
hadoop安裝與配置
安裝並使用多種方法配置Hadoop。
準備
建立Hadoop使用者
- 建立新使用者
sudo useradd –m hadoop –s /bin/bash
- 設定密碼
sudo passwd hadoop
- 增加管理員許可權
sudo adduser hadoop sudo
- 最後,切換到該使用者進行登入
SSH登入許可權設定
配置SSH的原因
- Hadoop名稱節點(NameNode)需要啟動叢集中所有機器的Hadoop守護程序,這個過程需要通過SSH登入來實現
- Hadoop並沒有提供SSH輸入密碼登入的形式,因此,為了能夠順利登入每臺機器,需要將所有機器配置為名稱節點可以無密碼登入它們
SSH本機免金鑰登入
- 首先安裝
openssh - 檢視當前
/home/hadoop目錄下有無.ssh資料夾,若無,則建立mkdir ~/.ssh,修改許可權chmod 700 ~/.ssh - 執行指令
ssh-keygen –t rsa生成公鑰和私鑰 (一路回車) - 執行
cat ./id_rsa.pub >> ./authorized_keys將金鑰加入授權 - 執行指令
ssh localhost進行測試
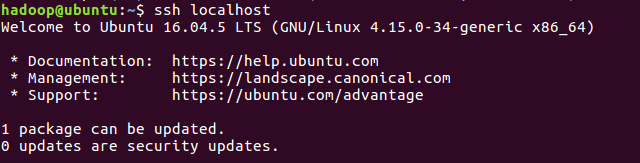
Java
-
首先確保Linux系統中已經裝好Java
-
在oracle官網安裝最新版本。
-
預設下載到
download目錄 -
當前目錄下進行解壓
tar -xvf jdk-8u161-linux-x64.tar.gz
-
移動到目錄
/usr/local/Java -
配置環境變數(
vim ~/.bashrc)#JAVA export JAVA_HOME=/usr/local/Java/jdk1.8.0_181/ export JRE_HOME=$JAVA_HOME/jre export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:. -
退出後重新整理
source ~/.bashrc -
測試
java -version
Hadoop下載
-
下載清華的映象
-
預設下載到
download -
解壓到
/usr/localsudo tar -zxf ./hadoop-3.1.1.tar.gz -C /usr/local
-
切換到解壓目錄並修改檔案許可權
-
cd /usr/local sudo mv ./hadoop-3.1.1 ./hadoop #重新命名 sudo chown -R hadoop ./hadoop # 修改檔案許可權
-
-
檢視版本號及是否安裝好
-
cd /usr/local/hadoop ./bin/hadoop version -
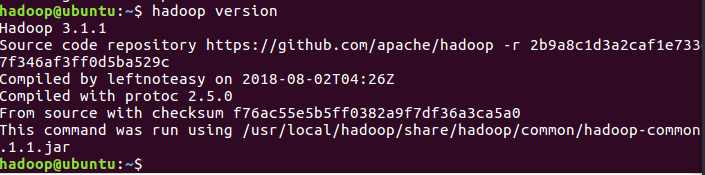
-
-
設定環境變數,以便直接使用
hadoop命令-
進入
vim /.bashrc -
export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:/usr/local/hadoop/bin -
直接輸入
hadoop看是否成功
-
Hadoop目錄結構
bin:Hadoop最基本的管理指令碼和使用指令碼的目錄,這些指令碼是sbin目錄下管理
指令碼的基礎實現,使用者可以直接使用這些指令碼管理和使用Hadoopetc:Hadoop配置檔案所在的目錄,包括core-site,xml、hdfs-site.xml、mapredsite.xml等include:對外提供的程式設計庫標頭檔案(具體動態庫和靜態庫在lib目錄中),這些頭
檔案均是用C++定義的,通常用於C++程式訪問HDFS或者編寫MapReduce程式lib:該目錄包含了Hadoop對外提供的程式設計動態庫和靜態庫,與include目錄中的
標頭檔案結合使用libexec:各個服務對用的shell配置檔案所在的目錄,可用於配置日誌輸出、啟動
引數(比如JVM引數)等基本資訊sbin:Hadoop管理指令碼所在的目錄,主要包含HDFS和YARN中各類服務的啟動/關
閉指令碼share:Hadoop各個模組編譯後的jar包所在的目錄

Hadoop單機部署
-
預設為非分散式模式,無須進行其他配置即可執行。附帶了很多例子,可以直接檢視所有例子:
-
cd /usr/local/hadoop hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar -
會顯示
grep,join,wordcount等例子
-
-
這裡選擇
grep例子,流程為先建一個input資料夾,並複製一些檔案到該檔案;然後執行grep程式,將input資料夾的所有檔案作為grep的輸入,讓grep程式從所有檔案中篩選出符合正則表示式的單詞,並輸出結果到output-
mkdir input cp ./etc/hadoop/*.xml ./input hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar grep ./input ./output 'dfs[a-z.]+' -
這裡需要注意的是,hadoop預設要求輸出
output不存在,若存在則會報錯 -
檢視執行結果
cat ./output/* -

-
Hadoop偽分散式部署
- Hadoop 的配置檔案位於
/usr/local/hadoop/etc/hadoop/中,偽分散式需要修改2個配置檔案core-site.xml和hdfs-site.xml - 配置檔案是
xml格式,每個配置以宣告property的name和value的方式來實現 - Hadoop在啟動時會讀取配置檔案,根據配置檔案來決定執行在什麼模式下
修改配置檔案
-
vim core-site.xml- 開啟後如圖所示:

- 修改為
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>hadoop.tmp.dir表示存放臨時資料的目錄,即包括NameNode的資料,也包括DataNode的資料。該路徑任意指定,只要實際存在該資料夾即可name為fs.defaultFS的值,表示hdfs路徑的邏輯名稱
-
vim hdfs-site.xml-
修改為:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/data</value> </property> </configuration> -
dfs.replication表示副本的數量,偽分散式要設定為1 -
dfs.namenode.name.dir表示名稱節點的元資料儲存目錄 -
dfs.datanode.data.dir表示資料節點的資料儲存目錄
-
格式化節點
-
cd /usr/local/hadoop/ ./bin/hdfs namenode -format -
若成功,則顯示

啟動Hadoop
-
執行命令:
-
cd /usr/local/hadoop ./sbin/start-dfs.sh
-
-
若出現報錯:
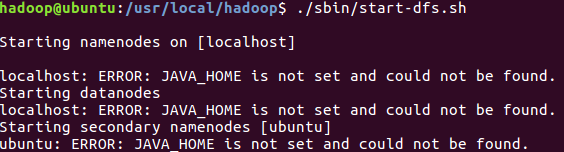
-
則表示
JAVA_HOME目錄沒有設定對,如果之前使用Java沒有問題,則直接進入Hadoop環境中設定 -
cd /usr/local/hadoop/etc/hadoop vim hadoop-env.sh -
直接新增自己電腦裡的
Java_HOME路徑,如: -
再次啟動
-
判斷是否啟動成功



Web介面檢視HDFS資訊
- 啟動Hadoop後,在瀏覽器輸入
http://localhost:9870/,可訪問NameNode。 - 如圖所示,表示成功:

關閉Hadoop
-
cd /usr/local/hadoop ./sbin/stop-dfs.sh -
下次啟動時,無須再進行名稱節點的格式化
關於三種Shell命令方式的區別
hadoop fshadoop fs適用於任何不同的檔案系統,比如本地檔案系統和HDFS檔案系統
hadoop dfshadoop dfs只能適用於HDFS檔案系統
hdfs dfshdfs dfs跟hadoop dfs的命令作用一樣,也只能適用於HDFS檔案系統
操作示例
-
還原單機模型的
grep例子 -
cd /usr/local/hadoop ./bin/hdfs dfs –mkdir –p /user/hadoop # 在HDFS中為hadoop使用者建立目錄(Linux檔案系統中不可見) ./bin/hdfs dfs –mkdir input # 在HDFS中建立hadoop使用者對應的input目錄 ./bin/hdfs dfs –put ./etc/hadoop/*.xml input # 將本地檔案複製到HDFS中 ./bin/hdfs dfs –ls input # 檢視HDFS中的檔案列表 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar grep input output ‘dfs[a-z.]+’ ./bin/hdfs dfs -cat output/* #檢視執行結果 -
可能出現警告資訊,可忽略
-

-
檢視檔案列表
-

-
最後結果
-
