
關於ARM的核心架構
很多時候我們都會對M0,M0+,M3,M4,M7,arm7,arm9,CORTEX-A系列,或者說AVR,51,PIC等,一頭霧水,只知道是架構,不知道具體是什麼,有哪些不同?今天查了些資料,來解解惑,不是很詳細,但對此有個大體瞭解。咱先來當下最火的ARM吧
1.ARM
ARM即以英國ARM(Advanced RISC Machines)公司的核心晶片作為CPU,同時附加其他外圍功能的嵌入式開發板,用以評估核心晶片的功能和研發各科技類企業的產品. ARM 微處理器目前包括下面幾個系列,以及其它廠商基於 ARM 體系結構的處理器,除了具有ARM 體系結構的共同特點以外,每一個系列的 ARM 微處理器都有各自的特點和應用領域。 - ARM7 系列 - ARM9 系列 - ARM9E 系列 - ARM10E 系列 - ARM11系列 - Cortex 系列 - SecurCore 系列 - OptimoDE Data Engines - Intel的Xscale - Intel的StrongARM ARM11系列
2. Cortex 系列
32位RISCCPU開發領域中不斷取得突破,其設計的微處理器結構已經從v3發展到現在的v7。Cortex系列處理器是基於ARMv7架構的, 分為Cortex-M、Cortex-R和Cortex-A三類。由於應用領域的不同,基於v7架構的Cortex處理器系列所採用的技術也不相同。基於v7A的稱為“Cortex-A系列。 高效能的Cortex-A15、可伸縮的Cortex-A9、經過市場驗證的Cortex-A8處理器以及高效的Cortex-A7和Cortex-A5處理器均共享同一體系結構,因此具有完整的應用相容性,支援傳統的ARM、Thumb指令集 和新增的高效能緊湊型Thumb-2指令集。
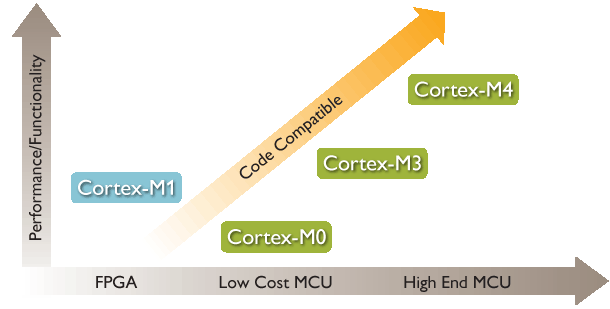
1Cortex-M系列
Cortex-M系列又可分為Cortex-M0、Cortex-M0+、Cortex-M3、Cortex-M4;
2Cortex-R系列
Cortex-R系列分為Cortex-R4、Cortex-R5、Cortex-R7;
3Cortex-A 系列
Cortex-A系列分為Cortex-A5、Cortex-A7、Cortex-A8、Cortex-A9、Cortex-A15、Cortex-A50等 ,同樣也就有了對應核心的Cortex-M0開發板、Cortex-A5開發板、Cortex-A8開發板、Cortex-A9開發板、 Cortex-R4開發板等等。
4半導體
由於ARM公司只對外提供ARM核心,各大廠商在授權付費使用ARM核心的基礎上研發生產各自的晶片,形成了嵌入式ARM CPU的大家庭,提供這些核心晶片的廠商有Atmel、TI、飛思卡爾、NXP、ST、和三星等。
Cortex-M相容特性
為了能做到Cortex-M軟體重用,ARM公司在設計Cortex-M處理器時為其賦予了處理器向下相容、軟體二進位制向上相容特性。
首先看什麼是二進位制相容,這個特性主要是針對軟體而言,這裡指的是當某軟體(程式)依賴的標頭檔案或庫檔案分別升級時,軟體功能不受影響。要做到二進位制相容,被軟體所依賴的標頭檔案或庫檔案升級時必須是二進位制相容的。
那麼什麼又是向上相容,向上相容又叫向前相容,指的是在較低版本處理器上編譯的軟體可以在較高版本處理器上執行。
跟向上相容相對的另一個概念叫向下相容,向下相容又叫向後相容,指的是較高版本處理器可以正確執行在較低版本處理器上編譯的軟體。
所以其實既可以用向上相容,也可以用向下相容來形容Cortex-M特性,只不過描述的主語不一樣,我們可以說Cortex-M程式是向上相容的,也可以說Cortex-M處理器是向下相容的。
具體到Cortex-M處理器時,這個相容特性表現為:
- 從處理器角度看:CM0指令集和功能模組是最精簡的,CM7指令集和功能模組是最豐富的。不存在低版本處理器上存在的特性是高版本處理器所沒有的。
- 從軟體角度來看:CMSIS提供的標頭檔案和功能函式是二進位制向上相容的,比如某CM0軟體App使用的是core_cm0.h標頭檔案,而這個App要在CM7上執行時,不需要使用core_cm7.h再重新編譯一次(當然使用新標頭檔案編譯後的App也是正常的。)
從MCU核心到MCU實際應用是一個完整的產業鏈,這個產業鏈分為五個部分:

其實都是這樣,前三個部分有晶片廠家和架構核心公司負責開晶片,後兩個部分由研發公司根據晶片設計,開發。
就拿ST為例,ARM公司為最開始的部分,ST(意法半導體)為晶片設計與製造公司,以ARM核心為載體,通過進一步的設計開發,為ARM配備外圍的支援,為將計算控制能力應用到電子產品中提供晶片服務
Cortex-M0 處理器簡介
ARM公司的Cortex-M0應用於各種微控制器(MCU)中,並可讓研發工程師以8位的價位創造32位的的效能,並將傳統的8位和16位的處理器升級到更高效、更低功耗的32位處理器。
Cortex-M0是Cortex-M家族中的M0系列。最大特點是低功耗的設計。Cortex-M0為32位、3級流水線RISC處理器,其核心仍為馮.諾依曼結構,是指令和資料共享同一匯流排的架構。作為新一代的處理器,Cortex-M0的設計進行了許多的改革與創新,如系統儲存器地址映像(system address map)、改善效率並增強確定性的巢狀向量中斷系統(NVIC)與不可遮蔽中斷(NMI)、全新的硬體除錯單元等等,都帶給了使用者全新的體驗和更便利、 更有效率的操作。
技術架構
CortexM0其核心架構為ARMv6M,其運算能力可以達到0.9 DMIPS/MHz,而與其他的16位與8位處理器相比,由於CortexM0的運算效能大幅提高,所以在同樣任務的執行上CortexM0只需較低的執行速度,而大幅降低了整體的動態功耗。
Cortex—M0屬於ARMv6-M架構,包括1顆專為嵌入式應用而設計的ARM核、緊耦合的可巢狀中斷微控制器NVIC、可選的喚醒中斷控制器WIC,對外提供了基於AMBA結構(高階微控制器匯流排架構)的AHB-lite匯流排和基於CoreSight技術的SWD或JTAG除錯介面,如圖所示。Cortex-M0微控制器的硬體實現包含多個可配置選項:中斷數量、WIC、睡眠模式和節能措施、儲存系統大小端模式、系統滴答時鐘等,半導體廠商可以根據應用需要選擇合理的配置。
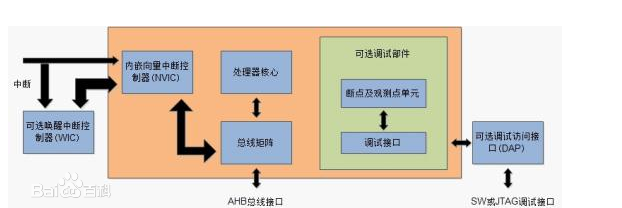

系統匯流排基於AHB_Lite高階高效能匯流排協議。外設匯流排基於APB高階外設匯流排協議,通過一個轉換橋連線到AHB上,這只是Cortex-M0核心的大概模式.
特點
1)能耗效率
CortexM0的執行效率很高(0.9DMIPS/MHz),能在較少的週期裡完成一項任務。這意味著CortexM0可以在大部分的時間裡處於休眠狀態,消耗很少的能量,具有良好的能耗效率。同樣較小的邏輯閘數也降低了待機電流。而高效的中斷控制器(NVIC)需要很小的中斷開銷。
2)程式碼密度
Cortex-M0基於Thumb-2的指令集,比用8位或者16位架構實現的程式碼還要少,因此使用者可以選擇具有較小Flash空間的晶片。可以降低系統功耗。[1]
3) 易於使用
Cortex-M0適用於C語言程式設計,並且被許多編譯器支援。可以用C語言直接程式設計中斷例程,而無需使用匯編語言。同時Cortex-M0還被多種開發工具支援。包括很多開源的嵌入式作業系統同樣支援Cortex-M0。
Cortex-M0 處理器簡介
1. Cortex-M0 處理器基於馮諾依曼架構(單匯流排介面),使用32位精簡指令集(RISC),該指令集被稱為Thumb指令集。與之前相比,新的指令集增加了幾條ARMv6架構的指令,並且加入了eThumb-2指令集的部分指令。Thumb-2技術擴充套件了Thumb的應用,允許所有的操作都可以在同一種CPU狀態下執行。Thumb指令集既包括16位指令,也包括32位指令。C編譯器生成的指令大部分是16位的,當16位的指令無法實現所需要的操作時,32位指令就會發揮作用。這樣以來,在程式碼密度得到提升的同時,還避免了兩套指令集之間進行切換帶來的開銷
2. Cortex-M0總共支援56個基本指令,其中某些指令可能會有多種形式。相對於Cortex-M0較小的指令集,其處理器的能力可不一般,因為Thumb是經過高度優化的指令集。從理論來說,由於讀寫儲存是的指令是相互獨立的,而且算數或邏輯操作的指令使用暫存器,Cortex-M0處理器可以被歸到載入-儲存(load-store)結構中。
3. 處理器核心包括:
- 暫存器組 包含16個32位暫存器,其中有一些特殊暫存器
- 算術邏輯單元
- 資料匯流排
- 控制邏輯
流水線根據設計可分為三種狀態: 取指、譯碼、執行。
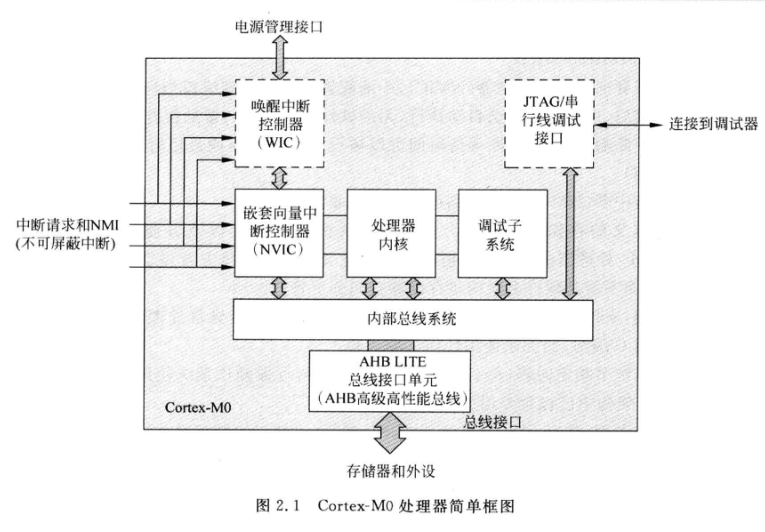
4. 巢狀向量中斷控制器(NVIC)可以處理最多32箇中斷請求和一個不可遮蔽中斷(NMI)輸入。
5. NVIC需要比較這個在執行中斷和請求中斷的優先順序,,然後自動執行高優先順序的中斷。
6. 如果要處理一箇中斷,NVIC會和處理器進行通訊,通知處理器執行中斷處理程式。
7. 喚醒中斷控制器(WIC)為可選的單元,在低功耗應用中,在關閉了處理器大部分模組後,微控制器會進入待機裝填,此時,WIC可以在NVIC和處理器處於休眠的情況下,執行中斷遮蔽功能。當WIC檢測到一箇中斷時,會通知電源管理部分給系統商店,讓NVIC和處理器核心執行剩餘的中斷處理。
8. 關於除錯子系統,當除錯事件發生時,處理器核心會被置於暫停狀態,這是開發人員可以檢查當前處理器的狀態。硬體除錯工具有JTAG和SWD(序列線除錯)。
ARM Cortex-M0 處理器的特性
系統特性
- thumb指令集,具有高效和高程式碼密度
- 高效能,最高達到0.9DMIPS/MHz
- 內建的巢狀向量中斷控制器(NVIC),中斷配置和異常處理容易
- 確定的中斷響應事件,中斷等待事件可以被設定為固定值或最短事件(最小16個時鐘週期)
- 不可遮蔽中斷(NMI),對高可靠性系統非常重要
- 內建的系統節拍定時器(systick)。24位定時器,可被作業系統使用,或者用作通用定時器,架構中已經包含專用的異常型別
- 請求管理呼叫,具有SVC異常和PendSV異常(可掛起的管理服務),支援嵌入式os的多種操作
- 架構定義的休眠模式和進入休眠的指令,休眠特效能大大降低能量的消耗。由於進入休眠狀態需要使用特定的指令,而不是使用暫存器,架構定義的休眠模式也提高了軟體的可移植性。
- 異常處理可以捕獲到系統中的多種錯誤。
應用特性
- 中斷數量可配置
- 支援大端或小端儲存器
- 可選擇的喚醒中斷控制器(WIC),處理器可以在休眠狀態下掉電以降低功耗,而WIC可以在中斷髮生時喚醒系統
Cortex-M3
Cortex-M3是一個32位的核,在傳統的微控制器領域中,有一些不同於通用32位CPU應用的要求。在工控領域,使用者要求具有更快的中斷速度,Cortex-M3採用了Tail-Chaining中斷技術,完全基於硬體進行中斷處理,最多可減少12個時鐘週期數,在實際應用中可減少70%中斷。
概述
Cortex-M3是一個32位處理器核心。內部的資料路徑是32位的,暫存器是32位的,儲存器介面也是32位的。CM3採用了哈佛結構,擁有獨立的指令匯流排和資料匯流排,可以讓取指與資料訪問並行不悖。這樣一來資料訪問不再佔用指令匯流排,從而提升了效能。為實現這個特性,CM3內部含有好幾條匯流排介面,每條都為自己的應用場合優化過,並且它們可以並行工作。但是另一方面,指令匯流排和資料匯流排共享同一個儲存器空間(一個統一的儲存器系統)。換句話說,不是因為有兩條匯流排,可定址空間就變成8GB了。
比較複雜的應用可能需要更多的儲存系統功能,為此CM3提供一個可選的MPU,而且在需要的情況下也可以使用外部的cache。另外在CM3中,Both小端模式和大端模式都是支援的。
CM3內部還附贈了好多除錯元件,用於在硬體水平上支援除錯操作,如指令斷點,資料觀察點等。另外,為支援更高階的除錯,還有其它可選元件,包括指令跟蹤和多種型別的除錯介面。
核心架構
ARMCortex-M3採用哈佛結構,並選擇了適合於微控制器應用的三級流水線,但增加了分支預測功能。
現代處理器大多采用指令預取和流水線技術,以提高處理器的指令執行速度。流水線處理器在正常執行指令時,如果碰到分支(跳轉)指令,由於指令執行的順序可能會發生變化,指令預取佇列和流水線中的部分指令就可能作廢,而需要從新的地址重新取指、執行,這樣就會使流水線“斷流”,處理器效能因此而受到影響。特別是現代C語言程式,經編譯器優化生成的目的碼中,分支指令所佔的比例可達10-20%,對流水線處理器的影響會的更大。為此,現代高效能流水線處理器中一般都加入了分支預測部件,就是在處理器從儲存器預取指令時,當遇到分支(跳轉)指令時,能自動預測跳轉是否會發生,再從預測的方向進行取指,從而提供給流水線連續的指令流,流水線就可以不斷地執行有效指令,保證了其效能的發揮。
ARMCortex-M3核心的預取部件具有分支預測功能,可以預取分支目標地址的指令,使分支延遲減少到一個時鐘週期。
針對業界對ARM處理器中斷響應的問題,Cortex-M3首次在核心上集成了巢狀向量中斷控制器(NVIC)。Cortex-M3的中斷延遲只有12個時鐘週期(ARM7需要24-42個週期);Cortex-M3還使用尾鏈技術,使得背靠背(back-to-back)中斷的響應只需要6個時鐘週期(ARM7需要大於30個週期)。Cortex-M3採用了基於棧的異常模式,使得晶片初始化的封裝更為簡單。
Cortex-M3加入了類似於8位處理器的核心低功耗模式,支援3種功耗管理模式:通過一條指令立即睡眠;異常/中斷退出時睡眠;深度睡眠。使整個晶片的功耗控制更為有效。

特點
高效能
許多指令都是單週期的——包括乘法相關指令。並且從整體效能上,Cortex-M3比得過絕大多數其它的架構。
指令匯流排和資料匯流排被分開,取值和訪內可以並行不悖
Thumb-2的到來告別了狀態切換的舊世代,再也不需要花時間來切換於32位ARM狀態和16位Thumb狀態之間了。這簡化了軟體開發和程式碼維護,使產品面市更快。
Thumb-2指令集為程式設計帶來了更多的靈活性。許多資料操作現在能用更短的程式碼搞定,這意味著Cortex-M3的程式碼密度更高,也就對儲存器的需求更少。
取指都按32位處理。同一週期最多可以取出兩條指令,留下了更多的頻寬給資料傳輸。
Cortex-M3的設計允許微控制器高頻執行(現代半導體制造技術能保證100MHz以上的速度)。即使在相同的速度下執行,CM3的每指令週期數(CPI)也更低,於是同樣的MHz下可以做更多的工作;另一方面,也使同一個應用在CM3上需要更低的主頻。
先進的中斷處理功能
內建的巢狀向量中斷控制器支援多達240條外部中斷輸入。向量化的中斷功能劇烈地縮短了中斷延遲,因為不再需要軟體去判斷中斷源。中斷的巢狀也是在硬體水平上實現的,不需要軟體程式碼來實現。
Cortex-M3在進入異常服務例程時,自動壓棧了R0-R3, R12, LR, PSR和PC,並且在返回時自動彈出它們,這多清爽!既加速了中斷的響應,也再不需要組合語言程式碼了。
NVIC支援對每一路中斷設定不同的優先順序,使得中斷管理極富彈性。最粗線條的實現也至少要支援8級優先順序,而且還能動態地被修改。
優化中斷響應還有兩招,它們分別是“咬尾中斷機制”和“晚到中斷機制”。
有些需要較多週期才能執行完的指令,是可以被中斷-繼續的——就好比它們是一串指令一樣。這些指令包括載入多個暫存器(LDM),儲存多個暫存器(STM),多個暫存器參與的PUSH,以及多個暫存器參與的POP。
除非系統被徹底地鎖定,NMI(不可遮蔽中斷)會在收到請求的第一時間予以響應。對於很多安全-關鍵(safety-critical)的應用,NMI都是必不不可少的(如化學反應即將失控時的緊急停機)。
低功耗
Cortex-M3需要的邏輯閘數少,所以先天就適合低功耗要求的應用(功率低於0.19mW/MHz)在核心水平上支援節能模式(SLEEPING和SLEEPDEEP位)。通過使用“等待中斷指令(WFI)”和“等待事件指令(WFE)”,核心可以進入睡眠模式,並且以不同的方式喚醒。另外,模組的時鐘是儘可能地分開供應的,所以在睡眠時可以把CM3的大多數“官能團”給停掉。
CM3的設計是全靜態的、同步的、可綜合的。任何低功耗的或是標準的半導體工藝均可放心飲用。
系統特性
系統支援“位定址帶”操作(8051位定址機制的“威力大幅加強版”),位元組不變的大端模式,並且支援非對齊的資料訪問。
擁有先進的fault處理機制,支援多種型別的異常和faults,使故障診斷更容易。
通過引入banked堆疊指標機制,把系統程式使用的堆疊和使用者程式使用的堆疊劃清界線。如果再配上可選的MPU,處理器就能徹底滿足對軟體健壯性和可靠性有嚴格要求的應用。
除錯支援
在支援傳統的JTAG基礎上,還支援更新更好的序列線除錯介面。
基於CoreSight除錯解決方案,使得處理器哪怕是在執行時,也能訪問處理器狀態和儲存器內容。
內建了對多達6個斷點和4個數據觀察點的支援。
可以選配一個ETM,用於指令跟蹤。資料的跟蹤可以使用DWT
在除錯方面還加入了以下的新特性,包括fault狀態暫存器,新的fault異常,以及快閃記憶體修補 (patch)操作,使得除錯大幅簡化。
可選ITM模組,測試程式碼可以通過它輸出除錯資訊,而且“拎包即可入住”般地方便使用。
程式設計模式
Cortex-M3處理器採用ARMv7-M架構,它包括所有的16位Thumb指令集和基本的32位Thumb-2指令集架構,Cortex-M3處理器不能執行ARM指令集。
Thumb-2在Thumb指令集架構(ISA)上進行了大量的改進,它與Thumb相比,具有更高的程式碼密度並提供16/32位指令的更高效能。
關於工作模式
Cortex-M3處理器支援2種工作模式:執行緒模式和處理模式。在復位時處理器進入“執行緒模式”,異常返回時也會進入該模式,特權和使用者(非特權)模式程式碼能夠在“執行緒模式”下執行。
出現異常模式時處理器進入“處理模式”,在處理模式下,所有程式碼都是特權訪問的。
關於工作狀態
Cortex-M3處理器有2種工作狀態。
Thumb狀態:這是16位和32位“半字對齊”的Thumb和Thumb-2指令的執行狀態。
除錯狀態:處理器停止並進行除錯,進入該狀態。
Cortex-M4
基本簡介
ARMCortex™-M4處理器是由ARM專門開發的最新嵌入式處理器,在M3的基礎上強化了運算能力,新加了浮點、DSP、平行計算等,用以滿足需要有效且易於使用的控制和訊號處理功能混合的數字訊號控制市場。其高效的訊號處理功能與Cortex-M處理器系列的低功耗、低成本和易於使用的優點的組合,旨在滿足專門面向電動機控制、汽車、電源管理、嵌入式音訊和工業自動化市場的新興類別的靈活解決方案。
特性
ARMCortex™-M4處理器核心是在Cortex-M3核心基礎上發展起來的,其效能比Cortex-M3提高了20%。新增加了浮點、DSP、平行計算等。用以滿足需要有效且易於使用的控制和訊號處理功能混合的數字訊號控制市場。其高效的訊號處理功能與Cortex-M處理器系列的低功耗、低成本和易於使用的優點相結合。
Cortex-M4提供了無可比擬的功能,將32位控制與領先的數字訊號處理技術整合來滿足需要很高能效級別的市場。
Cortex-M4處理器採用一個擴充套件的單時鐘週期乘法累加(MAC)單元、優化的單指令多資料(SIMD)指令、飽和運算指令和一個可選的單精度浮點單元(FPU)。這些功能以表現
ARMCortex-M系列處理器特徵的創新技術為基礎。包括
·RISC處理器核心,高效能32位CPU、具有確定性的運算、低延遲3階段管道,可達1.25DMIPS/MHz;
·Thumb-2指令集,16/32位指令的最佳混合、小於8位裝置3倍的程式碼大小、對效能沒有負面影響,提供最佳的程式碼密度;
·低功耗模式,整合的睡眠狀態支援、多電源域、基於架構的軟體控制;
·巢狀向量中斷控制器(NVIC),低延遲、低抖動中斷響應、不需要彙編程式設計、以純C語言編寫的中斷服務例程,能完成出色的中斷處理;
·工具和RTOS支援,廣泛的第三方工具支援、Cortex微控制器軟體介面標準(CMSIS)、最大限度地增加軟體成果重用;
·CoreSight除錯和跟蹤,JTAG或2針序列線除錯(SWD)連線、支援多處理器、支援實時跟蹤。
此外,該處理器還提供了一個可選的記憶體保護單元(MPU),提供低成本的除錯/追蹤功能和整合的休眠狀態,以增加靈活性。嵌入式開發者將得以快速設計並推出令人矚目的終端產品,具備最多的功能以及最低的功耗和尺寸。
處理技術
Cortex-M4 處理器已設計為具有適用於數字訊號控制市場的多種高效訊號處理功能。Cortex-M4 處理器採用擴充套件的單週期乘法累加 (MAC) 指令、優化的 SIMD 運算、飽和運算指令和一個可選的單精度浮點單元 (FPU)。這些功能以表現 ARM Cortex-M 系列處理器特徵的創新技術為基礎。

主要功能
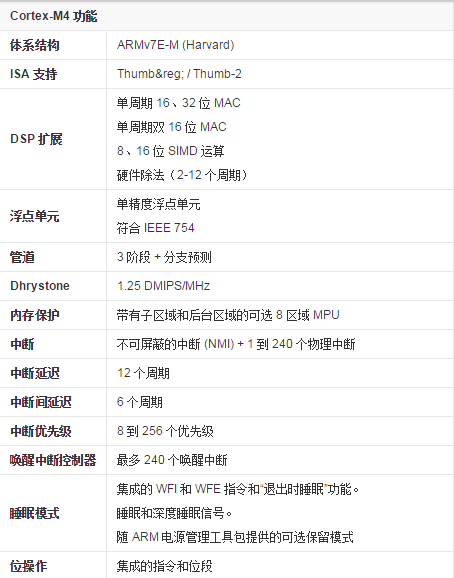
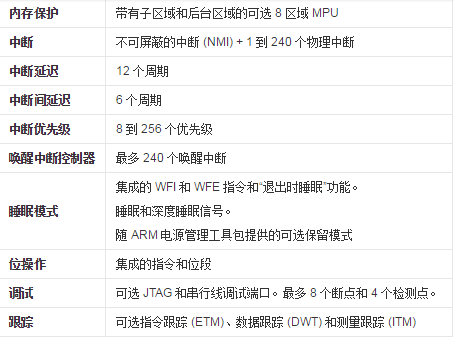
從圖上可以看出三者功能上的異同點。它們的不同點也決定了三者的不同應用場合。M4相比較前兩者主要的變化在於數字運算能力上的增強,增加了DSP運算指令、SIMD(Single Instruction Multiple Data,單指令多資料流)指令集、FPU(浮點運算單元,可選)。
從圖中足以看出M4核心的強大,同時Cortex-M 系列處理器都是二進位制向上相容的,這使得軟體重用以及從一個 Cortex-M 處理器無縫發展到另一個成為可能(圖3):
下面就增強的三個功能進行說明:
1、DSP指令集
所謂整合DSP功能並不是說M4核心是一個M3+DSP的雙核處理器(目前個人知道的這類處理器是TI的達芬奇系列,主要應用於語音、視訊影象有關的數字多媒體領域)。而是隻是增加了DSP功能的指令集(單週期的運算指令),能在一個週期內完成指令操作。在官方的CMSIS標準工程庫中已經整合,可以直接使用(有關內容在以後文章中介紹)。
圖表展示了處理器執行在相同的速度下Cortex - M3和Cortex - M4在數字訊號處理能力方面的相對效能比較。
在下面的數字,Y軸代表執行給出的計算用的相對的週期數。 因此,迴圈數越小,效能越好。以Cortex - M3作為參考,Cortex - M4的效能計算,效能比大概為其週期計數的倒數。舉例說明,PID功能,Cortex - M4的週期數是與Cortex - M3的約0.7倍,因此相對效能是1/0.7,即1.4倍。
Cortex - M系列16位迴圈計數功能
Cortex - M系列32位迴圈計數功能
這很清楚的表明,Cortex - M4在數字訊號處理方面對比Cortex - M3的16位或32位操作有著很大的優勢。
Cortex-M4執行的所有的DSP指令集都可以在一個週期完成,Cortex - M3需要多個指令和多個週期才能完成的等效功能。即使是PID演算法——通用DSP運算中最耗費資源的工作,Cortex - M4也能提供了一個1.4倍的效能得改善 。另一個例子,MP3解碼在Cortex-M3需要20-25Mhz,而在Cortex-M4只需要10-12MHz。
2. 32位乘法累加(MAC)
32位乘法累加(MAC)包括新的指令集和針對Cortex - M4硬體執行單元的優化它是能夠在單週期內完成一個 32 × 32 + 64 - > 64 的操作 或 兩個16 × 16 的操作。如下表列出了這個單元的計算能力。
3 .SIMD
(Single Instruction Multiple Data,單指令多資料流)能夠複製多個運算元,並把它們打包在大型暫存器的一組指令集,例:3DNow!、SSE。以同步方式,在同一時間內執行同一條指令。
SIMD在效能上的優勢:
以加法指令為例,單指令單資料(SISD)的CPU對加法指令譯碼後,執行部件先訪問記憶體,取得第一個運算元;之後再一次訪問記憶體,取得第二個運算元;隨後才能進行求和運算。而在SIMD型的CPU中,指令譯碼後幾個執行部件同時訪問記憶體,一次性獲得所有運算元進行運算。這個特點使SIMD特別適合於多媒體應用等資料密集型運算。
如:AMD公司引以為豪的3D NOW! 技術實質就是SIMD,這使K6-2、雷鳥、毒龍處理器在音訊解碼、視訊回放、3D遊戲等應用中顯示出優異的效能。
4.FPU
FPU是Cortex - M4浮點運算的可選單元。因此它是一個專用於浮點任務的單元。這個單元通過硬體提升效能,能處理單精度浮點運算,並與IEEE 754標準 相容。這完成了ARMv7 - M架構單精度變數的浮點擴充套件。FPU擴充套件了暫存器的程式模型與包含32個單精度暫存器的暫存器檔案。這些可以被看作是:
·16個64位雙字暫存器,D0 - D15
·32個32位單字暫存器,S0 - S31 該FPU提供了三種模式運作,以適應各種應用
·全相容模式(在全相容模式,FPU處理所有的操作都遵循IEEE754的硬體標準)
·Flush-to-zero 沖洗到零模式(設定FZ位浮點狀態和控制暫存器FPSCR [24]到flush-to-zero 模式。在此模式下,FPU 在運算中將所有不正常的輸入運算元的算術CDP操作當做0.除了當從零運算元的結果是合適的情況。VABS,VNEG,VMOV 不會被當做算術CDP的運算,而且不受flush-to-zero 模式影響。結果是微小的,就像在IEEE 754 標準的描述的那樣,在目標精度增加的幅度小於四捨五入後最低正常值,被零取代。IDC的標誌位,FPSCR [7],表示當輸入Flush時變化。UFC標誌位,FPSCR [3],表示當Flush結束時變化)
·預設的NaN模式(DN位的設定,FPSCR [25],會進入NaN的預設模式。在這種模式下,如對任何算術資料處理操作的結果,涉及一個輸入NaN,或產生一個NaN結果,會返回預設的NaN。僅當VABS,VNEG,VMOV運算時,分數位增加保持。所有其他的CDP運算會忽略所有輸入NaN的小數位的資訊)。具體指令請自行檢視手冊。
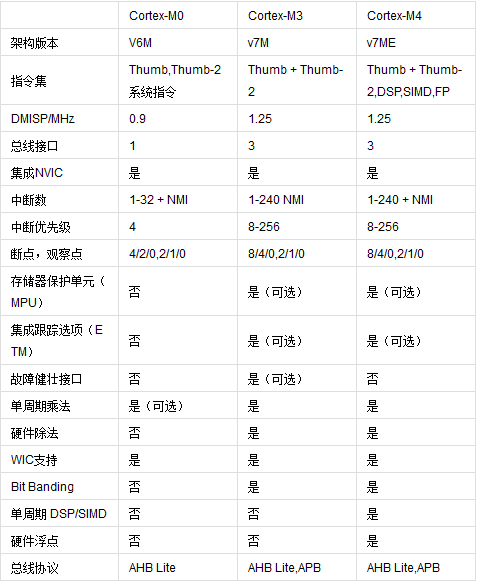
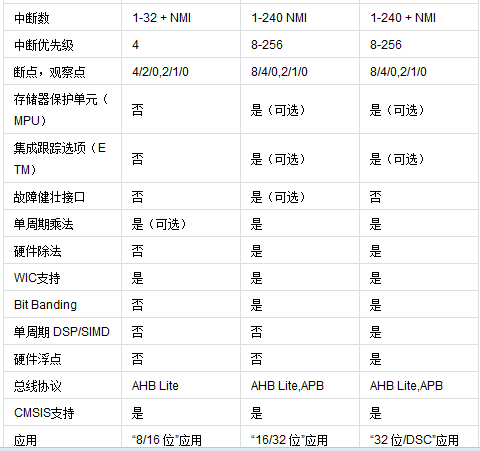
Cortex-M功能模組差異
由於CM1主要是用在FPGA產品中,故下面對比忽略CM1。我們知道CM處理器是向下相容的,故CM功能模組是隨著版本的升級而逐步增加的,我們逐步從最低版本開始對比。
2.1 CM0 vs CM0+
先來聊聊CM0與CM0+,從最基準的CM0模組看起:

- ARMv6-M CPU核心:ARM公司於2007年推出的核心。馮·諾依曼體系結構,3級流水線,支援大部分Thumb和小部分Thumb-2指令集,所有指令一共57條。此外還內嵌32-bit返回結果的硬體乘法器。
- NVIC巢狀向量中斷控制器:用於CPU在正常Run模式下中斷管理。最大支援32個外部中斷,外部中斷可設4級搶佔優先順序(2bit)。
- WIC喚醒中斷控制器:用於CPU在低功耗Sleep模式下中斷管理。
- AHB-Lite匯流排:一條32bit AMBA-3標準的高效能system匯流排負責所有Flash、SRAM中指令和資料存取。
- 除錯模組:0-4個硬體斷點Breakpoint,0-2個數據監測點Watchpoint。
- DAP除錯介面:通過DAP模組支援JTAG和SWD介面。

那麼CM0+到底改進了什麼?
- ARMv6-M CPU核心:流水線改為2級(很多8bit MCU都是2級流水線,主要用於降低功耗)
- NVIC巢狀向量中斷控制器:增加了VTOR即中斷重定向功能。
那麼CM0+到底增加了什麼?
- MPU儲存器保護單元:提供硬體方式管理和保護記憶體,控制訪問許可權,最大可將記憶體分為8*8個region。記憶體越權訪問,將返回MemManage Fault。
- MTB片上跟蹤單元:使用者體驗更好的的跟蹤除錯,優化的異常捕獲機制,可以更快地定位bug。
- Fast I/O:可單週期訪問的快速I/O口,更易於Bit-banging(比如GPIO模擬SPI、IIC協議)。
2.2 CM0+ vs CM3

前面比較完了CM0與CM0+,再來看看CM3比CM0+增強在了哪裡:
那麼CM3到底改進了什麼?
- ARMv7-M CPU核心:ARM公司於2004年推出的核心。哈佛體系結構,3級流水線+分支預測,支援全部的Thumb和Thumb-2指令集。內嵌32-bit硬體乘法器可返回64-bit運算結果,且新增32-bit硬體除法器。
- NVIC巢狀向量中斷控制器:最大支援240個外部中斷,中斷優先順序可分組(搶佔優先順序、響應優先順序),8bit優先順序設定(最大128級搶佔優先順序(對應最小2級響應優先順序),最大256級響應優先順序(對應無搶佔優先順序))。
- 3x AHB-Lite匯流排:除了原system匯流排負責SRAM存取外,還新增兩條ICode、DCode匯流排分別完成Flash上指令和資料存取。
- 除錯模組:0-8個硬體斷點Breakpoint,0-4個數據監測點Watchpoint。
- ITM/ETM跟蹤單元:ITM更好地支援printf風格debug,ETM提供實時指令和資料跟蹤。
那麼CM3到底增加了什麼?
額,CM3相比CM0+並沒有增加什麼獨有模組,反倒是少了Fast I/O Port,實際上Fast I/O Port是CM家族裡CM0+所獨有的模組。
2.3 CM3 vs CM4

前面比較完了CM0+與CM3,再來看看CM4比CM3增強在了哪裡:
那麼CM4到底改進了什麼?
- ARMv7E-M CPU核心:增加了DSP相關指令支援。
那麼CM4到底增加了什麼?
- DSP數字訊號處理單元:新增支援單週期16/32-bit MAC、dual 16-bit MAC, 8/16-bit SIMD演算法的數字訊號處理單元。
- FPU浮點運算單元:新增單精度(float型)相容IEEE-754標準的浮點運算單元(VFPv4-SP)。
2.4 CM4 vs CM7
前面比較完了CM3與CM4,再來看看CM7比CM4增強在了哪裡:
那麼CM7到底改進了什麼?
- ARMv7E-M CPU核心:6級流水線+分支預測。
- 2x AHB-Lite匯流排:精簡為2條AHB匯流排,其中AHB-P外設介面完成原來system匯流排功能, AHB-S從屬介面負責外部匯流排控制器(如DMA)功能以及與TCM介面功能。
- MPU儲存器保護單元:最大可將記憶體分為16*8個region。
- FPU浮點運算單元:新增雙精度(double型)相容IEEE-754標準的浮點運算單元(VFPv5)。

那麼CM7到底增加了什麼?
- I/D-Cache快取區:即是我們通常理解的L1 Cache,每個Cache大小為4-64KB。
- I/D-TCM緊密耦合儲存器:緊密的與處理器核心相耦合的RAM,提供與Cache相當的效能,但比Cache更具確定性,memory最大均為16MB。
- ECC特性:對L1 Cache提供錯誤校正和恢復功能,提高系統的可靠性。
- AXI-M匯流排:基於AMBA 4的64bit AXI匯流排,用於支援掛在系統上的L2 memory。
-
- 最近在關注Cortex-M處理器,針對目前進入大眾視野的M0、M3、M4做了如下簡單對比,內容來自ARM等官網,這裡僅僅是整理了下,看起來更直觀點,呵呵。
- Cortex-M 系列針對成本和功耗敏感的 MCU 和終端應用(如智慧測量、人機介面裝置、汽車和工業控制系統、大型家用電器、消費性產品和醫療器械)的混合訊號裝置進行過優化。.
- 一、比較Cortex-M 處理器
- Cortex-M 系列處理器都是二進位制向上相容的,這使得軟體重用以及從一個 Cortex-M 處理器無縫發展到另一個成為可能。
- M Cortex-M 技術
- CMSIS
- ARM Cortex 微控制器軟體介面標準 (CMSIS)是 Cortex-M 處理器系列的與供應商無關的硬體抽象層。 使用 CMSIS,可以為介面外設、實時作業系統和中介軟體實現一致且簡單的軟體介面,從而簡化軟體的重用、縮短新微控制器開發人員的學習過程,並縮短新產品的上市時間。
- 深入:巢狀向量中斷控制器 (NVIC)
- NVIC 是 Cortex-M 處理器不可或缺的部分,它為處理器提供了卓越的中斷處理能力。
- Cortex-M 處理器使用一個矢量表,其中包含要為特定中斷處理程式執行的函式的地址。接受中斷時,處理器會從該矢量表中提取地址。
- 為了減少門數並增強系統靈活性,Cortex-M 處理器使用一個基於堆疊的異常模型。出現異常時,系統會將關鍵通用暫存器推送到堆疊上。完成入棧和指令提取後,將執行中斷服務例程或故障處理程式,然後自動還原暫存器以使中斷的程式恢復正常執行。使用此方法,便無需編寫彙編器包裝器了(而這是對基於 C 語言的傳統中斷服務例程執行堆疊操作所必需的),從而使得應用程式的開發變得非常容易。NVIC支援中斷巢狀(入棧),從而允許通過運用較高的優先順序來較早地為某個中斷提供服務。
- 在硬體中完成對中斷的響應
- Cortex-M 系列處理器的中斷響應是從發出中斷訊號到執行中斷服務例程的週期數。它包括:
- 檢測中斷
- 背對背或遲到中斷的最佳處理(參見下文)
- 提取向量地址
- 將易損壞的暫存器入棧
- 跳轉到中斷處理程式
- 這些任務在硬體中執行,並且包含在為 Cortex-M 處理器報出的中斷響應週期時間中。在其他許多體系結構中,這些任務必須在軟體的中斷處理程式中執行,從而引起延遲並使得過程十分複雜。
- NVIC 中的尾鏈
- 在背對背中斷的情況下,傳統系統會重複完整的狀態儲存和還原週期兩次,從而導致更高的延遲。Cortex-M處理器通過在 NVIC 硬體中實現尾鏈技術簡化了活動中斷和掛起的中斷之間的轉換。處理器狀態會在比軟體實現時間更少的週期內自動儲存在中斷條目上並在中斷退出時還原,從而顯著提升低 MHz 系統的效能。
- NVIC 對遲到的較高優先順序中斷的響應
- 如果在為上一個中斷執行堆疊推送期間較高優先順序的中斷遲到,NVIC 會立即提取新的向量地址來為掛起的中斷提供服務,如上所示。Cortex-M NVIC 對這些可能性提供具有確定性的響應並支援遲到和搶佔。
- NVIC 進行的堆疊彈出搶佔
- 同樣,如果異常到達,NVIC 將放棄堆疊彈出並立即為新的中斷提供服務,如上所示。通過搶佔並切換到第二個中斷而不完成狀態還原和儲存,NVIC 以具有確定性的方式實現了縮短延遲。
再來說說ARM7,ARM9系列,
ARM9
ARM9系列處理器是英國ARM公司設計的主流嵌入式處理器,主要包括ARM9TDMI和ARM9E-S等系列。
基本概述
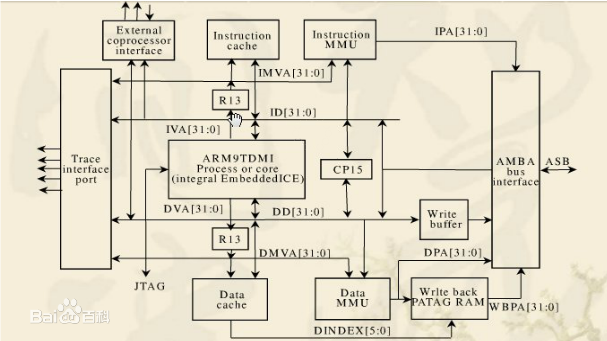
ARM9採用哈佛體系結構,指令和資料分屬不同的匯流排,可以並行處理。在流水線上,ARM7是三級流水線,ARM9是五級流水線。由於結構不同,ARM7的執行效率低於ARM9。平時所說的ARM7、ARM9實際上指的是ARM7TDMI、ARM9TDMI軟核,這種處理器軟核並不帶有MMU和cache,不能夠執行諸如linux這樣的嵌入式作業系統。而ARM公司對這種架構進行了擴充套件,所以有了ARM710T、ARM720T、ARM920T、ARM922T等帶有MMU和cache的處理器核心。
主要特性編輯
融合了ARM920T™ ARM® Thumb® 處理器
– 工作於180 MHz時效能高達200 MIPS,儲存器管理單元
– 16-K 位元組的資料快取,16-K位元組的指令快取,寫緩衝器
– 含有除錯通道的內部模擬器
– 中等規模的嵌入式巨集單元結構( 僅針對256 BGA 封裝)
· 低功耗:VDDCORE電流為30.4 mA 待機模式電流為3.1 mA
· 附加的嵌入式儲存器
– SRAM為16K ;ROM為128K
· 外部匯流排介面(EBI)
– 支援SDRAM,靜態儲存器, Burst Flash,無縫連線的CompactFlash®,
SmartMedia™及NAND Flash
· 提高效能而使用的系統外設:
– 增強的時鐘發生器與電源管理控制器
– 兩個有雙PLL的片上振盪器
– 低速的時鐘操作模式與軟體功耗優化能力
– 四個可程式設計的外部時鐘訊號
– 包括週期性中斷、看門狗及第二計數器的系統定時器
– 有報警中斷的實時時鐘
– 除錯單元、兩線UART並支援除錯通道
– 有8 個優先順序的高階中斷控制器,獨立的可遮蔽中斷源,偽中斷保護
– 7個外部中斷源及1 個快速中斷源
– 有122個可程式設計I/O口線的四個32 位PIO控制器,各線均有輸入變化中斷及開漏能力
– 20通道的外設資料控制器(DMA)
· 10/100 Base-T 型乙太網卡介面
– 獨立的媒體介面(MII)或簡化的獨立媒體介面(RMII)
– 對於接收與傳送有整合的28 位元組FIFO及專用的DMA 通道
· USB 2.0 全速(12 M位元/秒) 主機雙埠
– 雙片上收發器(208引腳PQFP封裝中僅為一個)
– 整合的FIFO及專用的DMA 通道
· USB 2.0 全速(12 M位元/秒) 器件埠
– 片上收發器, 2-K位元組可配置的整合FIFO
· 多媒體卡介面(MCI)
– 自動協議控制及快速自動資料傳輸
– 與MMC及SD儲存器卡相容,支援兩個SD儲存器
· 3個同步序列控制器(SSC)
– 每個接收器與傳送器有獨立的時鐘及幀同步訊號
– 支援I2S模擬介面,時分複用
– 32位元的高速資料流傳輸能力
· 4個通用同步/非同步接收/傳送器(USART)
– 支援ISO7816 T0/T1 智慧卡
– 硬軟體握手
– 支援RS485 及高達115 Kbps的IrDA 匯流排
– USART1為全調製解調控制線
· 主機/從機序列外設介面(SPI)
– 8~ 16 位可程式設計資料長度,可連線4個外設
· 兩個 3 通道16 位定時/計數器(TC)
– 3個外部時鐘輸入,每條通道有2 個多功能I/O引腳
– 雙PWM 產生器,捕獲/波形模式,上加/下減計數能力
· 兩線介面(TWI)
– 主機模式支援,所有兩線Atmel EEPROM 支援
· 所有數字引腳的IEEE 1149.1 JTAG邊界掃描
· 電源供應
– VDDCORE,VDDOSC及VDDPLL電壓為:1.65V ~1.95V
– VDDIOP (外設I/O) 及VDDIOM (儲存器I/O)電壓為:1.65V~ 3.6V
體系特點
結構特點
以ARM9E-S為例介紹ARM9處理器的主要結構及其特點。ARM9E-S的結構如圖4所示。其主要特點如下:
⑴32bit定點RISC處理器,改進型ARM/Thumb程式碼交織,增強性乘法器設計。支援實時(real-time)除錯;
⑵片內指令和資料SRAM,而且指令和資料的儲存器容量可調;
⑶片內指令和資料高速緩衝器(cache)容量從4K位元組到1M位元組;
⑷設定保護單元(protection unit),非常適合嵌入式應用中對儲存器進行分段和保護;
⑸採用AMBA AHB匯流排介面,為外設提供統一的地址和資料匯流排;
⑺支援標準基本邏輯單元掃描測試方法學,而且支援BIST(built-in-self-test);
ARM920T執行模式
ARM920T支援7種執行模式,分別為:
(1)使用者模式(usr),
ARM處理器正常的程式執行狀態;
(2)快速中斷模式 (fiq),
用於高速資料傳輸或通道處理;
(3)外部中斷模式(irq),
用於通用的中斷處理;
(4)管理模式(svc),
作業系統使用的保護模式;
(5)資料訪問終止模式(abt),
當資料或指令預取終止時進入該模式,可用於虛擬儲存及儲存保護;
(6)系統模式(sys),
執行具有特權的作業系統任務;
(7)未定義指令中止模式(und)
當未定義的指令執行時進入該模式,可用於支援硬體協處理器的軟體模擬。
ARM微處理器的執行模式可以通過軟體改變,也可以通過外部中斷或異常處理改變。大多數的應用程式執行在使用者模式下,當處理器執行在使用者模式下時,某些被保護的系統資源是不能被訪問的。除使用者模式以外,其餘的6種模式稱為特權模式;其中除去使用者模式和系統模式以外的5種又稱為異常模式,常用於處理中斷或異常,以及訪問受保護的系統資源等情況。
ARM920T的工作狀態
從程式設計的角度看,ARM920T微處理器的工作狀態一般有兩種:
(1)ARM狀態,此時處理器執行32位的、字對齊的ARM指令;
(2)Thumb狀態,此時處理器執行16位的、半字對齊的Thumb指令。
ARM指令集和Thumb指令集均有切換處理器狀態的指令,在程式的執行過程中,微處理器可以隨時在兩種工作狀態之間切換,並且,處理器的工作狀態的轉變並不影響處理器的工作模式和相應暫存器中的內容。但ARM微處理器在開始執行程式碼時,應該處於ARM
狀態。
當運算元暫存器的狀態位(位0)為1時,可以採用執行BX指令的方法,使微處理器從
ARM狀態切換到Thumb狀態。此外,當處理器處於Thumb狀態時發生異常(如IRQ、FIQ、Undef、Abort、SWI等),當異常處理返回時,自動切換回Thumb狀態。當運算元暫存器的狀態位為0時,執行BX指令可以使微處理器從Thumb狀態切換到ARM狀態。此外,在處理器進行異常處理時,將PC指標放入異常模式連結暫存器中,並從異常向量地址開始執行程式,也可以使處理器切換到ARM狀態。
ARM920T體系結構的儲存器格式
ARM920T體系結構將儲存器看做是從零地址開始的位元組的線性組合。從0位元組到3位元組放置第1個儲存的字資料,從第4個位元組到第7個位元組放置第2個儲存的字資料,依次排列。作為32位的微處理器,ARM92OT體系結構所支援的最大定址空間為4GB。
ARM92OT體系結構可以用兩種方法儲存字資料,分別稱為大端格式和小端格式。大端格式中字資料的高位元組儲存在低地址中,而字資料的低位元組則存放在高地址中
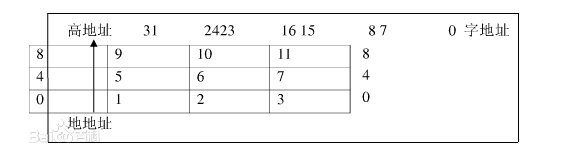
以大端格式儲存資料

以小端格式儲存資料
指令
⒈loads 指令與n stores指令
指令週期數的改進最明顯的是loads指令和stores指令。從ARM7到ARM9這兩條指令的執行時間減少了30%。指令週期的減少是由於ARM7和ARM9兩種處理器內的兩個基本的微處理結構不同所造成的。
⑴ARM9有獨立的指令和資料儲存器介面,允許處理器同時進行取指和讀寫資料。這叫作改進型哈佛結構。而ARM7只有資料儲存器介面,它同時用來取指令和資料訪問。
⑵5級流水線引入了獨立的儲存器和寫回流水線,分別用來訪問儲存器和將結果寫回暫存器。
以上兩點實現了一個週期完成loads指令和stores指令。
⒉互鎖(interlocks)技術
當指令需要的資料因為以前的指令沒有執行完而沒有準備好就會產生管道互鎖。當管道互鎖發生時,硬體會停止這個指令的執行,直到資料準備好為止。雖然這種技術會增加程式碼執行時間,但是為初期的設計者提供了巨大的方便。編譯器以及彙編程式設計師可以通過重新設計程式碼的順序或者其他方法來減少管道互鎖的數量。
⒊分枝指令
ARM9和ARM7的分枝指令週期是相同的。而且ARM9TDMI和ARM9E-S並沒有對分枝指令進行預測處理。
處理能力
新一代的ARM9處理器,通過全新的設計,採用了更多的電晶體,能夠達到兩倍以上於ARM7處理器的處理能力。這種處理能力的提高是通過增加時鐘頻率和減少指令執行週期實現的。
(一) 時鐘頻率的提高:
ARM7處理器採用3級流水線,而ARM9採用5級流水線。增加的流水線設計提高了時鐘頻率和並行處理能力。5級流水線能夠將每一個指令處理分配到5個時鐘週期內,在每一個時鐘週期內同時有5個指令在執行。在同樣的加工工藝下,ARM9TDMI處理器的時鐘頻率是ARM7TDMI的1.8~2.2倍。
(二) 指令週期的改進:
指令週期的改進對於處理器效能的提高有很大的幫助。效能提高的幅度依賴於程式碼執行時指令的重疊,這實際上是程式本身的問題。對於採用最高階的語言,一般來說,效能的提高在30%左右。
Cortex-A 系列處理器
Cortex-A 系列處理器是一系列處理器,支援ARM32或64位指令集,向後完全相容早期的ARM處理器,包括從1995年釋出的ARM7TDMI處理器到2002年釋出的ARMll處理器系列。
簡介
32位RISCCPU開發領域中不斷取得突破,其設計的微處理器結構已經從v3發展到現在的v7。Cortex系列處理器是基於ARMv7架構的,分為Cortex-M、Cortex-R和Cortex-A三類。由於應用領域的不同,基於v7架構的Cortex處理器系列所採用的技術也不相同。基於v7A的稱為“Cortex-A系列。高效能的Cortex-A15、可伸縮的Cortex-A9、經過市場驗證的Cortex-A8處理器以及高效的Cortex-A7和Cortex-A5處理器均共享同一體系結構,因此具有完整的應用相容性,支援傳統的ARM、Thumb指令集和新增的高效能緊湊型Thumb-2指令集。
Cortex-A15和Cortex-A7都支援ARMv7A體系結構的擴充套件,從而為大型實體地址訪問和硬體虛擬化以及啟用big.LITTLE處理的AMBA4ACE一致性提供支援。
技術特點
ARMv7包括3個關鍵要素:NEON單指令多資料(SIMD)單元、ARMtrustZone安全擴充套件、以及thumb2指令集,通過16位和32位混合長度指令以減小程式碼長度。
高效能
Cortex-A 裝置可為其目標應用領域提供各種可伸縮的能效效能點。一些說明示例如下:
Cortex-A15 ,可為新一代移動基礎結構應用和要求苛刻的無線基礎結構應用提供效能最高的解決方案 Cortex-A7,可採用獨立、多核配置實現,提供 800 MHz - 1.2 GHz 的典型頻率,也可以與 Cortex-A15 結合用於 big.LITTLE 處理 Cortex-A9 實現,可提供 800 MHz - 2 GHz 的標準頻率,每個核心可提供 5000 DMIPS 的效能 Cortex-A8 單核解決方案,可提供經濟有效的高效能,在 600 MHz - 1 GHz 的頻率下,提供的效能超過 2000 DMIPS Cortex-A5 低成本實現,在 400- 800 MHz 的頻率下,提供的效能超過 1200 DMIPS。
多核技術
Cortex-A5、[1] Cortex-A7、Cortex-A9 和 Cortex-A15 處理器都支援 ARM 的第二代多核技術
單核到四核實現,支援面向效能的應用領域 支援對稱和非對稱的作業系統實現 通過加速器一致性埠 (ACP) 在匯出到系統的整個處理器中保持一致性 Cortex-A7 和 Cortex-A15 將多核一致性擴充套件至 AMBA4 ACE 的 1~4 核群集以上(AMBA 一致性擴充套件)
高階擴充套件
除了具有與上一代經典 ARM 和 Thumb® 體系結構的二進位制相容性外,Cortex-A 類處理器還通過以下技術擴充套件提供了更多優勢
Thumb-2,提供最佳程式碼大小和效能 TrustZone 安全擴充套件,提供可信計算 Jazelle 技術,提高執行環境(如 Java、.Net、MSIL、Python 和 Perl)速度。
產品應用
ARM公司的Cortex-A系列處理器適用於具有高計算要求、執行豐富作業系統以及提供互動媒體和圖形體驗的應用領域。從最新技術的移動Internet必備裝置(如手機和超便攜的上網本或智慧本)到汽車資訊娛樂系統和下一代數字電視系統。也可以用於其他移動行動式裝置,還可以用於數字電視、機頂盒、企業網路、印表機和伺服器解決方案。這一系列的處理器具有高效低耗等特點,比較適合配置於各種移動平臺。
雖然Cortex-A處理器正朝著提供完全的Internet體驗的方向發展,但其應用也很廣泛,包括:
|
產品型別 |
應用 |
|---|---|
|
上網本、智慧本、輸入板、電子書閱讀器、瘦客戶端 |
|
|
手機 |
智慧手機、特色手機 |
|
數字家電 |
|
|
汽車 |
資訊娛樂、導航 |
|
企業 |
鐳射印表機、路由器、無線基站、VOIP 電話和裝置 |
|
無線基礎結構 |
Web 2.0、無線基站、交換機、伺服器 |
Cortex-A5 處理器
ARM Cortex™-A5 處理器是能效最高、成本最低的處理器,能夠向最廣泛的裝置提供 Internet 訪問:從入門級智慧手機、低成本手機和智慧移動終端到普遍採用的嵌入式、消費類和工業裝置。
Cortex-A5 處理器可為現有 ARM926EJ-S™ 和 ARM1176JZ-S™ 處理器設計提供很有價值的遷移途徑。它可以獲得比 ARM1176JZ-S 更好的效能,比 ARM926EJ-S 更好的功效和能效以及 100% 的 Cortex-A 相容性。
這些處理器向特別注重功耗和成本的應用程式提供高階功能,其中包括:
多重處理功能,可以獲得可伸縮、高能效效能
用於媒體和訊號處理的可選浮點或 NEON™單元
高效能記憶體系統,包括快取記憶體和記憶體管理單元
Cortex-A7 處理器
ARM Cortex™-A7 MPCore™ 處理器是 ARM 迄今為止開發的最有效的應用處理器,它顯著擴充套件了 ARM 在未來入門級智慧手機、平板電腦以及其他高階移動裝置方面的低功耗領先地位。
Cortex-A7 處理器的體系結構和功能集與 Cortex-A15 處理器完全相同,不同這處在於,Cort