
Python3 是如何解決棘手的字元編碼問題的?
阿新 • • 發佈:2018-12-11
Python3 最重要的一項改進之一就是解決了 Python2 中字串與字元編碼遺留下來的這個大坑。Python 編碼為什麼那麼蛋疼?已經介紹過 Python2 字串設計上的一些缺陷:
- 使用 ASCII 碼作為預設編碼方式,對中文處理很不友好。
- 把字串的牽強地分為 unicode 和 str 兩種型別,誤導開發者
當然這並不算 Bug,只要處理的時候多留心也可以避免這些坑。但在 Python3 兩個問題都很好的解決了。
首先,Python3 把系統預設編碼設定為 UTF-8
>>> import sys >>> sys.getdefaultencoding() 'utf-8' >>>
然後,文字字元和二進位制資料區分得更清晰,分別用 str 和 bytes 表示。文字字元全部用 str 型別表示,str 能表示 Unicode 字符集中所有字元,而二進位制位元組資料用一種全新的資料型別,用 bytes 來表示。
str
>>> a = "a" >>> a 'a' >>> type(a) <class 'str'> >>> b = "禪" >>> b '禪' >>> type(b) <class 'str'>
bytes
Python3 中,在字元引號前加‘b’,明確表示這是一個 bytes 型別的物件,實際上它就是一組二進位制位元組序列組成的資料,bytes 型別可以是 ASCII範圍內的字元和其它十六進位制形式的字元資料,但不能用中文等非ASCII字元表示。
>>> c = b'a' >>> c b'a' >>> type(c) <class 'bytes'> >>> d = b'\xe7\xa6\x85' >>> d b'\xe7\xa6\x85' >>>type(d) <class 'bytes'> >>> >>> e = b'禪' File "<stdin>", line 1 SyntaxError: bytes can only contain ASCII literal characters.
bytes 型別提供的操作和 str 一樣,支援分片、索引、基本數值運算等操作。但是 str 與 bytes 型別的資料不能執行 + 操作,儘管在py2中是可行的。
>>> b"a"+b"c" b'ac' >>> b"a"*2 b'aa' >>> b"abcdef\xd6"[1:] b'bcdef\xd6' >>> b"abcdef\xd6"[-1] 214 >>> b"a" + "b" Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: can't concat bytes to str
python2 與 python3 位元組與字元的對應關係
| python2 | python3 | 表現 | 轉換 | 作用 |
|---|---|---|---|---|
| str | bytes | 位元組 | encode | 儲存 |
| unicode | str | 字元 | decode | 顯示 |
encode 與 decode
str 與 bytes 之間的轉換可以用 encode 和從decode 方法。
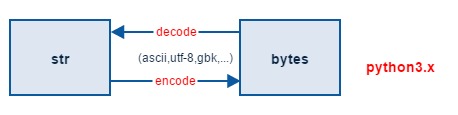
encode 負責字元到位元組的編碼轉換。預設使用 UTF-8 編碼準換。
>>> s = "Python之禪" >>> s.encode() b'Python\xe4\xb9\x8b\xe7\xa6\x85' >>> s.encode("gbk") b'Python\xd6\xae\xec\xf8'
decode 負責位元組到字元的解碼轉換,通用使用 UTF-8 編碼格式進行轉換。
>>> b'Python\xe4\xb9\x8b\xe7\xa6\x85'.decode() 'Python之禪' >>> b'Python\xd6\xae\xec\xf8'.decode("gbk") 'Python之禪'
關注公眾號「Python之禪」(id:vttalk)獲取最新文章
