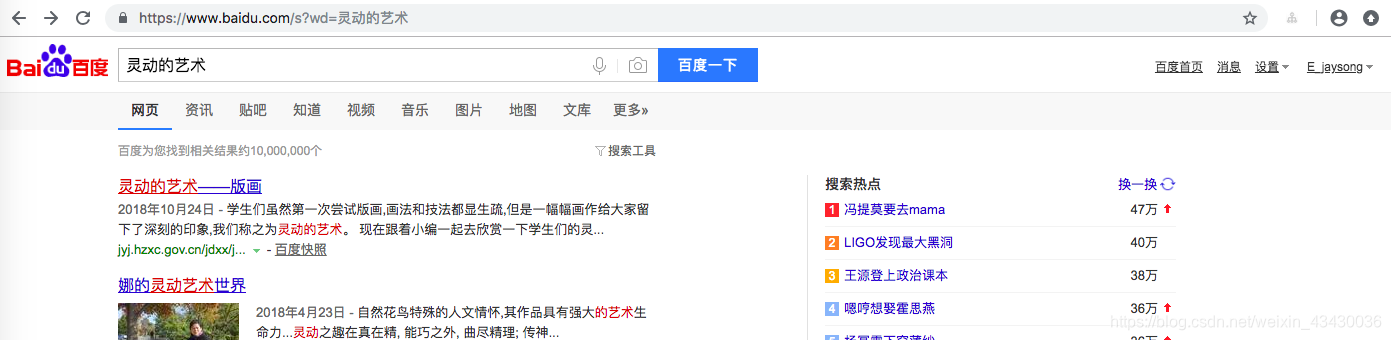
當然,因為我的部落格是新開的,第一個自然不是我,並且能排名第一的必然也是要花錢的,大家懂的。
並且不但第一個不是我,可能第一頁也可能都找不到我。我們需要不斷過濾更多頁才能找到我自己

分析
怎麼才算找到了自己
這裡我演示找到我自己的部落格就算是找到了我自己,判定方法有多種,比如找到了標題為【靈動的藝術的部落格】新開始,新旅程 - CSDN部落格就可以算是找到了我,或者百度連線為 http://www.baidu.com/link?url=9MdeR3DMon9bNvI8_loZk8MWb2s8zApEZx43oiOQgcsKAiSF3mvOD98YE811awwwm6NXYm8w7bVwfCF-a5VDerAiCmJyM1qFM9u5YrVraIO
這裡我們以標題為例:
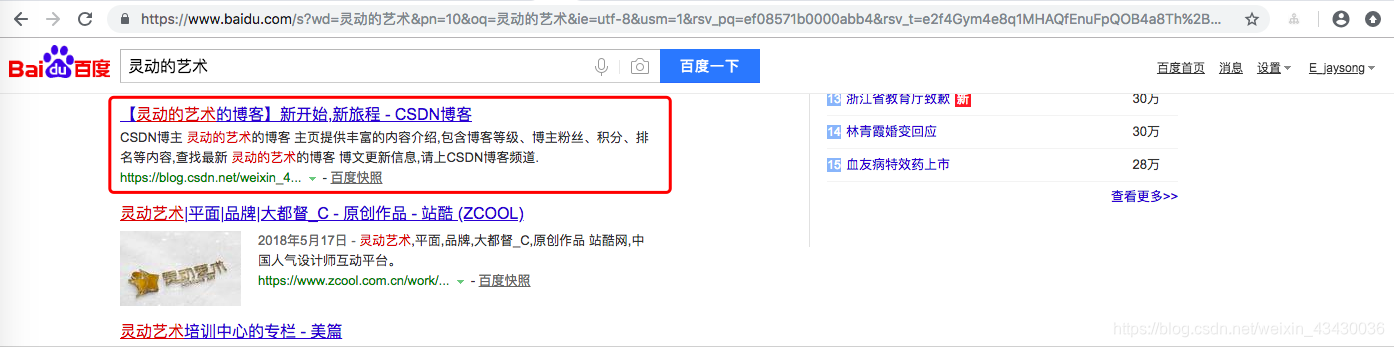
怎麼才能拿到百度搜索標題
如下圖,我們利用瀏覽器的檢查功能,利用選擇工具,選中標題,我們就可以看到當前頁面的內容
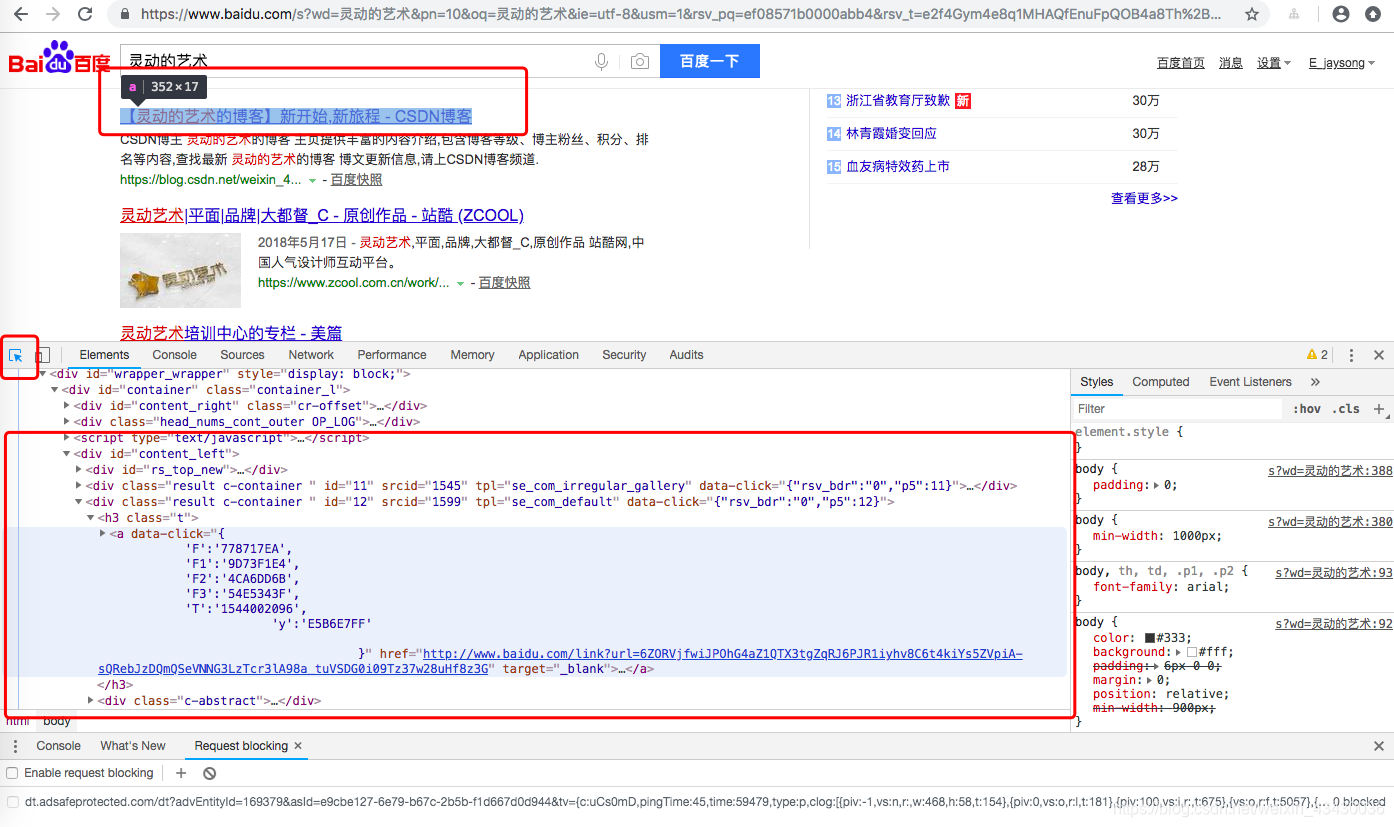
這裡我們可以知道我們的標題內容在'//div[@class="result c-container "]/h3/a'標籤裡面,那麼我們需要獲取這類標籤的內容。
怎麼爬取更多頁面
同樣的,如果我們希望爬取更多頁面,我們需要拿到更頁面的連線,並且繼續訪問它們。
同理:
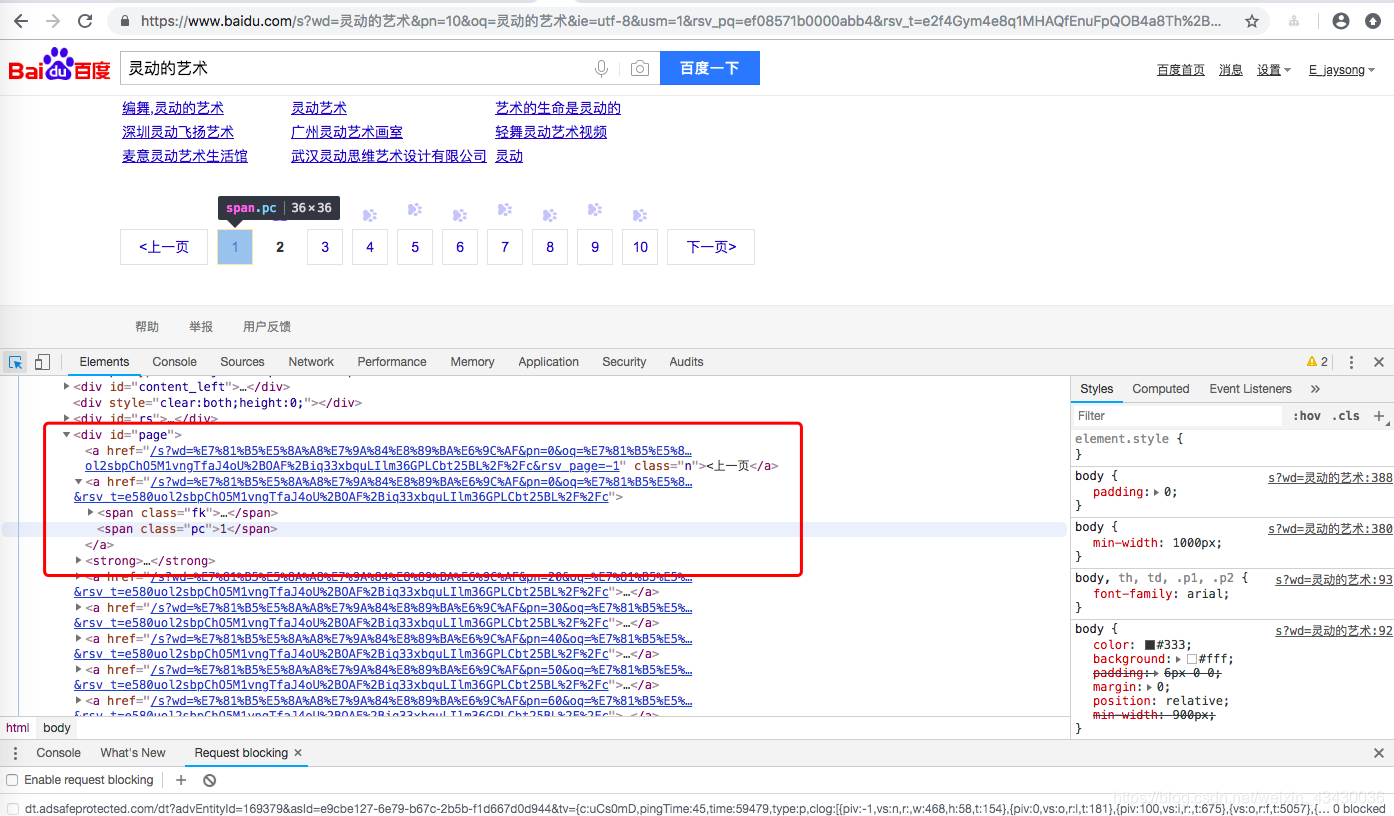
那麼我們可以知道//div[@id="page"]/strong/span[@class="pc"]/text()標籤可以拿到當前頁。//div[@id="page"]/a/@href
baidu_search.py
這裡我們修改之前的baidu_search.py
# -*- coding: utf-8 -*-
import scrapy
from tutorial.items import BaiDuSearchItem
class BaiduSearchSpider(scrapy.Spider):
name = 'baidu_search'
allowed_domains = ['www.baidu.com']
start_urls = ['http://www.baidu.com/s?wd=靈動的藝術']
def parse(self, response):
# 拿到當前頁碼
current_page = int(response.xpath('//div[@id="page"]/strong/span[@class="pc"]/text()').extract_first())
#當前頁面查詢內容
for i,a in enumerate(response.xpath('//div[@class="result c-container "]/h3/a')):
#拿到標題文字
title = ''.join(a.xpath('./em/text() | ./text()').extract())
# 精確找到自己
if title.find('靈動的藝術的部落格') > -1:
item = BaiDuSearchItem()
item['visit_url'] = a.xpath('@href').extract() # 提取連結
item['page'] = current_page
item['rank'] = i+1
item['title'] = title
yield item
#依次訪問百度下面的更多頁面,再次分別查詢
for p in response.xpath('//div[@id="page"]/a'):
p_url = 'http://www.baidu.com' + str(p.xpath('./@href').extract_first())
yield scrapy.Request(p_url, callback=self.parse_other_page)
def parse_other_page(self, response):
#拿到當前頁碼
current_page = int(response.xpath('//div[@id="page"]/strong/span[@class="pc"]/text()').extract_first())
#當前頁面查詢內容
for i,a in enumerate(response.xpath('//div[@class="result c-container "]/h3/a')):
# 拿到標題文字
title = ''.join(a.xpath('./em/text() | ./text()').extract())
# 精確找到自己
if title.find('靈動的藝術的部落格') > -1:
item = BaiDuSearchItem()
item['visit_url'] = a.xpath('@href').extract() # 提取連結
item['page'] = current_page
item['rank'] = i+1
item['title'] = title
yield item
程式碼比較簡單,簡單明瞭
宣告BaiDuSearchItem
Items
爬取的主要目標就是從非結構性的資料來源提取結構性資料,例如網頁。 Scrapy spider可以以python的dict來返回提取的資料.雖然dict很方便,並且用起來也熟悉,但是其缺少結構性,容易打錯欄位的名字或者返回不一致的資料,尤其在具有多個spider的大專案中。。
為了定義常用的輸出資料,Scrapy提供了 Item 類。 Item 物件是種簡單的容器,儲存了爬取到得資料。 其提供了 類似於詞典(dictionary-like) 的API以及用於宣告可用欄位的簡單語法。
許多Scrapy元件使用了Item提供的額外資訊: exporter根據Item宣告的欄位來匯出資料、 序列化可以通過Item欄位的元資料(metadata)來定義、 trackref 追蹤Item例項來幫助尋找記憶體洩露 (see 使用 trackref 除錯記憶體洩露) 等等。
items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class BaiDuSearchItem(scrapy.Item):
visit_url = scrapy.Field() # 連結
page = scrapy.Field() # 頁碼
rank = scrapy.Field() # 第幾位
title = scrapy.Field() # 主標題
Item Pipeline
當Item在Spider中被收集之後,它將會被傳遞到Item Pipeline,一些元件會按照一定的順序執行對Item的處理。
每個item pipeline元件(有時稱之為“Item Pipeline”)是實現了簡單方法的Python類。他們接收到Item並通過它執行一些行為,同時也決定此Item是否繼續通過pipeline,或是被丟棄而不再進行處理。
以下是item pipeline的一些典型應用:
- 清理HTML資料
- 驗證爬取的資料(檢查item包含某些欄位)
- 查重(並丟棄)
- 將爬取結果儲存到資料庫中
pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class BaiDuSearchPipeline(object):
def process_item(self, item, spider):
print('BaiDuSearchPipeline',item)
return item
配置Pipeline
我們需要在settings.py中配置Pipeline
settings.py
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'tutorial.pipelines.BaiDuSearchPipeline': 1,
}
執行測試
#進入虛擬環境
cd /data/code/python/venv/venv_Scrapy/
#crawl開始爬蟲
../bin/python3 ../bin/scrapy crawl baidu_search

結果表明,百度搜索出來的結果,我們在第2頁第一個和第5頁第八個都找到了我自己。