
一個線上小問題解決過程 —— java執行緒池使用注意點
表象和場景
最近小夥伴在凌晨0點40分左右會收到某臺伺服器報警,cpu使用率過高(達到95%),但是不到10分鐘使用率降到45%,在之後5分鐘內降到10%以內,服務恢復。
背景:公司是用微服務架構,某個產品大約有30多個微服務,前端用阿里雲的SLB,架了nginx叢集;
為了節省機器成本,某些機器上部署了多個服務,單個服務也部署在多個機器上,互為備份
通過consul來做服務註冊與發現
分析
某個機器出現報警cpu過高,過幾分鐘就不會出現了,有時效性
排查思路:
思路一:根據監控內容檢視;(包括這個機器的效能資料,應用服務日誌等)
思路二:蹲點出現立馬去伺服器看現場資訊;
思路三:時間節點比較特殊,按照經驗,可能會出現的地方思考:半夜出問題週期這麼奇怪,很有可能定時任務類沒有處理好導致;
根據分析思路找問題
思路一:
根據監控檢視機器效能資料,發現這個機器的B服務cpu使用率達到了80%,基本確認是該服務問題;
檢視該服務日誌,沒有任何錯誤資訊,看到介面呼叫情況中有異樣,在介面監控中看到某個對外的介面被呼叫次數暴增,是平時的100倍+,而且都是A服務呼叫的,都集中在報警的這段時間內。確認是A服務發起的呼叫引起的問題;
檢視A服務呼叫的地方,去排查業務,確認最終問題。
思路二:
蹲點出現立馬去看現場資訊:檢視cpu使用情況,檢視哪個程序使用率高,檢視執行緒,數量和dump執行緒內容,具體乾的事情,找到結果是B服務的某個對外介面執行執行緒多,檢視日誌或根據業務排查場景,得到是A服務呼叫引起的問題。
思路三:
通過定時任務出發,根據任務排程中心檢視配置的定時任務時間,在這個週期之內的任務有哪些,針對具體的任務業務場景去分析,結合日誌 和 程式碼 很快也可以找到問題了。
具體問題說明
A服務的部分程式碼說明: 分頁從資料來源中獲取List<BillPlanPO>,呼叫如下process方法 @Async public void process(List<BillPlanPO> billPlanPOs) { if (CollectionUtils.isEmpty(billPlanPOs)) { return; } billPlanPOs.forEach(item -> { calLateFee(item); }); } calLateFee 方法內部呼叫B服務的介面。
1.分頁從資料來源獲取資料速度很快
2.通過非同步呼叫process方法(非同步呼叫執行緒池沒有自己配置,使用springboot框架自帶的)
3.每一個billPlanPO去呼叫B服務的介面;而B服務處理一個的速度較慢。
結論:導致B服務瞬間壓力很大,因為A服務獲取List<BillPlanPO>速度很快,又是非同步執行緒呼叫。
找到問題,解決過程就簡單多了。
簡單介紹下springboot中非同步執行緒池
預設配置:
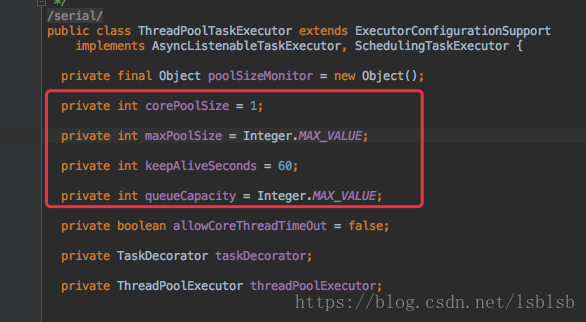
corePoolSize:表示執行緒池核心執行緒,正常情況下開啟的執行緒數量。
queueCapacity:當核心執行緒都在跑任務,還有多餘的任務會存到此處。
maxPoolSize:如果queueCapacity存滿了,還有任務就會啟動更多的執行緒,直到執行緒數達到maxPoolSize。如果還有任務,則根據拒絕策略進行處理。
針對如上問題,添加了下面程式碼:
import java.util.concurrent.ThreadPoolExecutor;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.task.AsyncTaskExecutor;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
/**
* 配置執行緒池
*/
@EnableAsync
@Configuration
public class ThreadPoolsConfig {
/**
* 執行緒相關引數
*/
@Value("${pay.threadNamePrefix}")
private String threadNamePrefix; // 配置執行緒池中的執行緒名稱字首
@Value("${pay.corePoolSize}")
private Integer corePoolSize; // 配置執行緒池中的核心執行緒數
@Value("${pay.maxPoolSize}")
private Integer maxPoolSize; // 配置最大執行緒數
@Value("${pay.queueCapacity}")
private Integer queueCapacity; // 配置佇列大小
/**
* 執行緒池配置
*/
@Bean
public AsyncTaskExecutor paymentTaskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setThreadNamePrefix(threadNamePrefix);
executor.setCorePoolSize(corePoolSize);
executor.setMaxPoolSize(maxPoolSize);
executor.setQueueCapacity(queueCapacity);
/**
* 當任務數量超過MaxPoolSize和QueueCapacity時使用的策略,該策略是呼叫任務的執行緒執行
*/
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
return executor;
}
}另外幾個細節注意點:
a.corePoolSize數量配置
/**
* IO密集型任務 = 一般為2*CPU核心數(常出現於執行緒中:資料庫資料互動、檔案上傳下載、網路資料傳輸等等)
* CPU密集型任務 = 一般為CPU核心數+1(常出現於執行緒中:複雜演算法)
* 混合型任務 = 視機器配置和複雜度自測而定
*/
private static int corePoolSize = Runtime.getRuntime().availableProcessors();
b.當佇列滿了之後的處理,setRejectedExecutionHandler,根據場景看需要怎麼樣的拒絕策略
ThreadPoolExecutor自身提供了4種策略
1.CallerRunsPolicy :這個策略重試添加當前的任務,他會自動重複呼叫 execute() 方法,直到成功。
2.AbortPolicy :對拒絕任務拋棄處理,並且丟擲異常。
3.DiscardPolicy :對拒絕任務直接無聲拋棄,沒有異常資訊。
4.DiscardOldestPolicy :對拒絕任務不拋棄,而是拋棄佇列裡面等待最久的一個執行緒,然後把拒絕任務加到佇列。
扯遠了,打住,根據調整,測試環境走一波。
驗證與觀察
通過各種工具壓一波,問題已解決,根據資源情況配置合適的執行緒池引數。
釋出後,線上驗證通過,晚上可以安靜的睡覺了~
其他建議
大部分線上問題,都是一個很小的點引起的,排查是一個反向推導的過程,這個過程往往比理解原因或者解決問題複雜。
問題排查是複雜的,不可控的,所以不要把排查和解決混在一起,儘量先解決、再排查。解決的方式基本上都是那麼幾板斧:重啟、回滾、擴容、降級、遷移等。
系統要儘可能的對外暴露內部狀態和干預手段,比如說少打了一句日誌,沒把變數輸出出來,那麼出現問題的時候很不但要用某些複雜的工具去查詢變數,而且很有可能要多繞一個大圈。
系統是不穩定的,所以對於高可用架構設計來說,隔離是必須的,不管是何種依賴方式,都需要考慮“實在不行了”的情況。
問題的原因、傳播路徑和現象不是一一對應的。同一個問題,這次的表現是多打了一行WARN日誌,下次可能就是一次系統雪崩。墨菲定律,如果有可能出問題,那一定會出問題。
提前準備
a.監控
b.日誌(分維度過濾和查詢),集中檢索
c.儲存現場
d.報警機制,(機器與服務,業務層資料)
這個4點可以單獨寫很多內容,這裡只是備註下,出了問題才會想到這些內容何其重要,所以平時要更加積累去處理。
排查問題不是一個人的事情,最好拉個消防群,把各個崗位的人員一起處理(開發,運維,DBA,系統,硬體等),大家工作的細分也是有道理的,專業的人幹專業的事情。問題一定要先解決再排查,問題一定要先解決再排查,問題一定要先解決再排查~