
Java-垃圾回收(GC)詳解
概述
GC需要完成的3件事 :
- 哪些記憶體需要回收
- 什麼時候回收
- 如何回收
判斷物件是否存活演算法
引用計數演算法(Reference Counting)
- 給物件中新增一個引用計數器, 每當有一個地方引用它時, 計數器值就加1; 當引用失效時, 計數器值就減1;任何時刻計數器為0的物件就是不可能再被使用的
- 存在迴圈引用問題
- 由於迴圈引用問題, 所以主流的Java虛擬機器沒有使用引用計數演算法來管理記憶體的
可達性分析演算法(Reachability Analysis)
通過一系列的稱為"GC Roots"的物件作為起始點, 從這些節點開始向下搜尋, 搜尋所走過的路徑稱為引用鏈(Reference Chain), 當一個物件到GC Roots沒有任何引用鏈相連時, 則證明此物件是不可用的。如下圖所示, object5, object6, object7雖然相互有關聯, 但是它們到GC Roots是不可達的, 所以它們會被判定為可回收物件
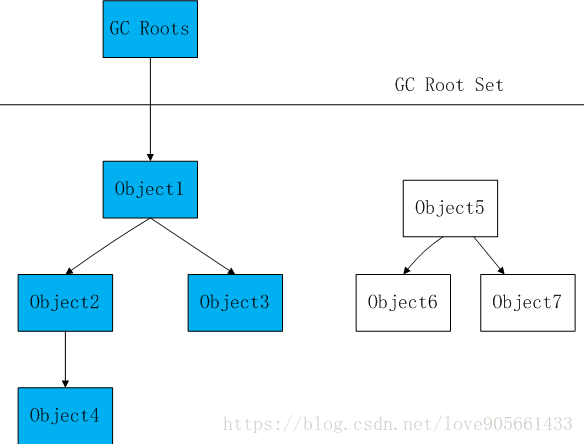
在Java中,可作為GC Roots的物件包括下面幾種 :
- 虛擬機器棧(棧幀中的本地變量表)中引用的物件
- 方法區中類靜態屬性引用的物件
- 方法區中常量引用的物件
- 本地方法中JNI(即一般說的Native方法)引用的物件
引用型別
- 強引用(Strong Reference) : 強引用就是指在程式碼中普遍存在的, 類似"Object obj = new Object()"這類的引用, 只要強引用還存在, 垃圾收集器永遠不會回收掉被引用的物件
- 軟引用(Soft Reference) : 軟引用是用來描述一些還有用但並非必需的物件。對於軟引用關聯著的物件, 在系統將要發生記憶體溢位異常之前, 將會把這些物件列進回收範圍之中進行第二次回收。如果這次回收還沒有足夠的記憶體, 才會丟擲記憶體溢位異常。
- 弱引用(Weak Reference) : 弱引用也是用來描述非必需物件的, 但是它的強度比軟引用更弱一些, 被弱引用關聯的物件只能生存到下一次垃圾回收發生之前。當垃圾收集器工作時, 無論當前記憶體是否足夠, 都會回收掉只被弱引用關聯的物件。使用WeakReference類來實現弱引用。
- 虛引用(Phantom Reference) : 虛引用也稱為幽靈引用或者幻影引用, 它是最弱的一種引用關係。一個物件是否有虛引用的存在, 完全不會對其生存時間構成影響, 也無法通過虛引用來取得一個物件例項。為一個物件設定虛引用關聯的唯一目的就是能在這個物件被GC回收時收到一個系統通知。使用PhantomReference類實現虛引用。
引用強度 : 強引用 > 軟引用 > 弱引用 > 虛引用
回收方法區
方法區的垃圾回收主要回收兩部分內容, 廢棄常量和無用的類。回收廢棄常量與回收Java堆中的物件很類似, 就是沒有任何物件引用這個常量, 這個常量就是廢棄常量。
無用的類判斷方法 :
- 該類的所有例項都已經被回收, 也就是Java堆中不存在該類的任何例項
- 載入該類的ClassLoader已經被回收
- 該類對應的java.lang.Class物件沒有任何地方被引用, 無法在任何地方通過反射訪問該類的方法
虛擬機器可以對滿足上面三個條件的無用類進行回收, 這裡說"可以", 而並不是和物件一樣, 不使用了就必然回收。在大量使用反射, 動態代理, CGlib等ByteCode框架; 動態生成JSP以及OSGI這類頻繁自定義ClassLoader的場景都需要虛擬機器具備類解除安裝功能, 以保證永久代不會溢位。
垃圾收集演算法
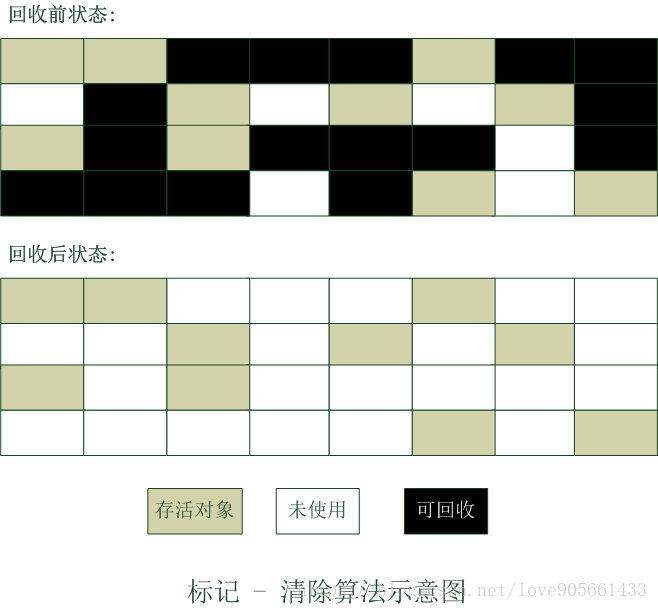
標記 - 清除演算法
- 標記 : 首先標記出需要回收的物件
- 清除 : 在標記完成後統一回收被標記的物件
缺點 :
- 效率問題, 標記和清除兩個過程的效率都不高
- 空間問題, 標記清除之後會產生大量不連續的記憶體碎片, 空間碎片太多可能會導致以後在程式執行過程中需要分配較大物件時, 無法找到足夠的連續記憶體而不得不提前觸發另一次垃圾收集動作
標記-清除演算法示意圖 :
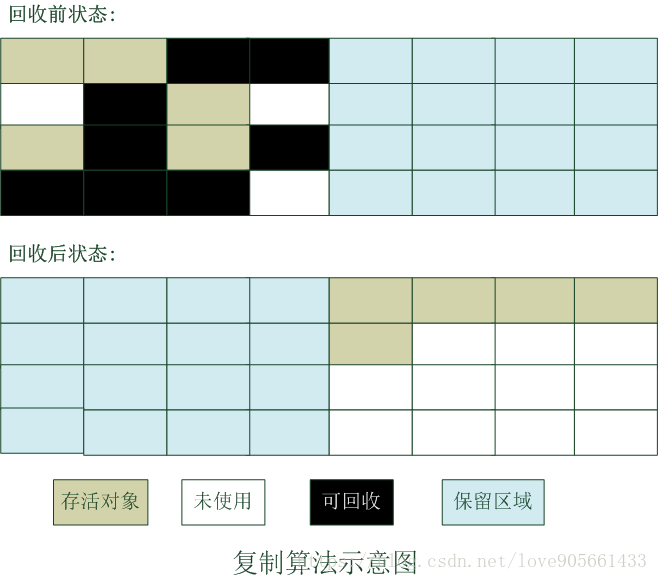
複製演算法
-
將記憶體劃分為大小相等的兩塊, 每次只使用其中一塊
-
當這一塊記憶體用完時, 就將還存活的物件複製到另外一塊。
-
然後把已使用的記憶體整個回收。
-
新生代收集演算法
優點 :
不存在記憶體碎片問題, 記憶體分配時只需要移動堆頂指標, 按順序分配記憶體即可, 實現簡單, 執行高效
缺點 :
- 原理上來講,浪費了一半的記憶體空間(事實上商用的虛擬機器只會浪費少量的記憶體空間, 下面會有說明)
- 物件存活率較高時就要進行較多的複製操作, 效率將會變低
- 如果不想浪費50%的空間, 就需要有額外的空間進行分配擔保, 以應對被使用記憶體中所有物件都100%存活的極端情況, 所以老年代一般不能直接選用這種演算法。
複製演算法示意圖 :
優化策略 :
現在的商業虛擬機器都採用這種演算法回收新生代記憶體, 但是並不是按照1:1的比例來劃分記憶體空間的, 具體的策略如下:
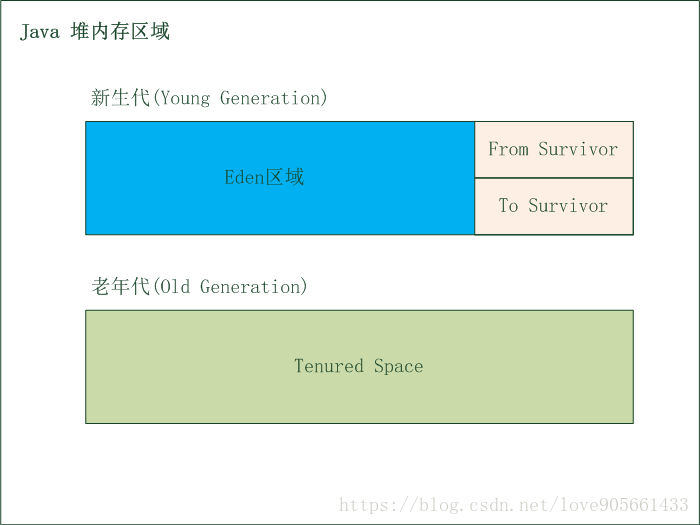
- 將記憶體分為一塊較大的Eden空間和兩塊較小的Survivor空間
- 每次使用Eden空間和其中一塊Survivor空間
- 當回收時, 將Eden空間和已使用的Survivor空間中存活的物件複製到另一塊未使用的Survivor空間中
- 如果未使用的Survivor空間中記憶體不足以存放Eden空間和已使用的Survivor空間的存活物件, 這些物件通過記憶體分配擔保機制直接進入老年代
- 最後清理掉Eden空間和剛使用過的Survivor空間
- HotSpot虛擬機器(JDK預設的虛擬機器)預設Eden和Survivor的比例為8:1, 也就是每次新生代中可用記憶體空間為整個新生代的90%, 只有10%的空間會被"浪費"
下面是HotSpot中堆記憶體空間分配 :
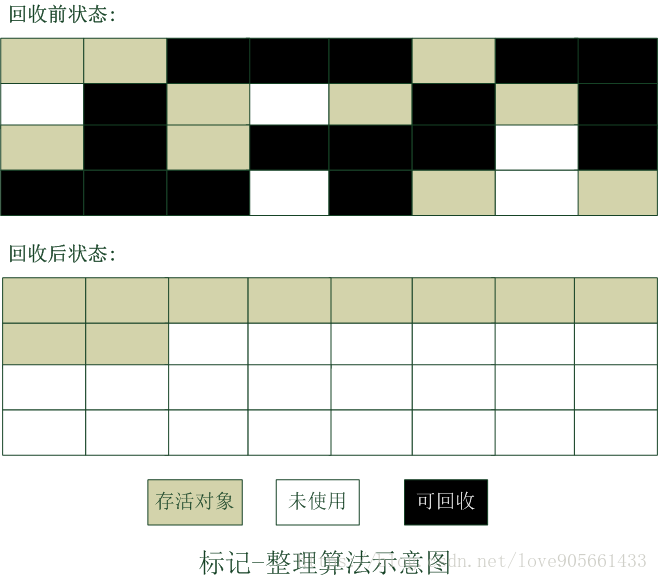
標記 - 整理演算法
- 標記 : 標記過程與標記-清除演算法一樣
- 整理 : 將所有存活物件都向一端移動
- 清除 : 清理掉存活物件邊界以為的記憶體
標記 - 整理演算法示意圖 :
分代收集演算法
- 當前的商業虛擬機器都採用"分代收集演算法"
- 根據物件存活週期的不同, 將記憶體劃分為幾塊, 一般是將Java堆分為新生代和老年代, 根據不同的年代特點使用不同的垃圾收集演算法
- 新生代 : 每次垃圾收集時都發現有大批物件死去, 只有少量存活, 一般使用複製演算法, 只需付出少量存活物件的複製成本就可以完成收集
- 老年代 : 物件存活率較高; 沒有額外的空間進行空間分配擔保; 所以在老年代中必須使用標記 - 清除或標記 - 整理演算法來進行回收
參考<深入理解Java虛擬機器>