
Java網路程式設計與NIO
1. 計算機網路程式設計基礎
1.七層模型
七層模型(OSI,Open System Interconnection參考模型),是參考是國際標準化組織制定的一個用於計算機或通訊系統間互聯的標準體系。它是一個七層抽象的模型,不僅包括一系列抽象的術語和概念,也包括具體的協議。 經典的描述如下:
簡述每一層的含義:
- 物理層(Physical Layer):建立、維護、斷開物理連線。
- 資料鏈路層 (Link):邏輯連線、進行硬體地址定址、差錯校驗等。
- 網路層 (Network):進行邏輯定址,實現不同網路之間的路徑選擇。
- 傳輸層 (Transport):定義傳輸資料的協議埠號,及流控和差錯校驗。
- 會話層(Session Layer):建立、管理、終止會話。
- 表示層(Presentation Layer):資料的表示、安全、壓縮。
- 應用層 (Application):網路服務與終端使用者的一個介面
每一層利用下一層提供的服務與對等層通訊,每一層使用自己的協議。瞭解了這些,然並卵。但是,這一模型確實是絕大多數網路程式設計的基礎,作為抽象類存在的,而TCP/IP協議棧只是這一模型的一個具體實現。
2.TCP/IP協議模型
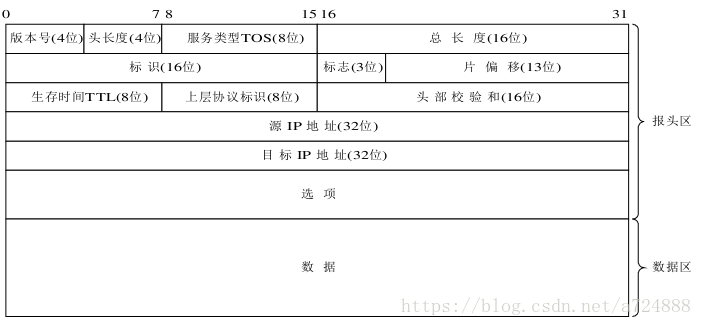
IP資料包結構:
---
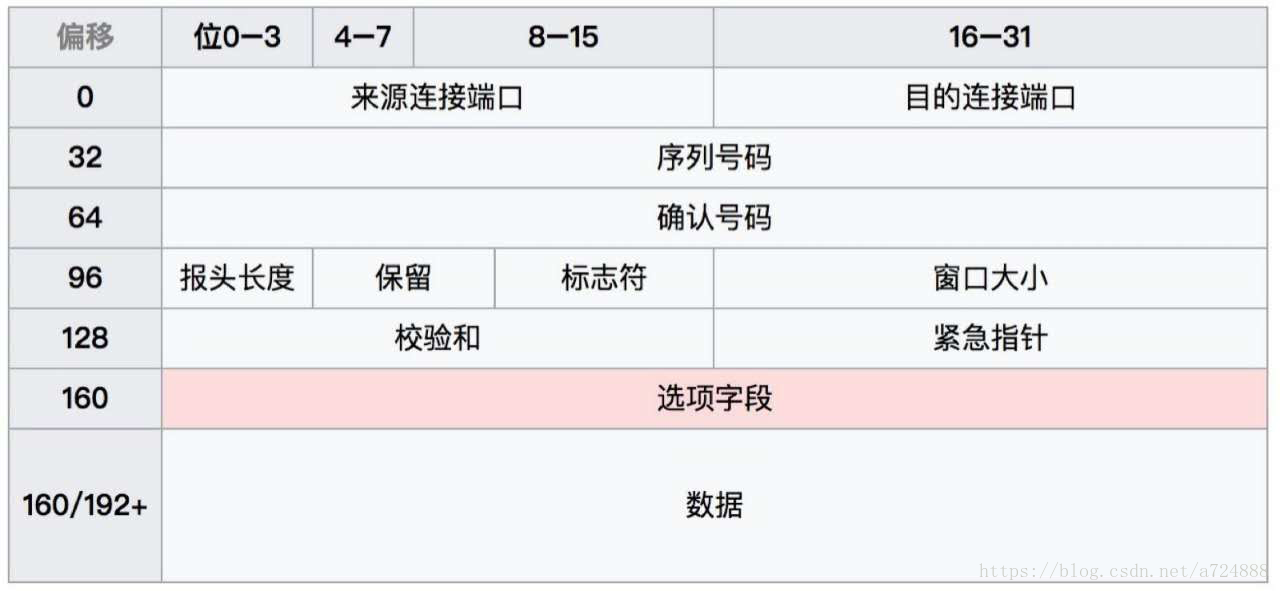
TCP資料包結構:
一個模型例子:
定址過程:每臺機子都有個實體地址MAC地址和邏輯地址IP地址,實體地址用於底層的硬體的通訊,邏輯地址用於上層的協議間的通訊。定址過程會先使用ip地址進行路由定址,在不同網路中進行路由轉發,到了同一個區域網時,再根據實體地址進行廣播定址,資料在乙太網的區域網中都是以廣播方式傳輸的,整個區域網中的所有節點都會收到該幀,只有目標MAC地址與自己的MAC地址相同的幀才會被接收。
建立可靠的連線:A向B傳輸一個檔案時,如果檔案中有部分資料丟失,就可能會造成在B上無法正常閱讀或使用。 TCP協議就是建立了可靠的連線:
TCP三次握手確定了雙方資料包的序號、最大接受資料的大小(window)以及MSS(Maximum Segment Size)
會話層用來建立、維護、管理應用程式之間的會話,主要功能是對話控制和同步,程式設計中所涉及的session是會話層的具體體現。表示層完成資料的解編碼,加解密,壓縮解壓縮等。
2.Socket程式設計
在Linux世界,“一切皆檔案”,作業系統把網路讀寫作為IO操作,就像讀寫檔案那樣,對外提供出來的程式設計介面就是Socket。所以,socket(套接字)是通訊的基石,是支援TCP/IP協議網路通訊的基本操作單元。socket實質上提供了程序通訊的端點。程序通訊之前,雙方首先必須各自建立一個端點,否則是沒有辦法建立聯絡並相互通訊的。一個完整的socket有一個本地唯一的socket號,這是由作業系統分配的。
在許多作業系統中,Socket描述符和其他IO描述符是整合在一起的,作業系統把socket描述符實現為一個指標陣列,這些指標指向內部資料結構。程序進行Socket操作時,也有著多種處理方式,如阻塞式IO,非阻塞式IO,多路複用(select/poll/epoll),AIO等等。
多路複用往往在提升效能方面有著重要的作用。
當前主流的Server側Socket實現大都採用了epoll的方式,例如Nginx, 在配置檔案可以顯式地看到 use epoll。
舉個栗子
Java中Socket服務端的簡單實現:基本思路就是一個大迴圈不斷監聽客戶端請求,為了提高處理效率可以使用執行緒池多個執行緒進行每個連線的資料讀取
public class BIOServer {
private ServerSocket serverSocket;
private ExecutorService executorService = Executors.newCachedThreadPool();
class Handler implements Runnable {
Socket socket;
public Handler(Socket socket) {
this.socket = socket;
}
@Override
public void run() {
try {
BufferedReader buf = new BufferedReader(new InputStreamReader(socket.getInputStream()));
String readData = buf.readLine();
while (readData != null) {
readData = buf.readLine();
System.out.println(readData);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
public BIOServer(int port) {
try {
serverSocket = new ServerSocket(port);
} catch (IOException e) {
e.printStackTrace();
}
}
public void run() {
try {
Socket socket = serverSocket.accept();
executorService.submit(new Handler(socket));
} catch (Exception e) {
}
}
}
客戶端:建立socket連線、發起請求、讀取響應
public class IOClient {
public void start(String host, int port) {
try {
Socket s = new Socket("127.0.0.1",8888);
InputStream is = s.getInputStream();
OutputStream os = s.getOutputStream();
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(os));
bw.write("測試客戶端和伺服器通訊,伺服器接收到訊息返回到客戶端\n");
bw.flush();
BufferedReader br = new BufferedReader(new InputStreamReader(is));
String mess = br.readLine();
System.out.println("伺服器:"+mess);
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.IO模型
對於一次IO訪問(以read舉例),資料會先被拷貝到作業系統核心的緩衝區page cache中,然後才會從作業系統核心的緩衝區拷貝到應用程式的地址空間。所以說,當一個read操作發生時,它會經歷兩個階段:
- 等待資料準備
- 將資料從核心拷貝到程序中
IO模型的分類有下:
- 阻塞 I/O(blocking IO)
- 非阻塞 I/O(nonblocking IO)
- I/O 多路複用( IO multiplexing)
- 非同步 I/O(asynchronous IO)
BIO 阻塞 I/O
缺點:一個請求一個執行緒,浪費執行緒,且上下文切換開銷大;
上面寫的socket列子就是典型的BIO
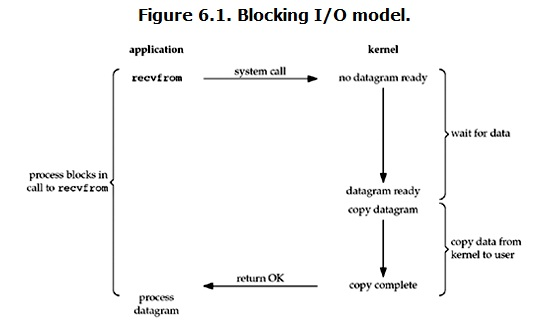
當用戶程序呼叫了recvfrom這個系統呼叫,kernel就開始了IO的第一個階段:準備資料(對於網路IO來說,很多時候資料在一開始還沒有到達。比如,還沒有收到一個完整的UDP包。這個時候kernel就要等待足夠的資料到來)。這個過程需要等待,也就是說資料被拷貝到作業系統核心的緩衝區中是需要一個過程的。而在使用者程序這邊,整個程序會被阻塞(當然,是程序自己選擇的阻塞)。當kernel一直等到資料準備好了,它就會將資料從kernel中拷貝到使用者記憶體,然後kernel返回結果,使用者程序才解除block的狀態,重新執行起來。
NIO 非阻塞 I/O
當用戶程序發出read操作時,如果kernel中的資料還沒有準備好,那麼它並不會block使用者程序,而是立刻返回一個error 。從使用者程序角度講 ,它發起一個read操作後,並不需要等待,而是馬上就得到了一個結果。使用者程序判斷結果是一個error時,它就知道資料還沒有準備好,於是它可以再次傳送read操作。一旦kernel中的資料準備好了,並且又再次收到了使用者程序的system call,那麼它馬上就將資料拷貝到了使用者記憶體,然後返回。

nonblocking IO的特點是使用者程序需要不斷的主動詢問kernel資料好了沒有。
I/O 多路複用
IO multiplexing就是我們說的select,poll,epoll,有些地方也稱這種IO方式為event driven IO。select/epoll的好處就在於單個process就可以同時處理多個網路連線的IO。它的基本原理就是select,poll,epoll這個function會不斷的輪詢所負責的所有socket,當某個socket有資料到達了,就通知使用者程序。
機制:一個執行緒以阻塞的方式監聽客戶端請求;另一個執行緒採用NIO的形式select已經接收到資料的channel通道,處理請求;
- select,poll,epoll模型 - 處理更多的連線
上面所說的多路複用的select,poll,epoll本質上都是同步IO,因為他們都需要在讀寫事件就緒後自己負責進行讀寫,也就是說這個讀寫過程是阻塞的,實際上是指阻塞在select上面,必須等到讀就緒、寫就緒等網路事件。非同步IO則無需自己負責進行讀寫,非同步IO的實現會負責把資料從核心拷貝到使用者空間。

I/O 多路複用的特點是通過一種機制一個程序能同時等待多個檔案描述符,
而這些檔案描述符(套接字描述符)其中的任意一個進入讀就緒狀態,select()
函式就可以返回。所以,如果處理的連線數不是很高的話,使用select/epoll的web
server不一定比使用multi-threading + blocking IO的web
server效能更好,可能延遲還更大。select/
epoll的優勢並不是對於單個連線能處理得更快,而是在於能處理更多的連線。
- 一個面試問題:select、poll、epoll的區別?
Java中的I/O 多路複用: Reactor模型
(主從Reactor模型)netty就是主從Reactor模型的實現,相當於這個模型在
對比與傳統的I/O 多路複用,Reactor模型增加了事件分發器,基於事件驅動,能夠將相應的讀寫事件分發給不同的執行緒執行,真正實現了非阻塞I/O。
基於Reactor Pattern 處理模式中,定義以下三種角色
- Reactor將I/O事件分派給對應的Handler
- Acceptor處理客戶端新連線,並分派請求到處理器鏈中
- Handlers執行非阻塞讀/寫 任務
舉個栗子
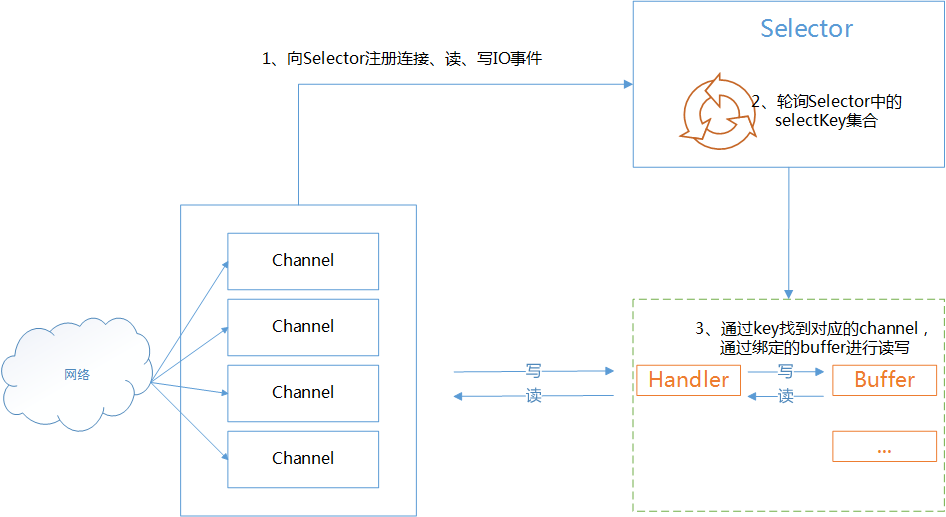
回顧我們上面寫的程式碼,是不是每個執行緒處理一個連線,顯然在高併發情況下是不適用的,應該採用 IO多路複用 的思想,使得一個執行緒能夠處理多個連線,並且不能阻塞讀寫操作,新增一個 選擇器在buffer有資料的時候就開始寫入使用者空間.這裡的多路是指N個連線,每一個連線對應一個channel,或者說多路就是多個channel。複用,是指多個連線複用了一個執行緒或者少量執行緒
現在我們來優化下上面的socket IO模型
優化後的IO模型:
實現一個最簡單的Reactor模式:註冊所有感興趣的事件處理器,單執行緒輪詢選擇就緒事件,執行事件處理器。流程就是不斷輪詢可以進行處理的事件,然後交給不同的handler進行處理.
上面提到的主要是四個網路事件:有連線就緒,接收就緒,讀就緒,寫就緒。I/O複用主要是通過 Selector複用器來實現的,可以結合下面這個圖理解上面的敘述
public class NIOServer {
private ServerSocketChannel serverSocket;
private Selector selector;
private ReadHandler readHandler;
private WriteHandler writeHandler;
private ExecutorService executorService = Executors.newCachedThreadPool();
abstract class Handler {
protected SelectionKey key;
}
class ReadHandler extends Handler implements Runnable {
@Override
public void run() {
///...讀操作
}
}
class WriteHandler extends Handler implements Runnable {
@Override
public void run() {
///...寫操作
}
}
public NIOServer(int port) {
try {
selector = Selector.open();
serverSocket = ServerSocketChannel.open();
serverSocket.bind(new InetSocketAddress(port));
serverSocket.register(this.selector, SelectionKey.OP_ACCEPT);
} catch (IOException e) {
e.printStackTrace();
}
}
public void run() {
while (!Thread.interrupted()) {
try {
selector.select(); //阻塞等待事件
Iterator<SelectionKey> iterator = this.selector.keys().iterator(); // 事件列表 , key -> channel ,每個KEY對應了一個channel
while (iterator.hasNext()) {
iterator.remove();
dispatch(iterator.next()); //分發事件
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
private void dispatch(SelectionKey key) {
if (key.isAcceptable()) {
register(key); //新連線建立,註冊一個新的讀寫處理器
} else if (key.isReadable()) {
this.executorService.submit(new ReadHandler(key)); //可以寫,執行寫事件
} else if (key.isWritable()) {
this.executorService.submit(new WriteHandler(key)); //可以讀。執行讀事件
}
}
private void register(SelectionKey key) {
ServerSocketChannel channel = (ServerSocketChannel) key.channel(); //通過key找到對應的channel
try {
SocketChannel socketChannel = channel.accept();
channel.configureBlocking(false);
channel.register(this.selector, SelectionKey.OP_ACCEPT);
} catch (IOException e) {
e.printStackTrace();
}
}
}
優化執行緒模型
上述模型還可以繼續優化。因為上述模型只是增多個客戶端連線的數量,但是在高併發的情況下,