
[Pytorch]PyTorch Dataloader自定義資料讀取
整理一下看到的自定義資料讀取的方法,較好的有一下三篇文章, 其實自定義的方法就是把現有資料集的train和test分別用 含有影象路徑與label的list返回就好了,所以需要根據資料集隨機應變。
所有圖片都在一個資料夾1
之前剛開始用的時候,寫Dataloader遇到不少坑。網上有一些教程 分為all images in one folder 和 each class one folder。後面的那種寫的人比較多,我寫一下前面的這種,程式化的東西,每次不同的任務改幾個引數就好。
等訓練的時候寫一篇文章把2333
一.已有的東西
舉例子:用kaggle上的一個dog breed的資料集為例。資料資料夾裡面有三個子目錄
test: 幾千張圖片,沒有標籤,測試集
train: 10222張狗的圖片,全是jpg,大小不一,有長有寬,基本都在400×300以上
labels.csv : excel表格, 圖片名稱+品種名稱

我喜歡先用pandas把表格資訊讀出來看一看
import pandas as pd
import numpy as np
df = pd.read_csv('./dog_breed/labels.csv')
print(df.info())
print(df.head())
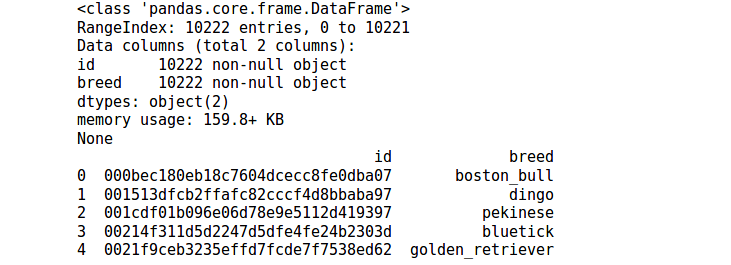
看到,一共有10222個數據,id對應的是圖片的名字,但是沒有後綴 .jpg。 breed對應的是犬種。
二.預處理
我們要做的事情是:
1)得到一個長 list1 : 裡面是每張圖片的路徑
2)另外一個長list2: 裡面是每張圖片對應的標籤(整數),順序要和list1對應。
3)把這兩個list切分出來一部分作為驗證集
1)看看一共多少個breed,把每種breed名稱和一個數字編號對應起來:
from pandas import Series,DataFrame breed = df['breed'] breed_np = Series.as_matrix(breed) print(type(breed_np) ) print(breed_np.shape) #(10222,) #看一下一共多少不同種類 breed_set = set(breed_np) print(len(breed_set)) #120 #構建一個編號與名稱對應的字典,以後輸出的數字要變成名字的時候用: breed_120_list = list(breed_set) dic = {} for i in range(120): dic[ breed_120_list[i] ] = i
2)處理id那一列,分割成兩段:
file = Series.as_matrix(df["id"])
print(file.shape)
import os
file = [i+".jpg" for i in file]
file = [os.path.join("./dog_breed/train",i) for i in file ]
file_train = file[:8000]
file_test = file[8000:]
print(file_train)
np.save( "file_train.npy" ,file_train )
np.save( "file_test.npy" ,file_test )
裡面就是圖片的路徑了

3)處理breed那一列,分成兩段:
breed = Series.as_matrix(df["breed"])
print(breed.shape)
number = []
for i in range(10222):
number.append( dic[ breed[i] ] )
number = np.array(number)
number_train = number[:8000]
number_test = number[8000:]
np.save( "number_train.npy" ,number_train )
np.save( "number_test.npy" ,number_test )
三.Dataloader
我們已經有了圖片路徑的list,target編號的list。填到Dataset類裡面就行了。
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
preprocess = transforms.Compose([
#transforms.Scale(256),
#transforms.CenterCrop(224),
transforms.ToTensor(),
normalize
])
def default_loader(path):
img_pil = Image.open(path)
img_pil = img_pil.resize((224,224))
img_tensor = preprocess(img_pil)
return img_tensor
#當然出來的時候已經全都變成了tensor
class trainset(Dataset):
def __init__(self, loader=default_loader):
#定義好 image 的路徑
self.images = file_train
self.target = number_train
self.loader = loader
def __getitem__(self, index):
fn = self.images[index]
img = self.loader(fn)
target = self.target[index]
return img,target
def __len__(self):
return len(self.images)
我們看一下程式碼,自定義Dataset只需要最下面一個class,繼承自Dataset類。有三個私有函式
def __init__(self, loader=default_loader):
這個裡面一般要初始化一個loader(程式碼見上面),一個images_path的列表,一個target的列表
def __getitem__(self, index):
這裡嗎就是在給你一個index的時候,你返回一個圖片的tensor和target的tensor,使用了loader方法,經過 歸一化,剪裁,型別轉化,從影象變成tensor
def __len__(self):
return你所有資料的個數
這三個綜合起來看呢,其實就是你告訴它你所有資料的長度,它每次給你返回一個shuffle過的index,以這個方式遍歷資料集,通過 __getitem__(self, index)返回一組你要的(input,target)
四.使用
例項化一個dataset,然後用Dataloader 包起來
train_data = trainset()
trainloader = DataLoader(train_data, batch_size=4,shuffle=True)
所有圖片都在一個資料夾2
在上一篇部落格PyTorch學習之路(level1)——訓練一個影象分類模型中介紹瞭如何用PyTorch訓練一個影象分類模型,建議先看懂那篇部落格後再看這篇部落格。在那份程式碼中,採用torchvision.datasets.ImageFolder這個介面來讀取影象資料,該介面預設你的訓練資料是按照一個類別存放在一個資料夾下。但是有些情況下你的影象資料不是這樣維護的,比如一個資料夾下面各個類別的影象資料都有,同時用一個對應的標籤檔案,比如txt檔案來維護影象和標籤的對應關係,在這種情況下就不能用torchvision.datasets.ImageFolder來讀取資料了,需要自定義一個數據讀取介面。另外這篇部落格最後還順帶介紹如何儲存模型和多GPU訓練。
怎麼做呢?
先來看看torchvision.datasets.ImageFolder這個類是怎麼寫的,主要程式碼如下,想詳細瞭解的可以看:官方github程式碼。
看起來很複雜,其實非常簡單。繼承的類是torch.utils.data.Dataset,主要包含三個方法:初始化__init__,獲取影象__getitem__,資料集數量 __len__。__init__方法中先通過find_classes函式得到分類的類別名(classes)和類別名與數字類別的對映關係字典(class_to_idx)。然後通過make_dataset函式得到imags,這個imags是一個列表,其中每個值是一個tuple,每個tuple包含兩個元素:影象路徑和標籤。剩下的就是一些賦值操作了。在__getitem__方法中最重要的就是 img = self.loader(path)這行,表示資料讀取,可以從__init__方法中看出self.loader採用的是default_loader,這個default_loader的核心就是用python的PIL庫的Image模組來讀取影象資料。
class ImageFolder(data.Dataset):
"""A generic data loader where the images are arranged in this way: ::
root/dog/xxx.png
root/dog/xxy.png
root/dog/xxz.png
root/cat/123.png
root/cat/nsdf3.png
root/cat/asd932_.png
Args:
root (string): Root directory path.
transform (callable, optional): A function/transform that takes in an PIL image
and returns a transformed version. E.g, ``transforms.RandomCrop``
target_transform (callable, optional): A function/transform that takes in the
target and transforms it.
loader (callable, optional): A function to load an image given its path.
Attributes:
classes (list): List of the class names.
class_to_idx (dict): Dict with items (class_name, class_index).
imgs (list): List of (image path, class_index) tuples
"""
def __init__(self, root, transform=None, target_transform=None,
loader=default_loader):
classes, class_to_idx = find_classes(root)
imgs = make_dataset(root, class_to_idx)
if len(imgs) == 0:
raise(RuntimeError("Found 0 images in subfolders of: " + root + "\n"
"Supported image extensions are: " + ",".join(IMG_EXTENSIONS)))
self.root = root
self.imgs = imgs
self.classes = classes
self.class_to_idx = class_to_idx
self.transform = transform
self.target_transform = target_transform
self.loader = loader
def __getitem__(self, index):
"""
Args:
index (int): Index
Returns:
tuple: (image, target) where target is class_index of the target class.
"""
path, target = self.imgs[index]
img = self.loader(path)
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return img, target
def __len__(self):
return len(self.imgs)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
稍微看下default_loader函式,該函式主要分兩種情況呼叫兩個函式,一般採用pil_loader函式。
def pil_loader(path):
with open(path, 'rb') as f:
with Image.open(f) as img:
return img.convert('RGB')
def accimage_loader(path):
import accimage
try:
return accimage.Image(path)
except IOError:
# Potentially a decoding problem, fall back to PIL.Image
return pil_loader(path)
def default_loader(path):
from torchvision import get_image_backend
if get_image_backend() == 'accimage':
return accimage_loader(path)
else:
return pil_loader(path)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
看懂了ImageFolder這個類,就可以自定義一個你自己的資料讀取介面了。
首先在PyTorch中和資料讀取相關的類基本都要繼承一個基類:torch.utils.data.Dataset。然後再改寫其中的__init__、__len__、__getitem__等方法即可。
下面假設img_path是你的影象資料夾,該資料夾下面放了所有影象資料(包括訓練和測試),然後txt_path下面放了train.txt和val.txt兩個檔案,txt檔案中每行都是影象路徑,tab鍵,標籤。所以下面程式碼的__init__方法中self.img_name和self.img_label的讀取方式就跟你資料的存放方式有關,你可以根據你實際資料的維護方式做調整。__getitem__方法沒有做太大改動,依然採用default_loader方法來讀取影象。最後在Transform中將每張影象都封裝成Tensor。
class customData(Dataset):
def __init__(self, img_path, txt_path, dataset = '', data_transforms=None, loader = default_loader):
with open(txt_path) as input_file:
lines = input_file.readlines()
self.img_name = [os.path.join(img_path, line.strip().split('\t')[0]) for line in lines]
self.img_label = [int(line.strip().split('\t')[-1]) for line in lines]
self.data_transforms = data_transforms
self.dataset = dataset
self.loader = loader
def __len__(self):
return len(self.img_name)
def __getitem__(self, item):
img_name = self.img_name[item]
label = self.img_label[item]
img = self.loader(img_name)
if self.data_transforms is not None:
try:
img = self.data_transforms[self.dataset](img)
except:
print("Cannot transform image: {}".format(img_name))
return img, label
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
定義好了資料讀取介面後,怎麼用呢?
在程式碼中可以這樣呼叫。
image_datasets = {x: customData(img_path='/ImagePath',
txt_path=('/TxtFile/' + x + '.txt'),
data_transforms=data_transforms,
dataset=x) for x in ['train', 'val']}
- 1
- 2
- 3
- 4
這樣返回的image_datasets就和用torchvision.datasets.ImageFolder類返回的資料型別一樣,有點狸貓換太子的感覺,這就是在第一篇部落格中說的寫程式碼類似搭積木的感覺。
有了image_datasets,然後依然用torch.utils.data.DataLoader類來做進一步封裝,將這個batch的影象資料和標籤都分別封裝成Tensor。
dataloders = {x: torch.utils.data.DataLoader(image_datasets[x],
batch_size=batch_size,
shuffle=True) for x in ['train', 'val']}
- 1
- 2
- 3
另外,每次迭代生成的模型要怎麼儲存呢?非常簡單,那就是用torch.save。輸入就是你的模型和要儲存的路徑及模型名稱,如果這個output資料夾沒有,可以手動新建一個或者在程式碼裡面新建。
torch.save(model, 'output/resnet_epoch{}.pkl'.format(epoch))
- 1
最後,關於多GPU的使用,PyTorch支援多GPU訓練模型,假設你的網路是model,那麼只需要下面一行程式碼(呼叫 torch.nn.DataParallel介面)就可以讓後續的模型訓練在0和1兩塊GPU上訓練,加快訓練速度。
model = torch.nn.DataParallel(model, device_ids=[0,1])
- 1
完整程式碼請移步:Github
每個類的圖片放在一個資料夾
這是一個適合PyTorch入門者看的部落格。PyTorch的文件質量比較高,入門較為容易,這篇部落格選取官方連結裡面的例子,介紹如何用PyTorch訓練一個ResNet模型用於影象分類,程式碼邏輯非常清晰,基本上和許多深度學習框架的程式碼思路類似,非常適合初學者想上手PyTorch訓練模型(不必每次都跑mnist的demo了)。接下來從個人使用角度加以解釋。解釋的思路是從資料匯入開始到模型訓練結束,基本上就是搭積木的方式來寫程式碼。
首先是資料匯入部分,這裡採用官方寫好的torchvision.datasets.ImageFolder介面實現資料匯入。這個介面需要你提供影象所在的資料夾,就是下面的data_dir=‘/data’這句,然後對於一個分類問題,這裡data_dir目錄下一般包括兩個資料夾:train和val,每個檔案件下面包含N個子資料夾,N是你的分類類別數,且每個子資料夾裡存放的就是這個類別的影象。這樣torchvision.datasets.ImageFolder就會返回一個列表(比如下面程式碼中的image_datasets[‘train’]或者image_datasets[‘val]),列表中的每個值都是一個tuple,每個tuple包含影象和標籤資訊。
data_dir = '/data'
image_datasets = {x: datasets.ImageFolder(
os.path.join(data_dir, x),
data_transforms[x]),
for x in ['train', 'val']}
- 1
- 2
- 3
- 4
- 5
另外這裡的data_transforms是一個字典,如下。主要是進行一些影象預處理,比如resize、crop等。實現的時候採用的是torchvision.transforms模組,比如torchvision.transforms.Compose是用來管理所有transforms操作的,torchvision.transforms.RandomSizedCrop是做crop的。需要注意的是對於torchvision.transforms.RandomSizedCrop和transforms.RandomHorizontalFlip()等,輸入物件都是PIL Image,也就是用python的PIL庫讀進來的影象內容,而transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])的作用物件需要是一個Tensor,因此在transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])之前有一個 transforms.ToTensor()就是用來生成Tensor的。另外transforms.Scale(256)其實就是resize操作,目前已經被transforms.Resize類取代了。
data_transforms = {
'train': transforms.Compose([
transforms.RandomSizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Scale(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
前面torchvision.datasets.ImageFolder只是返回list,list是不能作為模型輸入的,因此在PyTorch中需要用另一個類來封裝list,那就是:torch.utils.data.DataLoader。torch.utils.data.DataLoader類可以將list型別的輸入資料封裝成Tensor資料格式,以備模型使用。注意,這裡是對影象和標籤分別封裝成一個Tensor。這裡要提到另一個很重要的類:torch.utils.data.Dataset,這是一個抽象類,在pytorch中所有和資料相關的類都要繼承這個類來實現。比如前面說的torchvision.datasets.ImageFolder類是這樣的,以及這裡的torch.util.data.DataLoader類也是這樣的。所以當你的資料不是按照一個類別一個資料夾這種方式儲存時,你就要自定義一個類來讀取資料,自定義的這個類必須繼承自torch.utils.data.Dataset這個基類,最後同樣用torch.utils.data.DataLoader封裝成Tensor。
dataloders = {x: torch.utils.data.DataLoader(image_datasets[x],
batch_size=4,
shuffle=True,
num_workers=4)
for x in ['train', 'val']}
- 1
- 2
- 3
- 4
- 5
生成dataloaders後再有一步就可以作為模型的輸入了,那就是將Tensor資料型別封裝成Variable資料型別,來看下面這段程式碼。dataloaders是一個字典,dataloders[‘train’]存的就是訓練的資料,這個for迴圈就是從dataloders[‘train’]中讀取batch_size個數據,batch_size在前面生成dataloaders的時候就設定了。因此這個data裡面包含影象資料(inputs)這個Tensor和標籤(labels)這個Tensor。然後用torch.autograd.Variable將Tensor封裝成模型真正可以用的Variable資料型別。
為什麼要封裝成Variable呢?在pytorch中,torch.tensor和torch.autograd.Variable是兩種比較重要的資料結構,Variable可以看成是tensor的一種包裝,其不僅包含了tensor的內容,還包含了梯度等資訊,因此在神經網路中常常用Variable資料結構。那麼怎麼從一個Variable型別中取出tensor呢?也很簡單,比如下面封裝後的inputs是一個Variable,那麼inputs.data就是對應的tensor。
for data in dataloders['train']:
inputs, labels = data
if use_gpu:
inputs = Variable(inputs.cuda())
labels = Variable(labels.cuda())
else:
inputs, labels = Variable(inputs), Variable(labels)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
封裝好了資料後,就可以作為模型的輸入了。所以要先匯入你的模型。在PyTorch中已經預設為大家準備了一些常用的網路結構,比如分類中的VGG,ResNet,DenseNet等等,可以用torchvision.models模組來匯入。比如用torchvision.models.resnet18(pretrained=True)來匯入ResNet18網路,同時指明匯入的是已經預訓練過的網路。因為預訓練網路一般是在1000類的ImageNet資料集上進行的,所以要遷移到你自己資料集的2分類,需要替換最後的全連線層為你所需要的輸出。因此下面這三行程式碼進行的就是用models模組匯入resnet18網路,然後獲取全連線層的輸入channel個數,用這個channel個數和你要做的分類類別數(這裡是2)替換原來模型中的全連線層。這樣網路結果也準備好。
model = models.resnet18(pretrained=True)
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 2)
- 1
- 2
- 3
但是隻有網路結構和資料還不足以讓程式碼執行起來,還需要定義損失函式。在PyTorch中採用torch.nn模組來定義網路的所有層,比如卷積、降取樣、損失層等等,這裡採用交叉熵函式,因此可以這樣定義:
criterion = nn.CrossEntropyLoss()
- 1
然後你還需要定義優化函式,比如最常見的隨機梯度下降,在PyTorch中是通過torch.optim模組來實現的。另外這裡雖然寫的是SGD,但是因為有momentum,所以是Adam的優化方式。這個類的輸入包括需要優化的引數:model.parameters(),學習率,還有Adam相關的momentum引數。現在很多優化方式的預設定義形式就是這樣的。
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
- 1
然後一般還會定義學習率的變化策略,這裡採用的是torch.optim.lr_scheduler模組的StepLR類,表示每隔step_size個epoch就將學習率降為原來的gamma倍。
scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
- 1
準備工作終於做完了,要開始訓練了。
首先訓練開始的時候需要先更新下學習率,這是因為我們前面制定了學習率的變化策略,所以在每個epoch開始時都要更新下:
scheduler.step()
- 1
然後設定模型狀態為訓練狀態:
model.train(True)
- 1
然後先將網路中的所有梯度置0:
optimizer.zero_grad()
- 1
然後就是網路的前向傳播了:
outputs = model(inputs)
- 1
然後將輸出的outputs和原來匯入的labels作為loss函式的輸入就可以得到損失了:
loss = criterion(outputs, labels)
- 1
輸出的outputs也是torch.autograd.Variable格式,得到輸出後(網路的全連線層的輸出)還希望能到到模型預測該樣本屬於哪個類別的資訊,這裡採用torch.max。torch.max()的第一個輸入是tensor格式,所以用outputs.data而不是outputs作為輸入;第二個引數1是代表dim的意思,也就是取每一行的最大值,其實就是我們常見的取概率最大的那個index;第三個引數loss也是torch.autograd.Variable格式。
_, preds = torch.max(outputs.data, 1)
- 1
計算得到loss後就要回傳損失。要注意的是這是在訓練的時候才會有的操作,測試時候只有forward過程。
loss.backward()
- 1
回傳損失過程中會計算梯度,然後需要根據這些梯度更新引數,optimizer.step()就是用來更新引數的。optimizer.step()後,你就可以從optimizer.param_groups[0][‘params’]裡面看到各個層的梯度和權值資訊。
optimizer.step()
- 1
這樣一個batch資料的訓練就結束了!當你不斷重複這樣的訓練過程,最終就可以達到你想要的結果了。
另外如果你有gpu可用,那麼包括你的資料和模型都可以在gpu上操作,這在PyTorch中也非常簡單。判斷你是否有gpu可以用可以通過下面這行程式碼,如果有,則use_gpu是true。
use_gpu = torch.cuda.is_available()
- 1
完整程式碼請移步:Github