
javaEE Lucene,全文檢索,站內搜尋,入門程式。索引庫的新增
阿新 • • 發佈:2018-12-11
注意:搜尋使用的分析器(分詞器)要和建立索引時使用的分析器一致。
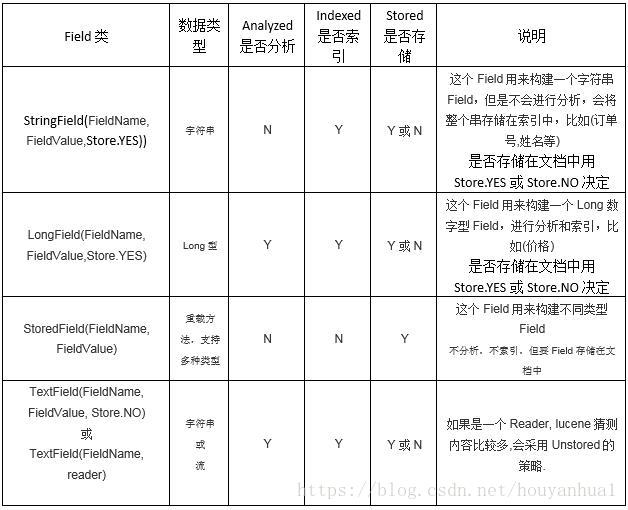
Field類(域物件):
Test.java(入門程式 測試類):
package com.xxx.lucene; import static org.junit.Assert.*; import java.io.File; import org.apache.commons.io.FileUtils; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.TokenStream; import org.apache.lucene.analysis.cjk.CJKAnalyzer; import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.analysis.tokenattributes.CharTermAttribute; import org.apache.lucene.analysis.tokenattributes.OffsetAttribute; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.document.Field.Store; import org.apache.lucene.document.LongField; import org.apache.lucene.document.StoredField; import org.apache.lucene.document.TextField; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexReader; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.index.Term; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TermQuery; import org.apache.lucene.search.TopDocs; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.apache.lucene.store.RAMDirectory; import org.apache.lucene.util.Version; import org.junit.Test; import org.wltea.analyzer.lucene.IKAnalyzer; //Lucene入門案例。 建立索引、查詢索引 public class Test { // 建立索引 @Test public void testIndex() throws Exception { // 第一步:建立一個java工程,並匯入jar包。 // 第二步:建立一個indexwriter物件。 // 1)指定索引庫的存放位置Directory物件 // 2)指定一個分析器,對文件內容進行分析(分詞)。 Directory directory = FSDirectory.open(new File("D:\\temp\\index")); // Directory directory = new RAMDirectory(); //儲存索引到記憶體中 (記憶體索引庫) //Analyzer analyzer = new StandardAnalyzer(); // 官方推薦(解析英文) Analyzer analyzer = new IKAnalyzer(); // 推薦使用的中文分析器 IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer); //Version根據匯入的Jar包選擇,LATEST表示最新的。 IndexWriter indexWriter = new IndexWriter(directory, config); // 第三步:建立field物件和Document物件,將field新增到document物件中。 File f = new File("D:\\Lucene&solr\\searchsource"); File[] listFiles = f.listFiles(); for (File file : listFiles) { // 建立document物件。 Document document = new Document(); // 檔名稱 (Document物件的field物件) String file_name = file.getName(); Field fileNameField = new TextField("fileName", file_name, Store.YES); // 檔案大小 (field) long file_size = FileUtils.sizeOf(file); Field fileSizeField = new LongField("fileSize", file_size, Store.YES); // 檔案路徑 (field) String file_path = file.getPath(); Field filePathField = new StoredField("filePath", file_path); // 檔案內容 (field) String file_content = FileUtils.readFileToString(file); Field fileContentField = new TextField("fileContent", file_content, Store.NO); document.add(fileNameField); document.add(fileSizeField); document.add(filePathField); document.add(fileContentField); // 第四步:使用indexwriter物件將document物件寫入索引庫,此過程進行索引建立。並將索引和document物件寫入索引庫。 indexWriter.addDocument(document); } // 第五步:關閉IndexWriter物件。 indexWriter.close(); } // 查詢索引 @Test public void testSearch() throws Exception { // 第一步:建立一個Directory物件,也就是索引庫存放的位置。 Directory directory = FSDirectory.open(new File("D:\\temp\\index"));// 磁碟 // 第二步:建立一個indexReader物件,需要指定Directory物件。 IndexReader indexReader = DirectoryReader.open(directory); // 第三步:建立一個indexsearcher物件,需要指定IndexReader物件 IndexSearcher indexSearcher = new IndexSearcher(indexReader); // 第四步:建立一個TermQuery物件,指定查詢的域(field)和查詢的關鍵詞。 Query query = new TermQuery(new Term("fileName", "abc")); //fileName是(field)域名,abc是(域值)搜尋關鍵字 // 第五步:執行查詢。 (查詢索引,根據索引查詢文件Document的id) TopDocs topDocs = indexSearcher.search(query, 10); //10表示前10條 // 第六步:返回查詢結果。遍歷查詢結果並輸出。 ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { int doc = scoreDoc.doc; //獲取文件Document的id。(從0開始,自增的id) Document document = indexSearcher.doc(doc); //根據id查詢文件。 // 檔名稱 String fileName = document.get("fileName"); //根據域名獲取域值 System.out.println(fileName); // 檔案內容 String fileContent = document.get("fileContent"); System.out.println(fileContent); // 檔案大小 String fileSize = document.get("fileSize"); System.out.println(fileSize); // 檔案路徑 String filePath = document.get("filePath"); System.out.println(filePath); System.out.println("------------"); } // 第七步:關閉IndexReader物件(流) indexReader.close(); } // 檢視各種分析器的分詞效果(程式碼瞭解) @Test public void testTokenStream() throws Exception { // 建立一個標準分析器物件 //Analyzer analyzer = new StandardAnalyzer(); //標準分詞器 //Analyzer analyzer = new CJKAnalyzer(); //中日韓分詞器 (二分法分詞) //Analyzer analyzer = new SmartChineseAnalyzer(); //需要匯入Jar包: lucene-analyzers-smartcn-4.10.3.jar (不能擴充套件詞庫,禁用詞庫同義詞庫不好處理) Analyzer analyzer = new IKAnalyzer(); //推薦使用的中文分詞器。 (需要匯入IKAnalyzer2012FF_u1.jar;IKAnalyzer.cfg.xml、src/ext.dic、src/stopword.dic) // 獲得tokenStream物件 // 第一個引數:域名,可以隨便給一個 // 第二個引數:要分析的文字內容 //TokenStream tokenStream = analyzer.tokenStream("test", // "The Spring Framework provides a comprehensive programming and configuration model."); TokenStream tokenStream = analyzer.tokenStream("test", "高富帥可以用二維表結構來邏輯表達實現的資料"); // 新增一個引用,可以獲得每個關鍵詞 CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class); // 新增一個偏移量的引用,記錄了關鍵詞的開始位置以及結束位置 OffsetAttribute offsetAttribute = tokenStream.addAttribute(OffsetAttribute.class); // 將指標調整到列表的頭部 tokenStream.reset(); // 遍歷關鍵詞列表,通過incrementToken方法判斷列表是否結束 while (tokenStream.incrementToken()) { // 關鍵詞的起始位置 System.out.println("start->" + offsetAttribute.startOffset()); // 取關鍵詞 System.out.println(charTermAttribute); // 結束位置 System.out.println("end->" + offsetAttribute.endOffset()); } tokenStream.close(); } }