
【58沈劍 架構師之路】1分鐘瞭解MyISAM與InnoDB的索引差異
《資料庫索引,到底是什麼做的?》介紹了B+樹,它是一種非常適合用來做資料庫索引的資料結構:
(1)很適合磁碟儲存,能夠充分利用區域性性原理,磁碟預讀;
(2)很低的樹高度,能夠儲存大量資料;
(3)索引本身佔用的記憶體很小;
(4)能夠很好的支援單點查詢,範圍查詢,有序性查詢;
資料庫的索引分為主鍵索引(Primary Inkex)與普通索引(Secondary Index)。InnoDB和MyISAM是怎麼利用B+樹來實現這兩類索引,其又有什麼差異呢?這是今天要聊的內容。
一,MyISAM的索引
MyISAM的索引與行記錄是分開儲存的
其主鍵索引與普通索引沒有本質差異:
-
有連續聚集的區域單獨儲存行記錄
-
主鍵索引的葉子節點,儲存主鍵,與對應行記錄的指標
-
普通索引的葉子結點,儲存索引列,與對應行記錄的指標
畫外音:MyISAM的表可以沒有主鍵。
主鍵索引與普通索引是兩棵獨立的索引B+樹,通過索引列查詢時,先定位到B+樹的葉子節點,再通過指標定位到行記錄。
舉個例子,MyISAM:
t(id PK, name KEY, sex, flag);
表中有四條記錄:
1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B
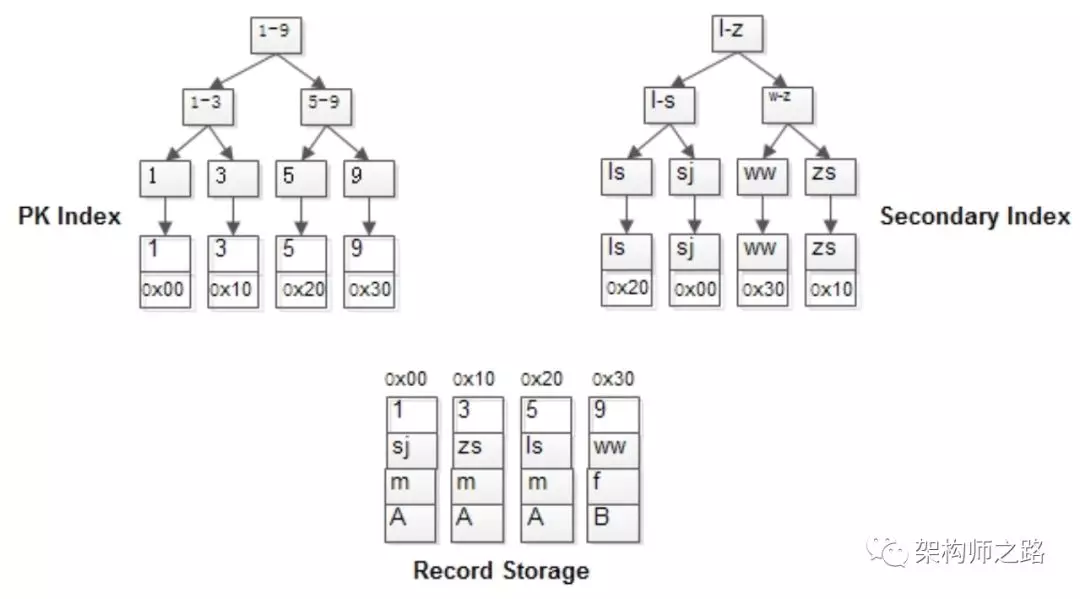
其B+樹索引構造如上圖:
-
行記錄單獨儲存
-
id為PK,有一棵id的索引樹,葉子指向行記錄
-
name為KEY,有一棵name的索引樹,葉子也指向行記錄
二、InnoDB的索引
InnoDB的主鍵索引與行記錄是儲存在一起的,故叫做聚集索引(Clustered Index):
-
沒有單獨區域儲存行記錄
-
主鍵索引的葉子節點,儲存主鍵,與對應行記錄(而不是指標)
畫外音:因此,InnoDB的PK查詢是非常快的。
因為這個特性,InnoDB的表必須要有聚集索引:
(1)如果表定義了PK,則PK就是聚集索引;
(2)如果表沒有定義PK,則第一個非空unique列是聚集索引;
(3)否則,InnoDB會建立一個隱藏的row-id作為聚集索引;
聚集索引,也只能夠有一個,因為資料行在物理磁碟上只能有一份聚集儲存。
InnoDB的普通索引可以有多個,它與聚集索引是不同的:
-
普通索引的葉子節點,儲存主鍵(也不是指標)
對於InnoDB表,這裡的啟示是:
(1)不建議使用較長的列做主鍵,例如char(64),因為所有的普通索引都會儲存主鍵,會導致普通索引過於龐大;
(2)建議使用趨勢遞增的key做主鍵,由於資料行與索引一體,這樣不至於插入記錄時,有大量索引分裂,行記錄移動;
仍是上面的例子,只是儲存引擎換成InnoDB:
t(id PK, name KEY, sex, flag);
表中還是四條記錄:
1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B
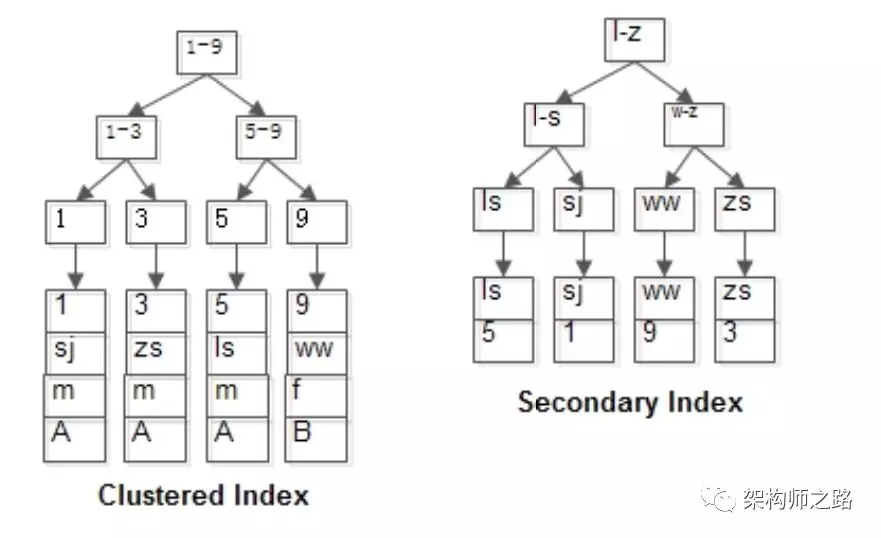
其B+樹索引構造如上圖:
-
id為PK,行記錄和id索引樹儲存在一起
-
name為KEY,有一棵name的索引樹,葉子儲存id
當:
select * from t where name=‘lisi’;
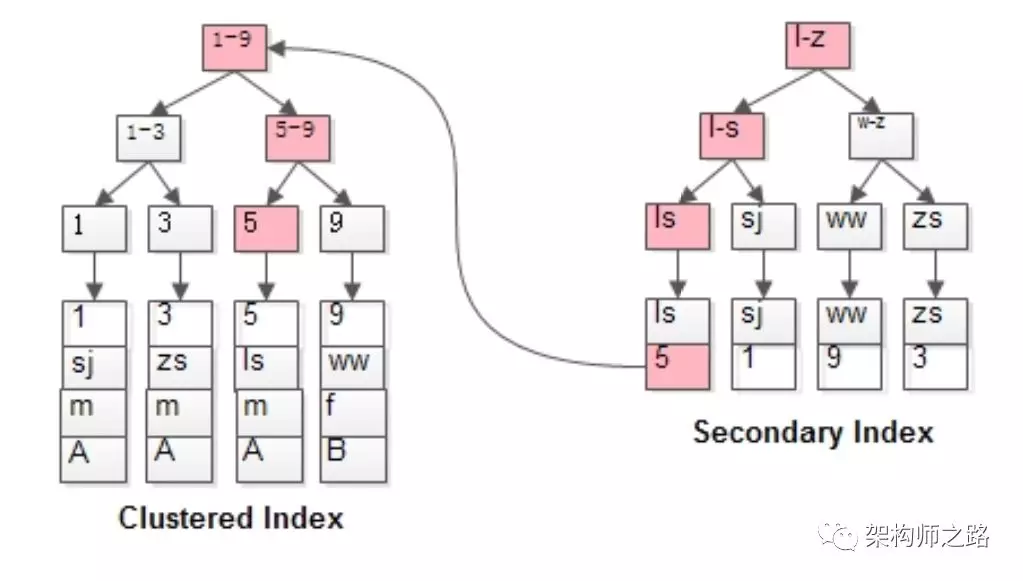
會先通過name輔助索引定位到B+樹的葉子節點得到id=5,再通過聚集索引定位到行記錄。
畫外音:所以,其實掃了2遍索引樹。
三,總結
MyISAM和InnoDB都使用B+樹來實現索引:
-
MyISAM的索引與資料分開儲存
-
MyISAM的索引葉子儲存指標,主鍵索引與普通索引無太大區別
-
InnoDB的聚集索引和資料行統一儲存
-
InnoDB的聚集索引儲存資料行本身,普通索引儲存主鍵
-
InnoDB一定有且只有一個聚集索引
-
InnoDB建議使用趨勢遞增整數作為PK,而不宜使用較長的列作為PK