
Tensorflow 入門學習9.MNIST手寫體識別
本文使用TensorFlow進行MNIST手寫體識別。
MNIST資料集
MNIST是一個入門級的計算機視覺資料集,它包含各種手寫數字圖片。官網地址:Yann LeCun’s website
下載資料集
下載後資料集:
下載的資料集分成兩部分,60000行的訓練資料集(train)和10000行的測試資料集(t10k)。 每一個MNIST資料單元有兩部分組成:一張包含手寫數字的圖片和一個對應的標籤。 這裡把圖片設定“xs”,這些標籤設為“ys”。 訓練資料集和測試資料集都包含xs和ys,如訓練資料集的圖片是mnist.train.images,訓練資料集的標籤是mnist.train.labels。
每一張圖片包含28畫素*28畫素,可以用一個數字陣列來表示這張圖片:
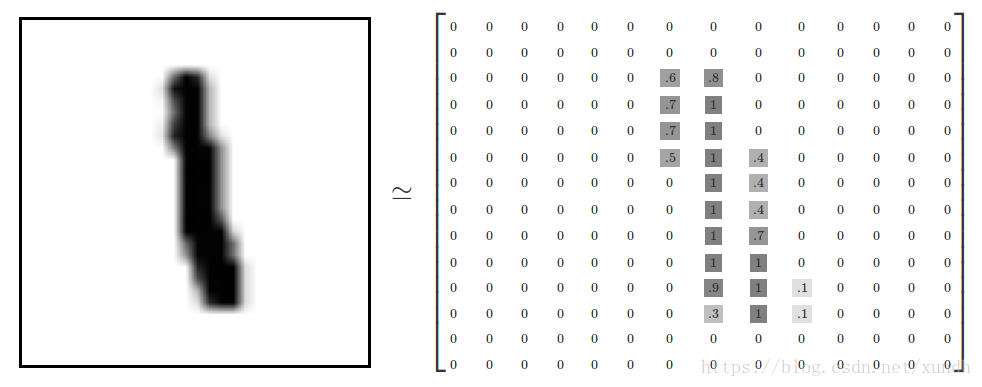
我們把這個陣列展開成一個向量,長度是28*28=784。展平圖片的數字陣列會丟失圖片的二維結構資訊,這並非最理想的方式,最優秀的計算機視覺方法會挖掘並利用這些資訊。 本文暫時忽略這些結構,所介紹的簡單數學模型,softmax迴歸(softmax regression),不會利用這些結構資訊。
因此,在MNIST訓練資料集中,mnist.train.images是一個形狀為[60000,784]的張量,第一個維度數字用來索引圖片,第二個維度數字用來索引每張圖片中的畫素點。在此張量裡的每一個元素,都表示某張圖片裡的某個畫素的強度值,值介於0和1之間。

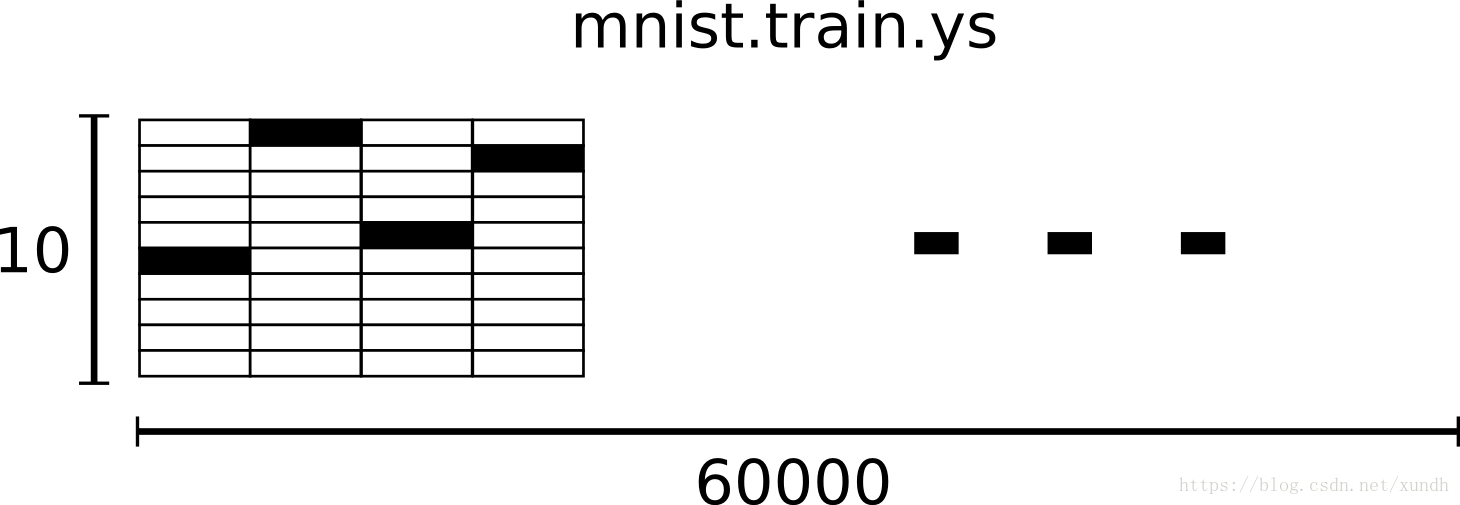
相對應的MNIST資料集的標籤是介於0到9的數字,用來描述給定圖片裡的數字。 這個教程使用標籤資料是"one-hot vectors"。一個one-hot向量除了某一位的數字是1以外其餘各維度數字都是0。比如,標籤0將表示成([1,0,0,0,0,0,0,0,0,0,0])。因此, mnist.train.labels 是一個 [60000, 10] 的數字矩陣。
Softmax迴歸介紹
我們知道MNIST的每一張圖片都表示一個數字,從0到9。我們希望得到給定圖片代表每個數字的概率。比如說,我們的模型可能推測一張包含9的圖片代表數字9的概率是80%但是判斷它是8的概率是5%(因為8和9都有上半部分的小圓),然後給予它代表其他數字的概率更小的值。
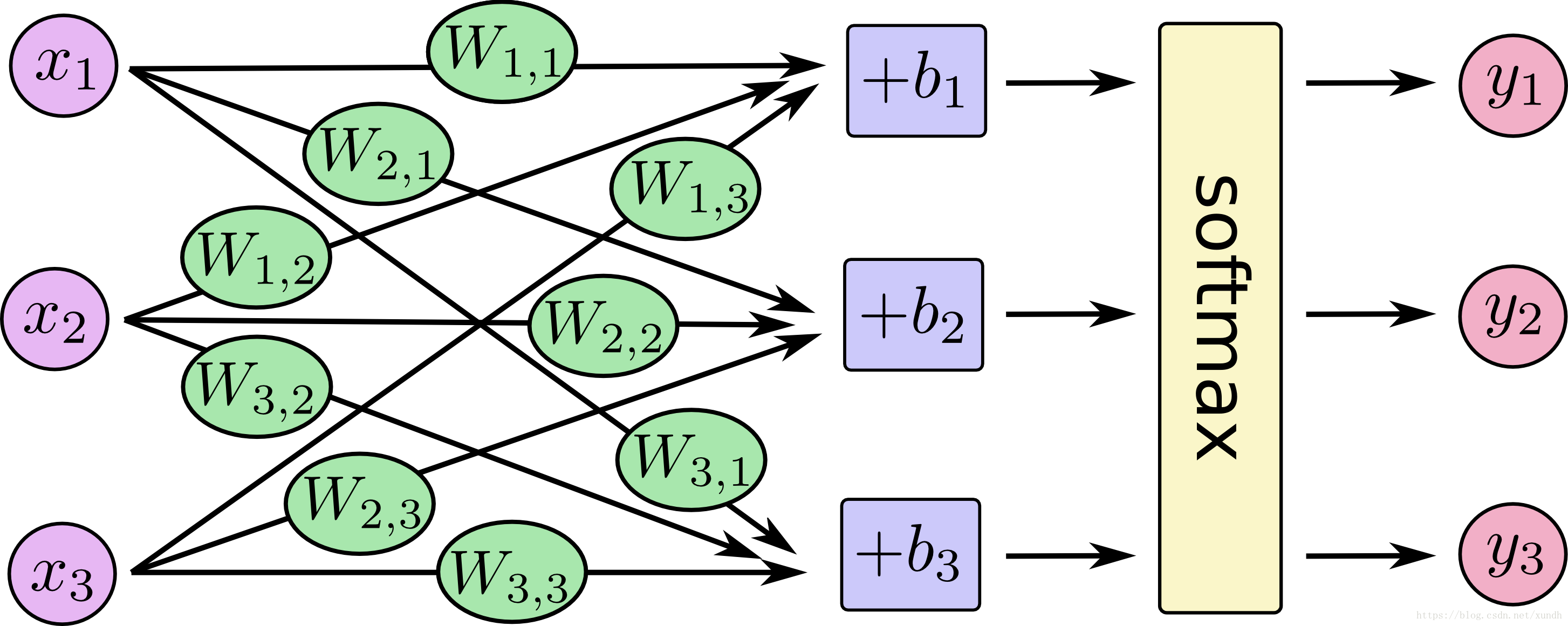
這是一個使用softmax迴歸(softmax regression)模型的經典案例。softmax模型可以用來給不同的物件分配概率。即使在之後,我們訓練更加精細的模型時,最後一步也需要用softmax來分配概率。
softmax迴歸模型:
程式碼示例
#!/usr/bin/python # -*- coding: UTF-8 -*- import input_data import tensorflow as tf # 60000行的訓練資料集(mnist.train)和10000行的測試資料集(mnist.test) mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) # 每一個MNIST資料單元有兩部分組成:一張包含手寫數字的圖片和一個對應的標籤。我們把這些圖片設為“xs”,把這些標籤設為“ys”。 # 訓練資料集和測試資料集都包含xs和ys,比如訓練資料集的圖片是 mnist.train.images ,訓練資料集的標籤是 mnist.train.labels。 # 每一張圖片包含28畫素X28畫素。我們可以用一個數字陣列來表示這張圖片 # 我們賦予tf.Variable不同的初值來建立不同的Variable:在這裡,我們都用全為零的張量來初始化W和b。因為我們要學習W和b的值,它們的初值可以隨意設定。 x = tf.placeholder("float", [None, 784]) W = tf.Variable(tf.zeros([784, 10])) b = tf.Variable(tf.zeros([10])) # 實現softmax模型 y = tf.nn.softmax(tf.matmul(x, W) + b) # 用來輸入正確值 y_ = tf.placeholder("float", [None, 10]) # 計算交叉熵,這裡交叉熵是所有100幅圖片的交叉熵總和 cross_entropy = -tf.reduce_sum(y_*tf.log(y)) # 用梯度下降 0.01學習率最小化交叉熵 # TensorFlow在這裡實際上所做的是,它會在後臺給描述你的計算的那張圖裡面增加一系列新的計算操作單元用於實現反向傳播演算法和梯度下降演算法。 # 然後,它返回給你的只是一個單一的操作,當執行這個操作時,它用梯度下降演算法訓練你的模型,微調你的變數,不斷減少成本。 train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy) # 初始化變數 init = tf.initialize_all_variables() sess = tf.Session() sess.run(init) # 模型迴圈訓練1000次 for i in range(1000): # 每步隨機抓取訓練資料中的100個批處理資料點 batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys}) # tf.argmax給出某個tensor物件在某一維上的其資料最大值所在的索引值 # 由於標籤向量是由0,1組成,因此最大值1所在的索引位置就是類別標籤, # 比如tf.argmax(y,1)返回的是模型對於任一輸入x預測到的標籤值, # 而 tf.argmax(y_,1) 代表正確的標籤,我們可以用 tf.equal 來檢測我們的預測是否真實標籤匹配(索引位置一樣表示匹配)。 # 這行程式碼會給我們一組布林值 correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) # 把布林值轉換成浮點值,然後取平均值,如[True, False, True, True] 會變成 [1,0,1,1] ,取平均值後得到 0.75. accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) # 計算所學習到的模型在測試資料集上面的正確率。 print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
計算結果在0.91左右。這個結果是很差的,最好的模型可以超過99.7%的準確率。但這個模型是非常簡單的。