
redis之哨兵(Sentinel)
阿新 • • 發佈:2018-12-11
Redis-Sentinel是redis官方推薦的高可用性解決方案,
當用redis作master-slave的高可用時,如果master本身宕機,redis本身或者客戶端都沒有實現主從切換的功能。 而redis-sentinel就是一個獨立執行的程序,用於監控多個master-slave叢集,
自動發現master宕機,進行自動切換slave > master。
sentinel主要功能如下:
- 不時的監控redis是否良好執行,如果節點不可達就會對節點進行下線標識
- 如果被標識的是主節點,sentinel就會和其他的sentinel節點“協商”,如果其他節點也人為主節點不可達,就會選舉一個sentinel節點來完成自動故障轉義
- 在master-slave進行切換後,master_redis.conf、slave_redis.conf和sentinel.conf的內容都會發生改變,即master_redis.conf中會多一行slaveof的配置,sentinel.conf的監控目標會隨之調換
Sentinel的工作方式
每個Sentinel以每秒鐘一次的頻率向它所知的Master,Slave以及其他 Sentinel 例項傳送一個 PING 命令 如果一個例項(instance)距離最後一次有效回覆 PING 命令的時間超過 down-after-milliseconds 選項所指定的值, 則這個例項會被 Sentinel 標記為主觀下線。 如果一個Master被標記為主觀下線,則正在監視這個Master的所有 Sentinel 要以每秒一次的頻率確認Master的確進入了主觀下線狀態。 當有足夠數量的 Sentinel(大於等於配置檔案指定的值)在指定的時間範圍內確認Master的確進入了主觀下線狀態, 則Master會被標記為客觀下線 在一般情況下, 每個 Sentinel 會以每10 秒一次的頻率向它已知的所有Master,Slave傳送 INFO 命令 當Master被 Sentinel 標記為客觀下線時,Sentinel 向下線的 Master 的所有 Slave 傳送 INFO 命令的頻率會從 10 秒一次改為每秒一次 若沒有足夠數量的 Sentinel 同意 Master 已經下線, Master 的客觀下線狀態就會被移除。 若 Master 重新向 Sentinel 的 PING 命令返回有效回覆, Master 的主觀下線狀態就會被移除。 主觀下線和客觀下線 主觀下線:Subjectively Down,簡稱 SDOWN,指的是當前 Sentinel 例項對某個redis伺服器做出的下線判斷。 客觀下線:Objectively Down, 簡稱 ODOWN,指的是多個 Sentinel 例項在對Master Server做出 SDOWN 判斷,並且通過 SENTINELis-master-down-by-addr 命令互相交流之後,得出的Master Server下線判斷,然後開啟failover. SDOWN適合於Master和Slave,只要一個 Sentinel 發現Master進入了ODOWN, 這個 Sentinel 就可能會被其他 Sentinel 推選出, 並對下線的主伺服器執行自動故障遷移操作。 ODOWN只適用於Master,對於Slave的 Redis 例項,Sentinel 在將它們判斷為下線前不需要進行協商, 所以Slave的 Sentinel 永遠不會達到ODOWN。
redis主從複製存在的問題
Redis主從複製可將主節點資料同步給從節點,從節點此時有兩個作用:
一旦主節點宕機,從節點作為主節點的備份可以隨時頂上來。
擴充套件主節點的讀能力,分擔主節點讀壓力。
但是問題是:
一旦主節點宕機,從節點上位,那麼需要人為修改所有應用方的主節點地址(改為新的master地址),還需要命令所有從節點複製新的主節點
那麼這個問題,redis-sentinel就可以解決了
哨兵時如何解決主從複製的問題的
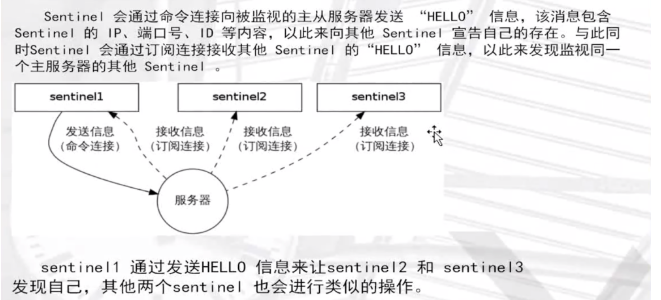
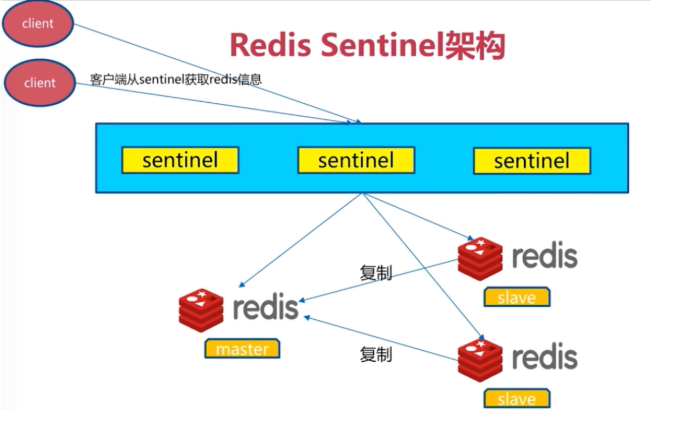

哨兵配置實戰
因為哨兵用來解決redis主從複製的問題的, 所以首先應該有一個redis主從的結構, 我使用了三個redis例項來模擬一主兩從的環境
建立三個redis的配置檔案, 分別用於啟動三個redis例項, 埠依次為6379, 6380, 6381
主庫
port 6379 daemonize yes logfile "/opt/redis-4.0.10/conf/shaobing/log/6379.log" dbfilename "dump-6379.rdb" dir "/opt/redis-4.0.10/conf/shaobing/data"
從庫1
port 6380 daemonize yes logfile "/opt/redis-4.0.10/conf/shaobing/log/6380.log" dbfilename "dump-6380.rdb" dir "/opt/redis-4.0.10/conf/shaobing/data" slaveof 127.0.0.1 6379 # 繫結主庫
從庫2
port 6381 daemonize yes logfile "/opt/redis-4.0.10/conf/shaobing/log/6381.log" dbfilename "dump-6381.rdb" dir "/opt/redis-4.0.10/conf/shaobing/data" # 指定主庫
啟動主, 從庫
[[email protected] 01:49 /opt/redis-4.0.10/conf/shaobing]# redis-server ./redis-6379.conf [[email protected] 01:50 /opt/redis-4.0.10/conf/shaobing]# redis-server ./redis-6380.conf [[email protected] 01:50 /opt/redis-4.0.10/conf/shaobing]# redis-server ./redis-6381.conf
檢視程序
[[email protected] 01:50 /opt/redis-4.0.10/conf/shaobing]# ps -ef | grep redis root 1502 1 0 01:50 ? 00:00:00 redis-server *:6379 root 1507 1 0 01:50 ? 00:00:00 redis-server *:6380 root 1513 1 0 01:50 ? 00:00:00 redis-server *:6381 root 1518 1413 0 01:50 pts/0 00:00:00 grep --color=auto redis
檢視主庫和從庫的身份角色, 以及連線狀態

配置哨兵
我配置了三個哨兵, 如下
哨兵的配置解釋:
// Sentinel節點的埠 port 26379 dir /var/redis/data/ logfile "26379.log" // 當前Sentinel節點監控 192.168.119.10:6379 這個主節點 // 2代表判斷主節點失敗至少需要2個Sentinel節點節點同意 // mymaster是主節點的別名 sentinel monitor mymaster 127.0.0.1 6379 2 //每個Sentinel節點都要定期PING命令來判斷Redis資料節點和其餘Sentinel節點是否可達,如果超過30000毫秒30s且沒有回覆,則判定不可達 sentinel down-after-milliseconds mymaster 30000 //當Sentinel節點集合對主節點故障判定達成一致時,Sentinel領導者節點會做故障轉移操作,選出新的主節點, 原來的從節點會向新的主節點發起復制操作,限制每次向新的主節點發起復制操作的從節點個數為1 sentinel parallel-syncs mymaster 1 //故障轉移超時時間為180000毫秒 sentinel failover-timeout mymaster 180000
redis-sentinel-26380.conf和redis-sentinel-26381.conf的配置僅僅差異是port(埠)的不同。然後啟動三個sentinel哨兵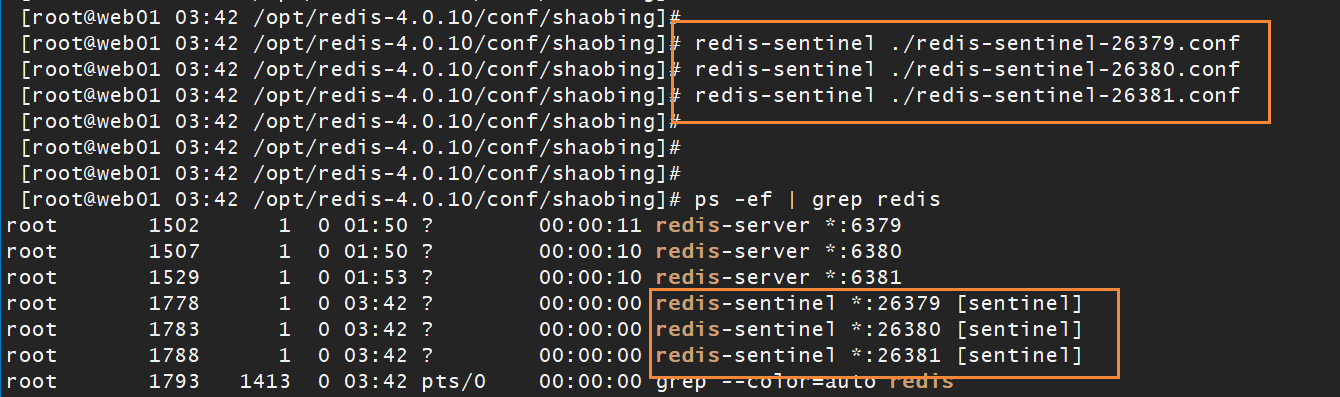
查哨兵的執行情況
從下圖可以看出三個哨兵的狀態都是OK, master是127.0.0.1:6379, 還有兩個slave, 三個哨兵
測試哨兵能否完成主從的切換
現在我把主庫6379 kill掉, 然後在檢視當前的主庫是誰, 根據我的配置是在30內檢測主庫沒有響應, 就會選舉一個新的主庫

可以看到自動切換了將6380切換成了主庫
到此結束......