
java爬蟲Jsoup簡單學習
啥是jsoup?
jsoup我就不巴拉巴拉了,具體介紹百度或者去官網檢視。
jsoup怎麼用?
jsoup和jquery的操作相似,下面簡單使用一下。
使用jsoup大概也就以下幾個步驟:
- 獲取整個html文件
- 使用選擇器獲取需要爬的資料節點集合
- 迴圈遍歷使用選擇器獲取相應資料
例項
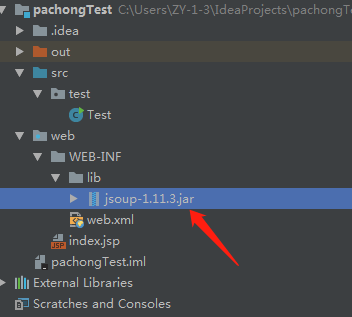
這是專案結構也就普通的一個測試專案,需要匯入jsoup-x.xx.x.jar包,然後建一個實體類。
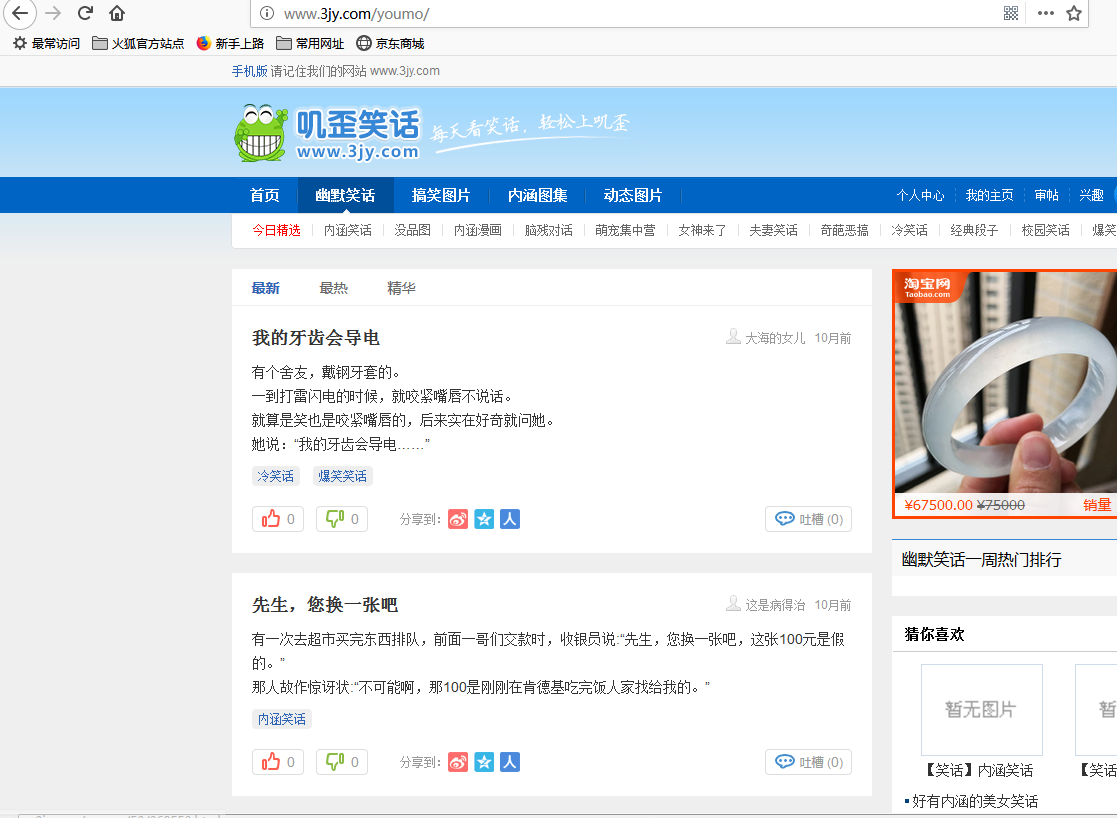
我們就拿這個嘰歪笑話來說。
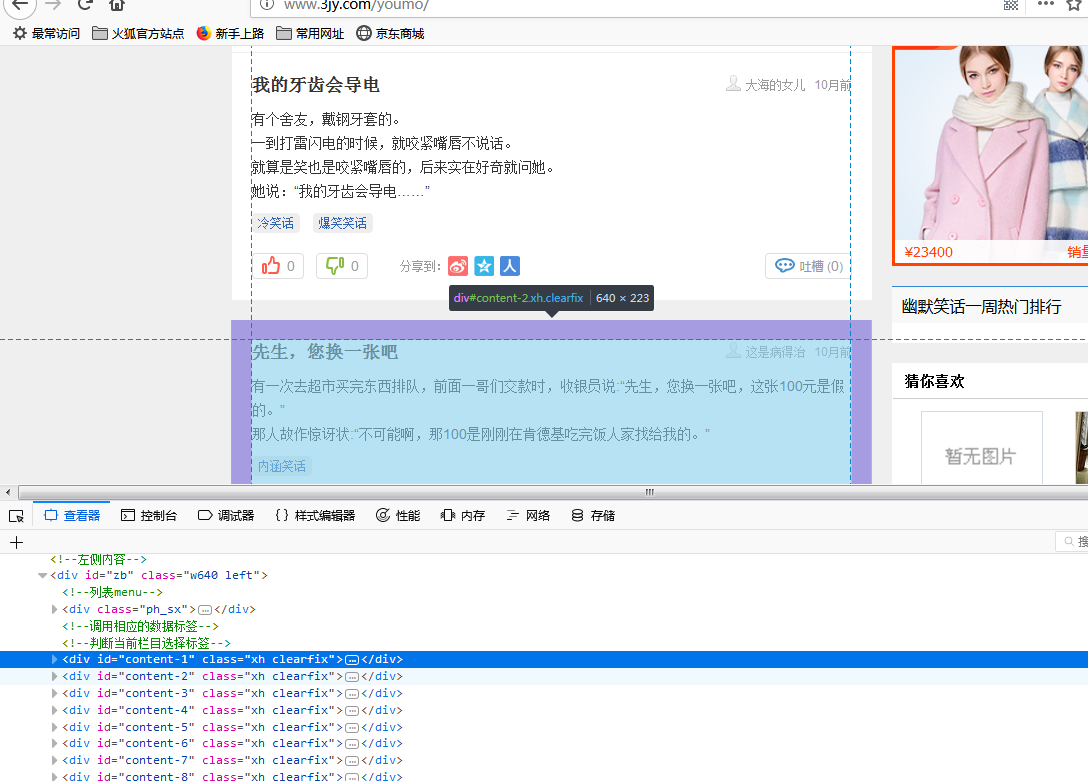
每一個笑話對應一個div。
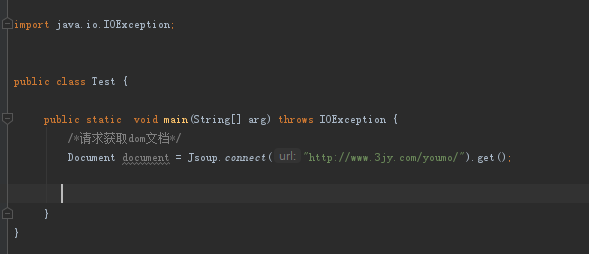
建立一個測試main方法通過Jsoup.conect(url).get();方法獲取相應整個html頁面

然後通過select方法。select方法跟jquery選擇器類似,可以通過 .,#,屬性等選擇標籤。
注意:這裡選擇器選擇所有class為xh的節點也就是上文所有的笑話節點集合
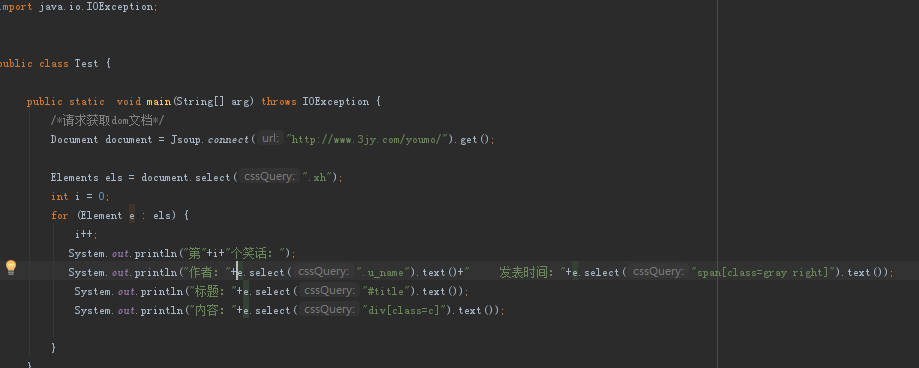
然後迴圈節點集合
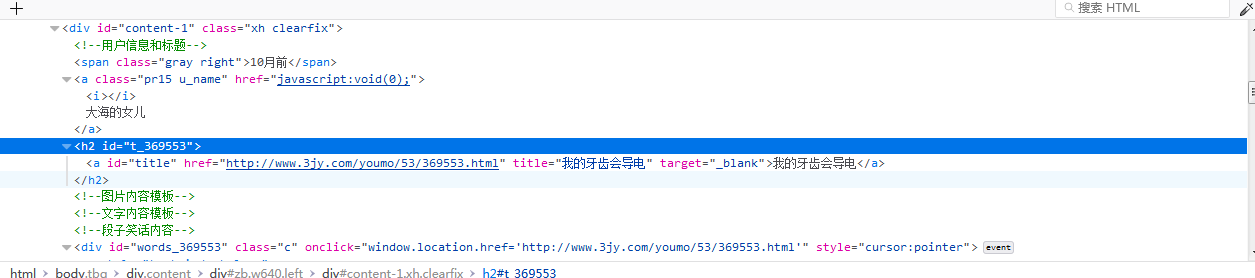
然後根據節點的class屬性獲取相應的節點然後text()方法獲取節點文字。然後執行輸出。
附上執行結果:

jsoup可玩性挺大的,過年,過節爬爬火車票啥的。簡單介紹就到這兒了。
卒
相關推薦
java爬蟲Jsoup簡單學習
啥是jsoup? jsoup我就不巴拉巴拉了,具體介紹百度或者去官網檢視。 jsoup怎麼用? jsoup和jquery的操作相似,下面簡單使用一下。 使用jsoup大概也就以下幾個步驟: 獲取整個html文件 使用選擇器獲取需要爬的資料節點集合 迴圈遍歷使用選擇器獲取相應資料 例項 這是專案結構也就普
java爬蟲--jsoup簡單的表單抓取案例
分析需求:某農產品網站的農產品價格抓取 頁面展示如上: 標籤展示如上: 分析發現每日價格行情包括了蔬菜,水果,肉等所有的資訊,所以直接抓每日行情的內容就可以實現抓取全部資料。 軟體環境:ec
(10)Java爬蟲框架webmagic學習筆記
Java爬蟲框架webmagic學習筆記 參考自:webmagic文件 webmagic簡介 webmagic的github網址:https://github.com/code4craft/webmagic 使用webmagic的原因: webmagic是一個
java爬蟲(Jsoup)爬取某新聞站點標題
import java.io.IOException; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import or
java 鎖 Lock 簡單學習
公平鎖和非公平鎖:區別在於是否會檢查執行緒佇列並且從執行緒佇列(雙端佇列)首獲取執行緒鎖;公平鎖-在每次獲取鎖時會檢查執行緒佇列是否還有執行緒,若有則從佇列首獲取執行緒並加鎖。非公平鎖-對於執行緒獲取鎖是隨機的,並不會去從佇列首去獲取鎖,新進執行緒有很大機率獲取到鎖。 L
Java爬蟲學習:利用HttpClient和Jsoup庫實現簡單的Java爬蟲程式
利用HttpClient和Jsoup庫實現簡單的Java爬蟲程式 HttpClient簡介 HttpClient是Apache Jakarta Common下的子專案,可以用來提供高效的、最新的、功能豐富的支援HTTP協議的客戶端程式設計工具包,並且它支
簡單地學習Java爬蟲->使用Jsoup
簡單地學習Java爬蟲->使用Jsoup 一、gradle環境搭建 implementation 'org.jsoup:jsoup:1.11.3' 二、Activity package com.example.testforjsoup; impor
java基於jsoup實現簡單的圖片爬蟲並下載
2018年11月04日 17:20:32 小小申 閱讀數:4 標籤: jsoup java
Java爬蟲-使用HttpClient+Jsoup實現簡單的爬蟲爬取文字
##一、工具介紹 HttpClient是Apache Jakarta Common下的子專案,用來提供高效的、最新的、功能豐富的支援HTTP協議的客戶端程式設計工具包,並且它支援HTTP協議最新的版本和建議。HttpClient已經應用在很多的專案中,比如A
java爬蟲:jsoup的簡單案例
package jsoup;import java.io.IOException;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.nodes.Element;import org.
java爬蟲問題二: 使用jsoup爬取數據class選擇器中空格多選擇怎麽解決
凱哥Java問題描述: 在使用jsoup爬取其他網站數據的時候,發現class是帶空格的多選擇,如果直接使用doc.getElementsByClass(“class的值”),這種方法獲取不到想要的數據。 爬取網站頁面結構如下: 其中文章列表的div為:<div class="am-cf in
HttpClient&Jsoup爬蟲的簡單應用
target utf-8 gpo art t對象 設置 int sel 發送 詳細的介紹已經有很多前輩總結,引用一下該篇文章:https://blog.csdn.net/zhuwukai/article/details/78644484 下面是一個代碼的示例: p
Java爬蟲技術之HttpClient學習筆記
結果 小爬蟲 如果 依賴包 很多 tac world 官方 靈活 第一節、HttpClient 一、HttpClient 簡介 超文本傳輸協議【The Hyper-Text Transfer Protocol (HTTP)】是當今互聯網上使用的最重要(significan
(java)selenium webdriver學習---實現簡單的翻頁,將頁面內容的標題和標題鏈接取出
prop imp current inter 並且 常見問題 activity num div selenium webdriver學習---實現簡單的翻頁,將頁面內容的標題和標題鏈接取出; 該情況適合能能循環page=1~n,並且每個網頁隨著循環可以打開的情況, 註意一定
java爬蟲學習1
1 需求:比如要從這樣一個網頁上抓取資料 這個請求最後面的uid其實是百度地圖上查到該點的uid(也就是5ef5edbdc64c1bb49e9d6899),我的資料庫裡面已經獲取了武漢的房地產的uid,現在要通過uid獲取詳細資訊。 先從一個著手,再多的資料也是迴圈抓取了。
Java爬蟲學習《一、爬取網頁URL》
導包,如果是用的maven,新增依賴: <dependency> <groupId>commons-httpclient</groupId> <artifactId>commons
【轉載儲存】Java丨jsoup網路爬蟲登入得到cookie並帶上cookie訪問
優秀文章:https://blog.csdn.net/wisdom_maxl/article/details/65631825 jsoup使用cookie: Set<Cookie> cookie_set = LoadCSDN.load(); // WebClient
java爬蟲入門jsoup 框架
所需jar包 <dependency> <!-- jsoup HTML parser library @ http://jsoup.org/ --> <groupId>org.jsoup</groupId> <arti
《java為何這麼簡單》基礎篇-學習前的概述
大家好,我是杜斯,首先,歡迎你們觀看本章,如果你是有程式設計經驗的,建議你跳過本篇。 什麼是java? Java是一門面向物件程式語言,不僅吸收了C++語言的各種優點,還摒棄了C++裡難以理解的多繼承、指標等概念,因此Java語言具有功能強大和簡單易用兩個特
jsoup編寫java爬蟲
jsoup是一款簡潔輕便的java網路爬蟲庫,因為它的API與DOM物件操作直接掛鉤,所以收到了廣泛的歡迎,下面來講解如何爬取京東上的圖書。 因為我是採用的gradle框架來完成整合的,所以可