
秒級展現的百萬級大清單報表怎麼做
資料查詢業務中,有時會碰到資料量很大的清單報表。由於使用者輸入的查詢條件可能很寬泛,因此會從資料庫中查出幾百上千萬甚至過億行的記錄,常見的包括銀行流水記錄,物流明細等。呈現時如果等著把這些記錄全部檢索出來再生成報表,那會需要很長時間,使用者體驗自然會非常惡劣。而且,報表一般採用記憶體運算機制,大多數情況下記憶體裡也裝不下這麼多資料。所以,我們一般都會使用分頁呈現的方式,儘量快速地呈現出第一頁,然後使用者可以隨意翻頁顯示,每次只顯示一頁,也不會造成記憶體溢位。
傳統分頁呈現的實現,一般都會使用資料庫的分頁機制來做,利用資料庫提供的返回指定行號範圍內記錄的語法。介面端根據當前頁號計算出行號範圍(每頁顯示固定行數)作為引數拼入 SQL 中,資料庫就會只返回當前頁的記錄,從而實現分頁呈現的效果。
不過,這樣做會有兩個問題:
1. 翻頁時效率較差
用這種辦法呈現第一頁一般都會比較快,但向後翻頁時,所使用的取數 SQL 會被再次執行,並且將前面頁涉及的記錄跳過。對於有些沒有 OFFSET 關鍵字的資料庫,就只能由介面端自行跳過這些資料(取出後丟棄),而像 ORACLE 還需要用子查詢產生一個序號才能再用序號做過濾。這些動作都會降低效率,浪費時間,前幾頁還感覺不明顯,但如果頁號比較大時,翻頁就會有等待感了。
2. 可能出現數據不一致
用這種辦法翻頁,每次按頁取數時都需要獨立地發出 SQL。這樣,如果在兩頁取數之間又有了插入、刪除動作,那麼取的數反映的是最新的資料情況,很可能和原來的頁號匹配不上。例如,每頁 20 行,在第 1 頁取出後,使用者還沒有翻第 2 頁前,第 1 頁包含的 20 行記錄中被刪除了 1 行,那麼使用者翻頁時取出的第 2 頁的第 1 行實際上是刪除操作前的第 22 行記錄,而原來的第 21 行實際上落到第 1 頁去了,如果要看,還要翻回第 1 頁才能看到。如果還要基於取出的資料做彙總統計,那就會出現錯誤、不一致的結果。
為了克服這兩個問題,有時候我們還會用另一種方法,用 SQL 遊標從資料庫中取數,在取出一頁呈現後,但並不終止這個遊標,在翻下一頁的時候再繼續取數。這種方法能有效地克服上述兩個問題,翻頁效率較高,而且不會發生不一致的情況。不過,絕大多數的資料庫遊標只能單向從前往後取數,表現在介面上就只能向後翻頁了,這一點很難向業務使用者交代,所以很少用這種辦法。
當然,我們也可以結合這兩種辦法,向後翻頁時用遊標,一旦需要向前翻頁,就重新執行取數 SQL。這樣會比每次分頁都重新取數的體驗好一些,但並沒有在根本上解決問題。
潤乾報表方案
下面介紹的潤乾報表方案,提供的大報表功能可以支援海量清單報表的秒級查詢。在這個方案中,取數和呈現採用兩個非同步執行緒,取數執行緒發出 SQL 後不斷取出資料快取到本地,由呈現執行緒從本地快取中獲取資料進行顯示。這樣,已經取出並快取的資料就能快速呈現,不再有等待感;而取數執行緒所涉及的 SQL,在資料庫中保持同一個事務,也不會有不一致的問題,前面提到的兩個問題全部得以完美解決。
同時,藉助集檔案儲存格式,報表還可以按行號隨機訪問記錄,而不用每次通過遍歷查詢資料。也就是說,這種儲存格式支援跳轉到任意頁訪問,從而極大地改善了使用者體驗。不過,由於採用了非同步機制,頁面端顯示的總頁數和總記錄數會隨著取數過程不斷變化。
大清單報表執行原理:

需要注意的是,大清單報表中用到的非同步機制和集檔案儲存都是在集算器的基礎上實現的,因此該功能需要“整合集算器”功能支援,並不包含在潤乾報表基礎版中。
下面通過舉例來說明潤乾海量大清單報表(以下簡稱:大報表)的開發使用過程。
SQL 源大報表
首先來看一種最基礎的大報表,即報表資料來源於資料庫的情況。例子中我們需要根據日期範圍查詢訂單表的交易資訊,由於資料規模較大,因此需要使用大清單報表呈現。
製作報表模板
與普通報表開發一樣,設定引數、準備資料集、繪製報表模板。
報表引數為查詢日期起止:

資料集根據引數查詢訂單表 SQL:
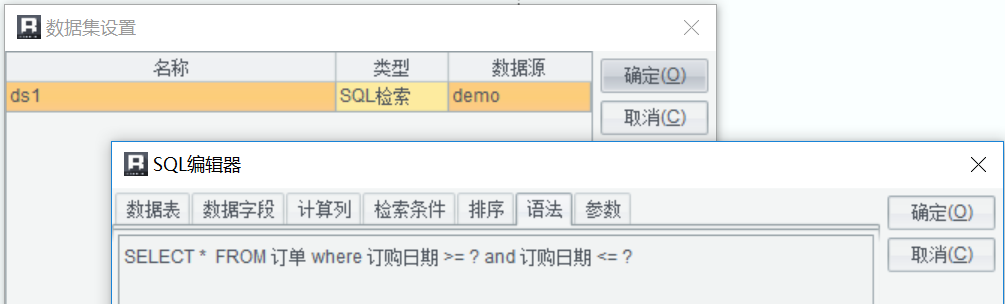
報表模板:

設定大資料集
與普通報表不同,需要在潤乾報表屬性(報表 - 報表屬性)中設定“大資料集名稱”,指向資料集 ds1,直接利用 SQL 完成非同步取數。
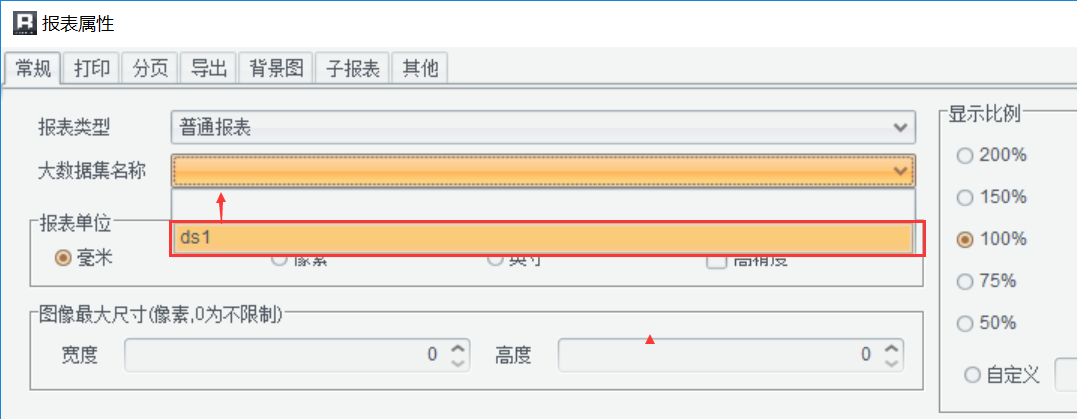
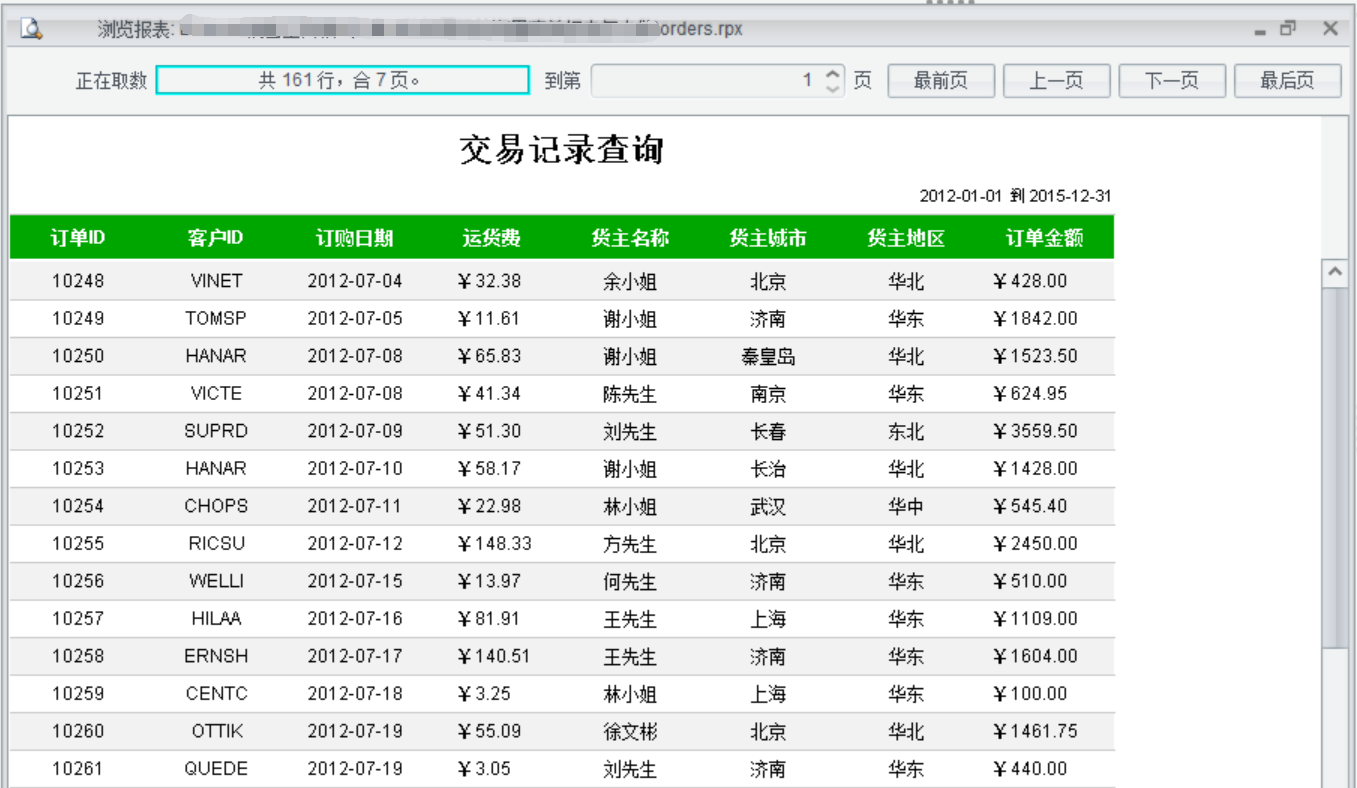
設定完成後,在報表設計器 IDE 中即可瀏覽報表:
釋出到 WEB
與普通報表釋出類似,大清單報表也通過 JSP 以 tag-lib 的方式釋出。
<report:big name="report1" reportFileName="<%=report%>" needScroll="<%=scroll%>" params="<%=param.toString()%>" exceptionPage="/reportJsp/myError2.jsp" scrollWidth="100%" scrollHeight="100%" rowNumPerPage="20" fetchSize="1000" needImportEasyui="no" />
其中 rowNumPerPage 屬性為每頁顯示記錄數;fetchSize 為每次從資料來源讀取的資料量。完整發布的 JSP 可以參考報表安裝目錄下的樣例檔案:[report\web\webapps\demo\reportJsp\ showBigReport.jsp]。
WEB 端呈現效果:
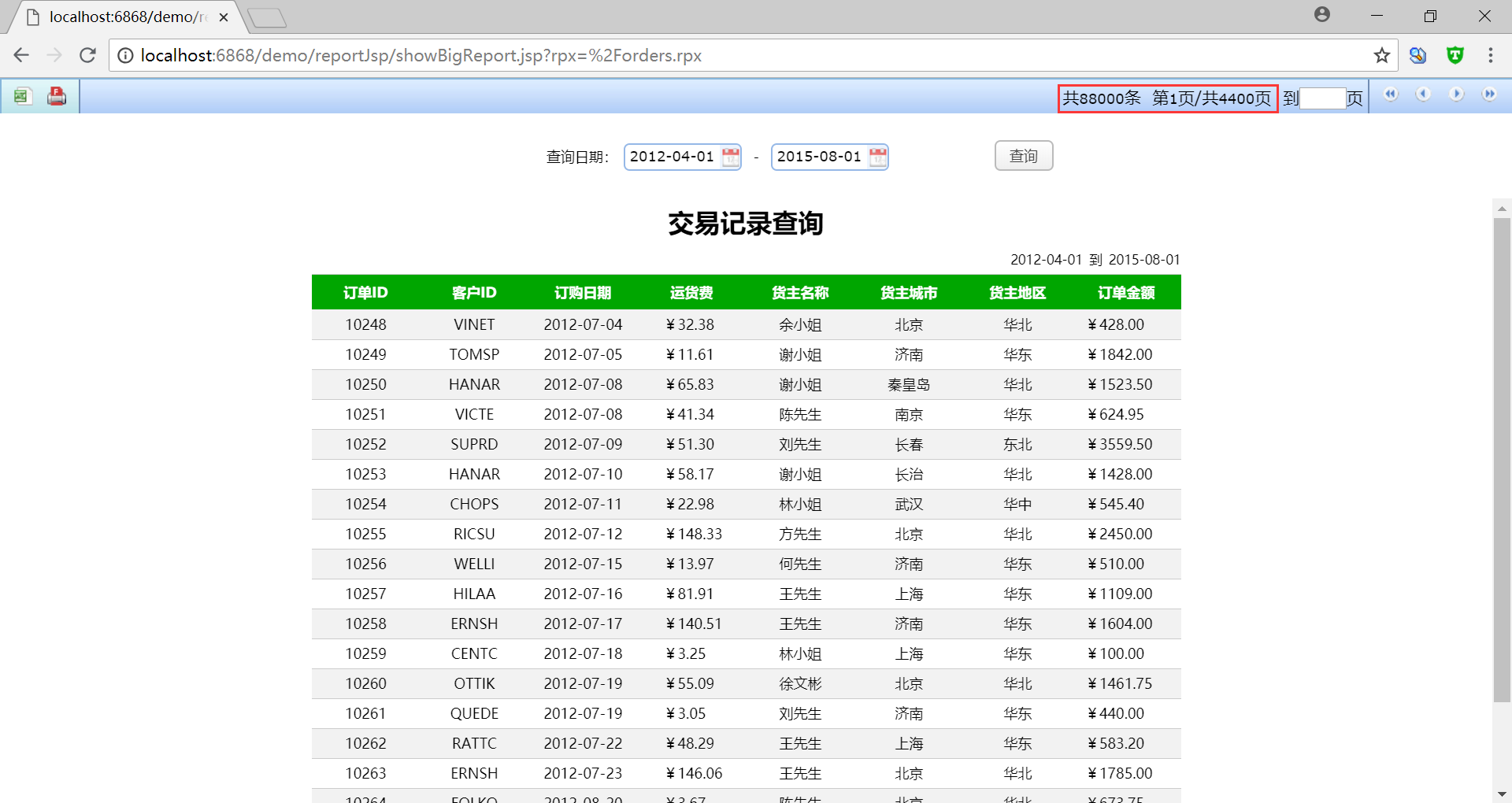
可以注意到,右上角的頁碼和總記錄條數隨著非同步執行緒不斷讀取資料而不斷變化。
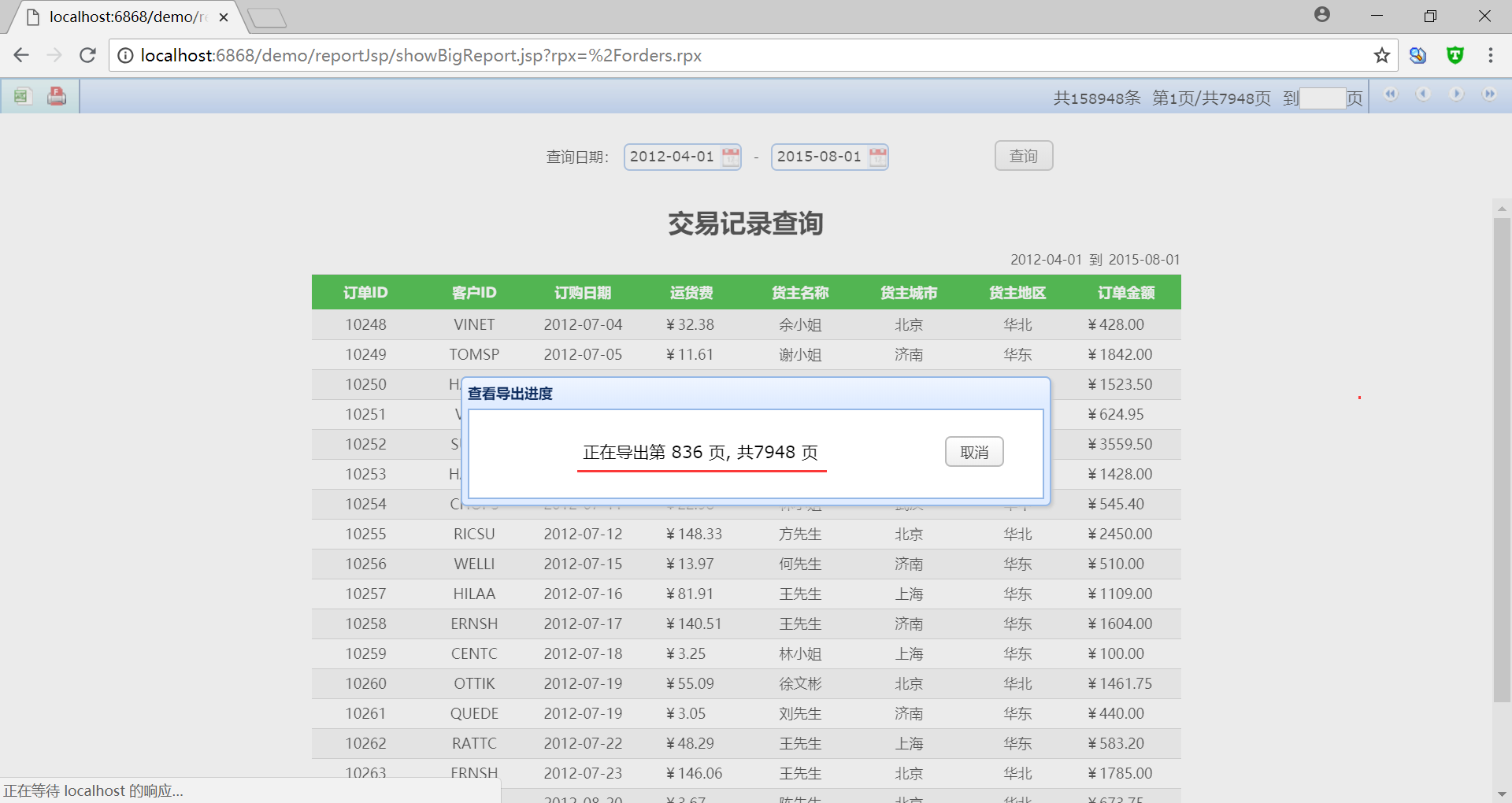
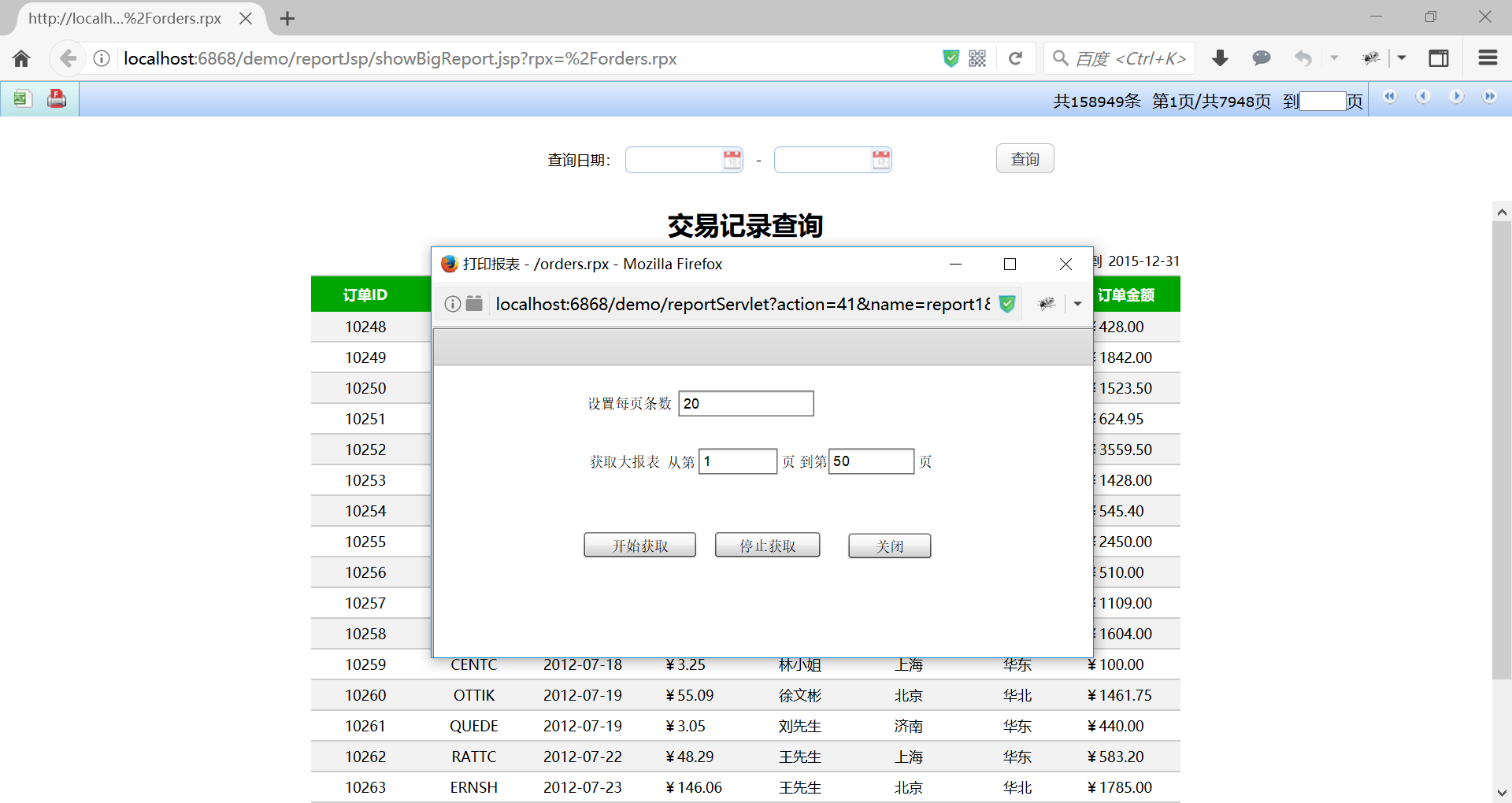
除了展現,在潤乾報表中還支援對大清單報表匯出 Excel 和列印。
匯出
列印
非 SQL 源大報表
當海量資料來源非 RDB 時,由於無法利用資料庫分頁,因此無法通過 SQL 實現非同步大報表。針對這一問題,潤乾報表的大報表方案中,採用了兩階段非同步執行緒,其中由集算器定義取數執行緒負責從非 RDB 資料來源取數並快取資料,再由呈現執行緒負責讀取快取並分頁展現。
下面以檔案資料為例,說明非 RDB 資料來源的大報表開發過程。例子中的衛星資料以檔案(CSV)方式儲存,資料規模較大,是典型的非 RDB 資料來源。現在我們要按照日期查詢某日風速、溫度等明細資訊。
報表資料準備
首先,我們藉助潤乾報表的集算器資料集讀取檔案資料,併為報表返回遊標。集算器 SPL 指令碼如下:
|
A |
|
|
1 |
=file(“source.csv”)[email protected](;,",") |
|
2 |
=A1.select(時間 == d_time) |
|
3 |
return A2 |
A1 建立檔案遊標;
A2 在遊標執行時對資料進行過濾(此時遊標尚未執行,資料並未取出);
A3 返回遊標過濾結果,為報表提供資料。
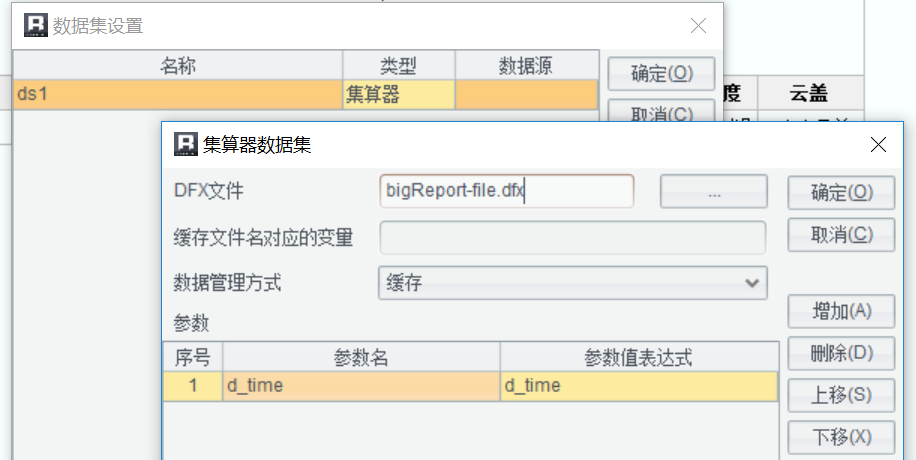
將 SPL 指令碼儲存為 bigReport-file.dfx,並在報表中作為資料集引入:
設計報表模板
接下來,我們根據所準備的資料製作報表模板:

同時設定大資料集:

釋出到 WEB
然後,將做好的報表釋出到 WEB 端:
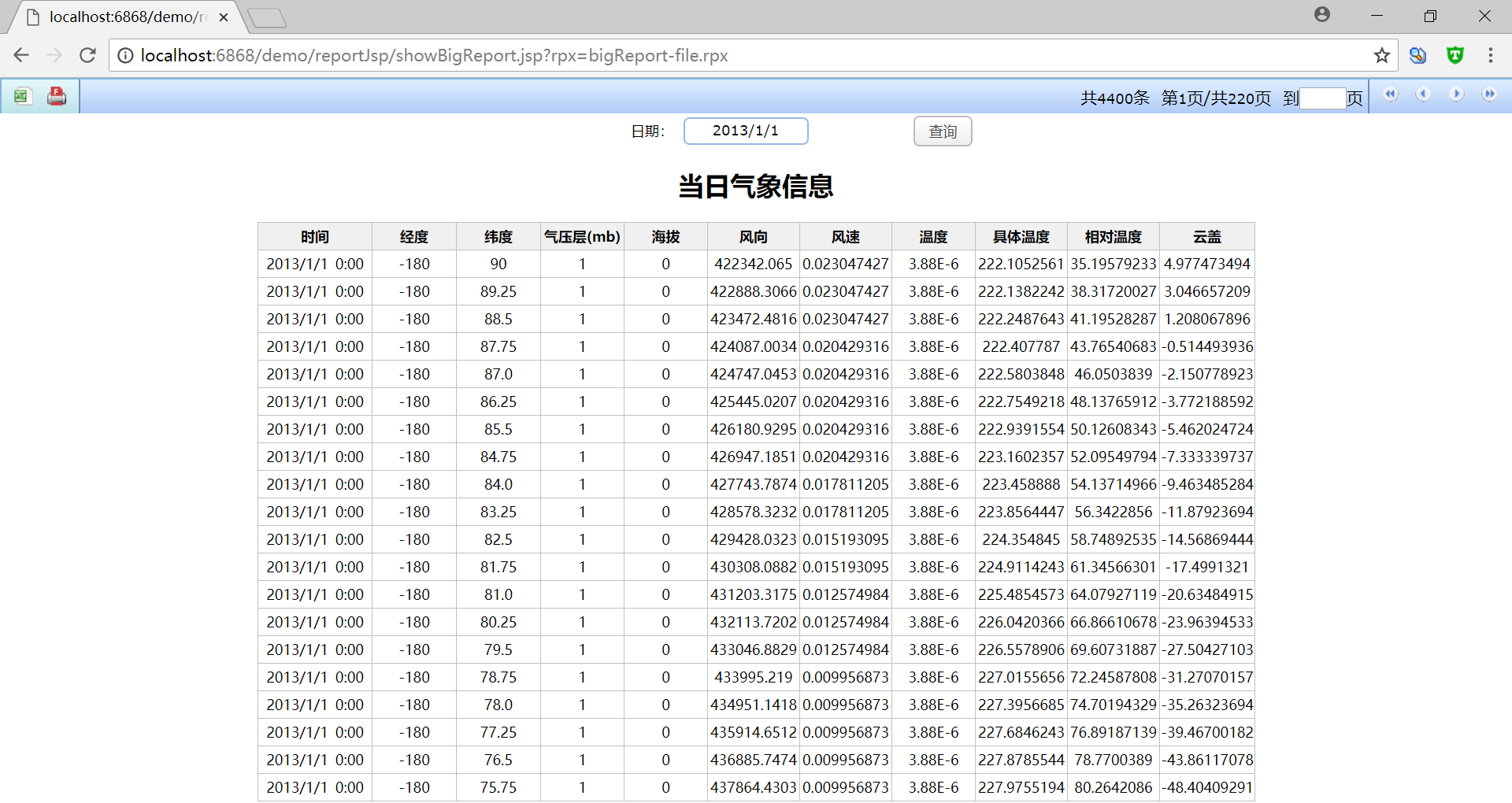
是不是很簡單? 這個例子顯示了在開發報表時如果涉及海量非 RDB 資料,潤乾報表可以藉助集算器對多種資料來源型別的支援能力,實現大報表開發與呈現。
使用大報表注意事項
上面介紹了開發大報表該有的正確姿勢,但任何功能都不是萬能的,使用大報表也有需要注意的地方:
1、不排序
大報表的資料集都比較大,如果在意響應時間(誰會不在意呢),那麼應該儘量不對資料集進行全表排序(注意我說的是全表排序),畢竟,等排完序再呈現,時間已經過去很久了……
2、不適合高併發場景
大報表採用非同步機制,將資料分批載入到記憶體再交給前端呈現,減少了記憶體佔用,但同時增加了 CPU 和磁碟 I/O 負載,併發高時 CPU 和硬碟可能成為瓶頸從而影響呈現效果,因此大報表不適合高併發的場景。
本文主要介紹了 RDB 和非 RDB 資料來源情況下大清單報表的開發方法,在下一篇《百萬級分組大報表開發與呈現》中,我們將進一步介紹帶有彙總值的大報表和分組大報表的實現過程。