
用Python爬取微博資料生成詞雲圖片
很早之前寫過一篇怎麼利用微博資料製作詞雲圖片出來,之前的寫得不完整,而且只能使用自己的資料,現在重新整理了一下,任何的微博資料都可以製作出來,放在今天應該比較應景。
一年一度的虐汪節,是繼續蹲在角落默默吃狗糧還是主動出擊告別單身汪加入散狗糧的行列就看你啦,七夕送什麼才有心意,程式猿可以試試用一種特別的方式來表達你對女神的心意。有一個創意是把她過往發的微博整理後用詞雲展示出來。本文教你怎麼用Python快速創建出有心意詞雲,即使是Python小白也能分分鐘做出來。
準備工作
本環境基於Python3,理論上Python2.7也是可行的,先安裝必要的第三方依賴包:
# requirement.txt jieba==0.38 matplotlib==2.0.2 numpy==1.13.1 pyparsing==2.2.0 requests==2.18.4 scipy==0.19.1 wordcloud==1.3.1
requirement.txt檔案中包含上面的幾個依賴包,如果用pip方式安裝失敗,推薦使用Anaconda安裝
pip install -r requirement.txt
第一步:分析網址
開啟微博移動端網址 https://m.weibo.cn/searchs ,找到女神的微博ID,進入她的微博主頁,分析瀏覽器傳送請求的過程
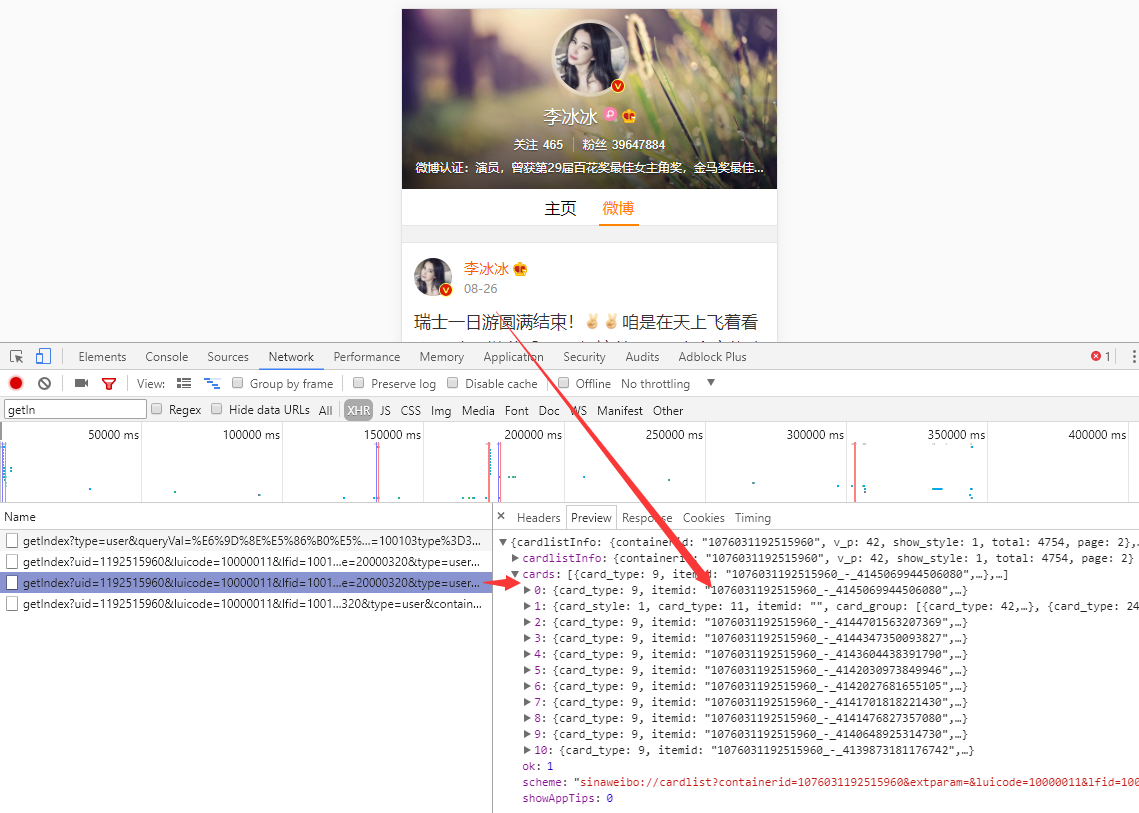
開啟 Chrome 瀏覽器的除錯功能,選擇 Network 選單,觀察到獲取微博資料的的介面是 https://m.weibo.cn/api/container/getIndex ,後面附帶了一連串的引數,這裡面有些引數是根據使用者變化的,有些是固定的,先提取出來。
uid=1192515960& luicode=10000011& lfid=100103type%3D3%26q%3D%E6%9D%8E%E5%86%B0%E5%86%B0& featurecode=20000320& type=user& containerid=1076031192515960
再來分析介面的返回結果,返回資料是一個JSON字典結構,total 是微博總條數,每一條具體的微博內容封裝在 cards 陣列中,具體內容欄位是裡面的 text 欄位。很多幹擾資訊已隱去。
{ "cardlistInfo": { "containerid": "1076031192515960", "total": 4754, "page": 2 }, "cards": [ { "card_type": 9, "mblog": { "created_at": "08-26", "idstr": "4145069944506080", "text": "瑞士一日遊圓滿結束...", } }] }
第二步:構建請求頭和查詢引數
分析完網頁後,我們開始用 requests 模擬瀏覽器構造爬蟲獲取資料,因為這裡獲取使用者的資料無需登入微博,所以我們不需要構造 cookie資訊,只需要基本的請求頭即可,具體需要哪些頭資訊也可以從瀏覽器中獲取,首先構造必須要的請求引數,包括請求頭和查詢引數。
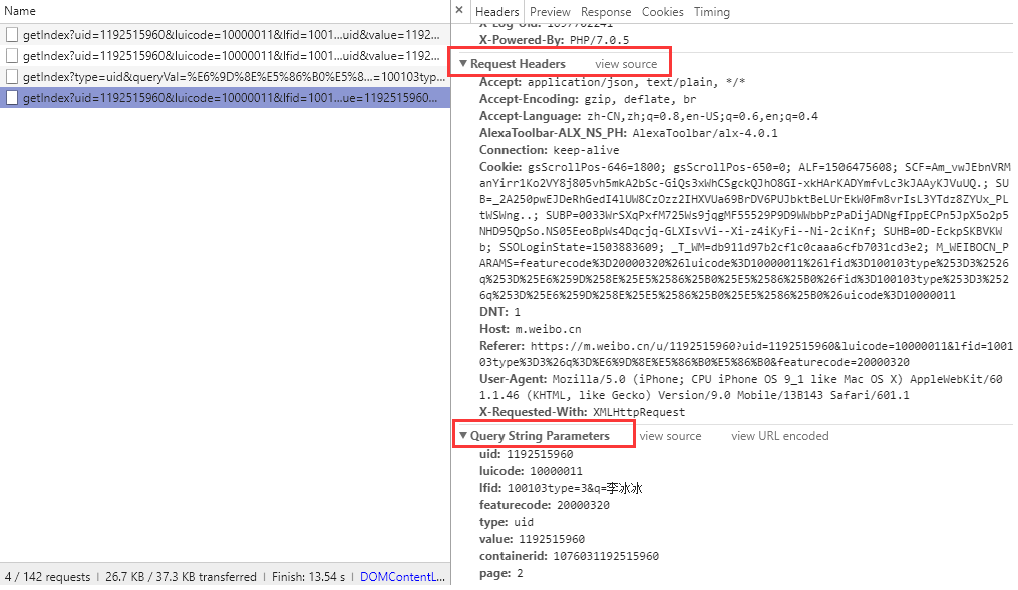
headers = { "Host": "m.weibo.cn", "Referer": "https://m.weibo.cn/u/1705822647", "User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) " "Version/9.0 Mobile/13B143 Safari/601.1", } params = {"uid": "{uid}", "luicode": "20000174", "featurecode": "20000320", "type": "uid", "value": "1705822647", "containerid": "{containerid}", "page": "{page}"}
- uid是微博使用者的id
- containerid雖然不什麼意思,但也是和具體某個使用者相關的引數
- page 分頁引數
第三步:構造簡單爬蟲
通過返回的資料能查詢到總微博條數 total,爬取資料直接利用 requests 提供的方法把 json 資料轉換成 Python 字典物件,從中提取出所有的 text 欄位的值並放到 blogs 列表中,提取文字之前進行簡單過濾,去掉無用資訊。順便把資料寫入檔案,方便下次轉換時不再重複爬取。
def fetch_data(uid=None, container_id=None): """ 抓取資料,並儲存到CSV檔案中 :return: """ page = 0 total = 4754 blogs = [] for i in range(0, total // 10): params['uid'] = uid params['page'] = str(page) params['containerid'] = container_id res = requests.get(url, params=params, headers=HEADERS) cards = res.json().get("cards") for card in cards: # 每條微博的正文內容 if card.get("card_type") == 9: text = card.get("mblog").get("text") text = clean_html(text) blogs.append(text) page += 1 print("抓取第{page}頁,目前總共抓取了 {count} 條微博".format(page=page, count=len(blogs))) with codecs.open('weibo1.txt', 'w', encoding='utf-8') as f: f.write("\n".join(blogs))
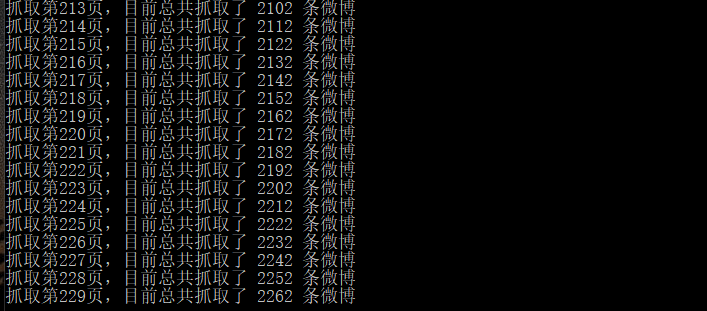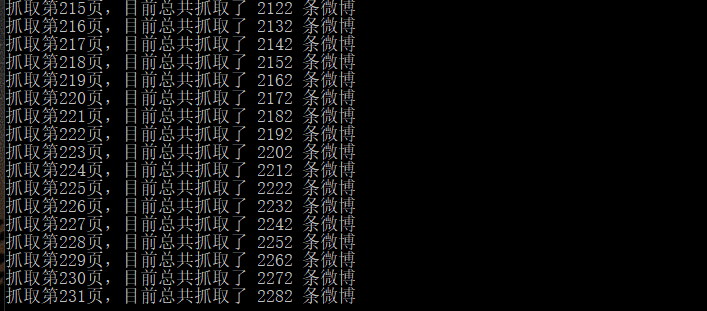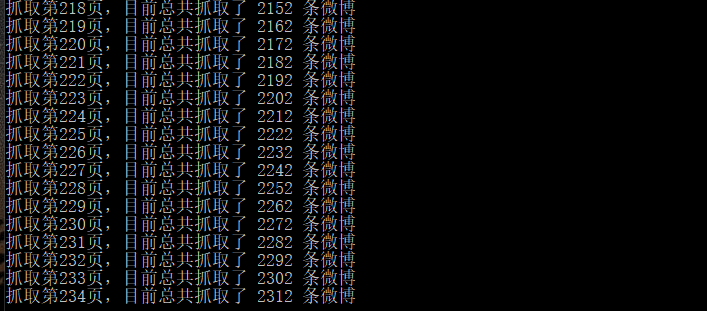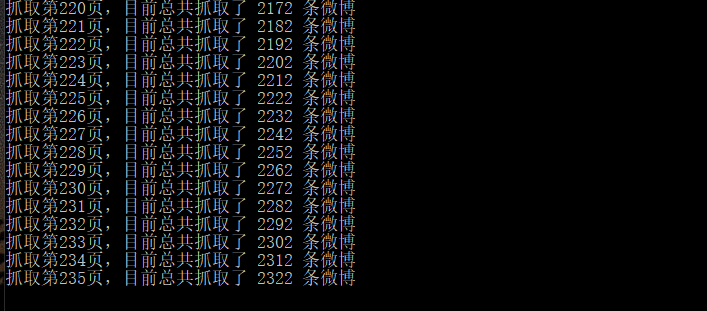
第四步:分詞處理並構建詞雲
爬蟲了所有資料之後,先進行分詞,這裡用的是結巴分詞,按照中文語境將句子進行分詞處理,分詞過程中過濾掉停止詞,處理完之後找一張參照圖,然後根據參照圖通過詞語拼裝成圖。
def generate_image(): data = [] jieba.analyse.set_stop_words("./stopwords.txt") with codecs.open("weibo1.txt", 'r', encoding="utf-8") as f: for text in f.readlines(): data.extend(jieba.analyse.extract_tags(text, topK=20)) data = " ".join(data) mask_img = imread('./52f90c9a5131c.jpg', flatten=True) wordcloud = WordCloud( font_path='msyh.ttc', background_color='white', mask=mask_img ).generate(data) plt.imshow(wordcloud.recolor(color_func=grey_color_func, random_state=3), interpolation="bilinear") plt.axis('off') plt.savefig('./heart2.jpg', dpi=1600)
最終效果圖:

完整程式碼可以在公眾號(Python之禪)回覆“qixi”獲取
關注公眾號「Python之禪」(id:vttalk)獲取最新文章
