
bio,request,request_queue的關係
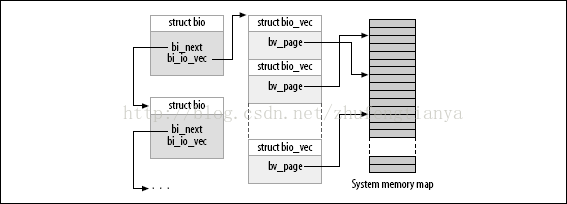
通用塊層的核心資料結構稱為bio描述符,它描述了塊裝置的io操作。每一個bio結構都包含一個磁碟儲存區識別符號(儲存區中的起始扇區號和扇區數目)和一個或多個描述與IO操作相關的記憶體區段(bio_vec陣列)
bio結構中的欄位
/*
* main unit of I/O for the block layer and lower layers (ie drivers and
* stacking drivers)
*/
struct bio {
struct bio *bi_next; /* request queue link 連結到請求佇列中的下一個bio*/
struct block_device * bio中的每個段是由一個bio_vec資料結構描述的,bio_vec資料結構如下
//bio段就是描述所要讀或寫的資料在記憶體中位置
struct bio_vec{
struct page* bv_page //指向段在頁框描述符的指標
unsigned int bv_len //段的位元組長度
unsigned int bv_offset //頁框中資料的偏移量
}
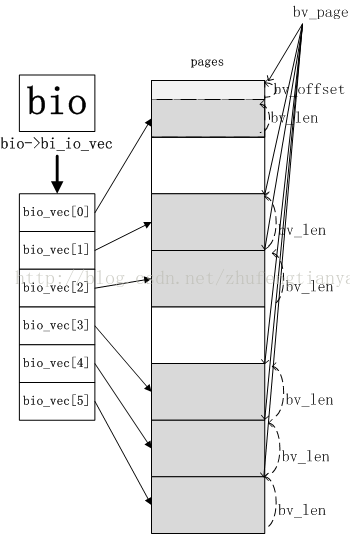
bio中的bi_io_vec欄位指向bio_vec陣列的第一個元素,bi_vcnt則說明了陣列當前元素的個數,而bi_max_vecs則限定了陣列的長度。 下面兩幅圖可以很好的說明bio與bio_vec的關係
在通用塊層啟動一次新的IO操作時,會呼叫bio_alloc函式分配一個新的bio結構,bio是由slab分配器分配的。核心同時也為bio_vec結構分配記憶體池。
bio與bio段的關係
一個bio可能有很多個bio段,這些bio段可能在記憶體上不連續(位於不同的頁),但他們在磁碟上對應的位置是連續的。一般上層構建bio的時候都是隻有一個bio段,可以參考_submit_bh函式。
在塊io操作期間bio的內容一直保持更新,例如,塊裝置驅動在一次分散聚集DMA操作中不能一次完成全部資料的傳送,那麼bio的bi_idx就會更新來指向待傳送的第一個段。
bio:代表了一個io請求
request:一個request中包含了一個或多個bio,為什麼要有request這個結構呢?它存在的目的就是為了進行io的排程。通過request這個輔助結構,我們來給bio進行某種排程方法的排序,從而最大化地提高磁碟訪問速度。
request_queue:每個磁碟對應一個request_queue.該佇列掛的就是request請求。
具體如下圖:(有顏色方框頭表示資料結構的名字)
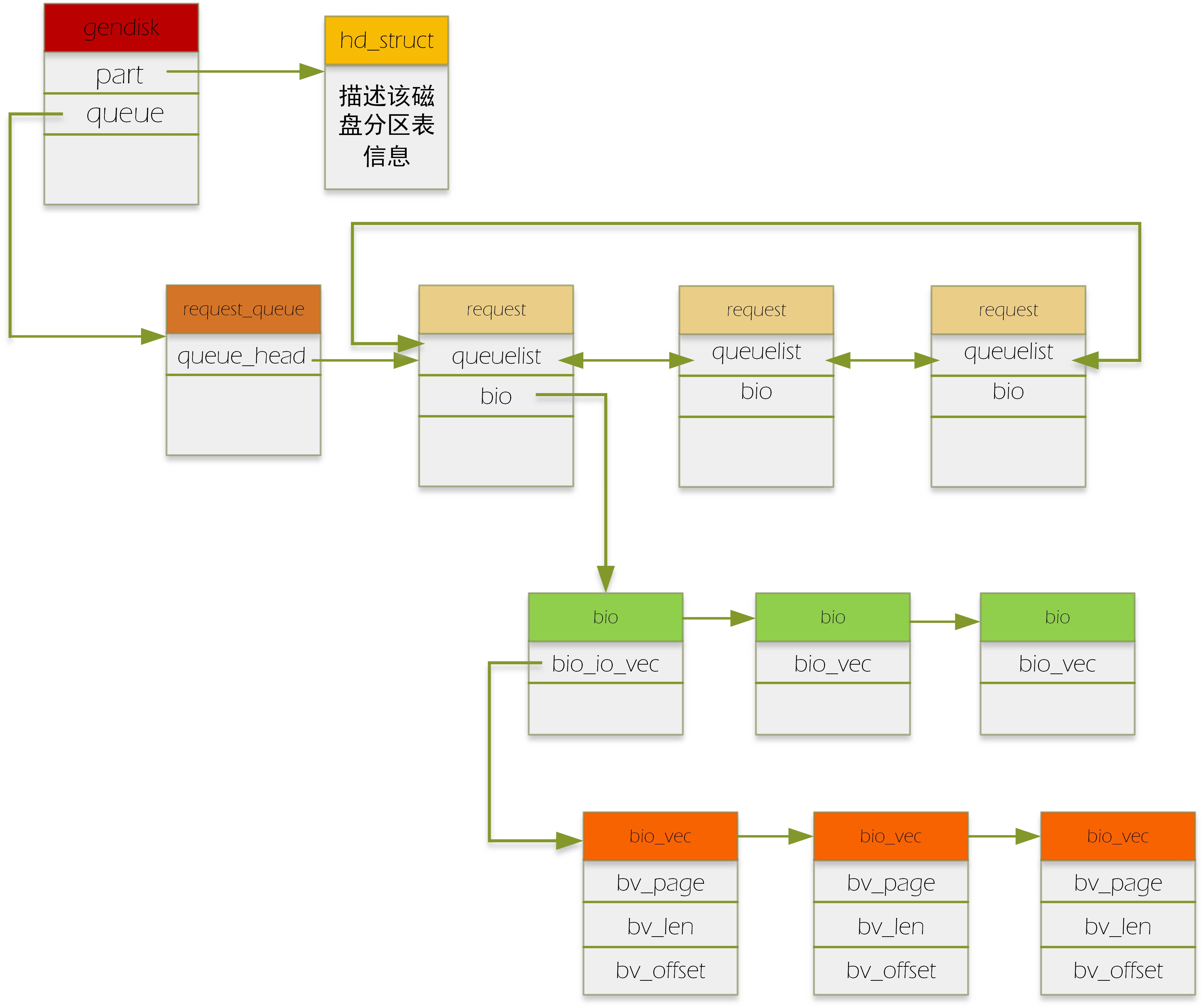
請求到達block層後,通過generic_make_request這個入口函式,在通過呼叫一系列相關的函式(具體參見我另一篇部落格)把bio變成了request。具體的做法如下:如果幾個bio要讀寫的區域是連續的,即積攢成一個request(一個request上掛多個連續的bio,就是我們通常說的“合併bio請求”),如果一個bio跟其他的bio都連不上,那它就自己建立一個新的request,把自己掛在這個request下。當然,合併bio的個數也是有限的,這個可以通過配置檔案配置。
對於上段補充一點:上層的一次請求可能跨越了多個扇區,形成不連續的扇區段,那麼該請求構造的每個bio對應著一個連續的扇區段。故一個請求可以構造出多個bio。
合併後的request放入每個裝置對應的request_queue中。之後裝置驅動呼叫peek_request從request_queue中取出request,進行下一步處理。
這裡要注意的是,在實現裝置驅動時,廠家可以直接從request_queue中拿出排隊好的request,也可以實現自己的bio排隊方法,即實現自己的make_request_fn方法,即直接拿檔案系統傳來的bio來自己進行排隊,按需設計,想怎麼排就怎麼排,像ramdisk,還有很多SSD裝置的firmware就是自己排。(這裡就和我另一篇部落格,說到為什麼generic_make_request要設計成一層遞迴呼叫聯絡起來)。
網上有個問答也是我的疑惑:這裡我寫一遍,加強記憶
bio結構中有bio_vec陣列結構,該結構的的陣列可以指向不同的page單元,那為什麼不在bio這一級就做了bio合併工作,即把多個bio合併成一個bio,何必加入一個request這麼麻煩?
答:每個bio有自己的end_bio回撥,一旦一個bio結束,就會對自己進行收尾工作,如果合併了,或許有些bio會耽誤,靈活性差。