
Python 爬取貓眼資料分析《無名之輩》為何能逆襲成黑馬?
本文首發在 CSDN 微信(ID:CSDNNews)。

最近幾天,有部國產電影因好評及口碑傳播而開始異軍突起以黑馬之勢逆襲,在朋友圈以及微博上都會不時看到相關內容,那便是由陳建斌、任素汐等主演的《無名之輩》。這樣一部沒有什麼特別大牌或流量明星,甚至名稱與海報都沒有什麼特色的國產電影卻引起了很多人的注意,更是在評分上直接將同期的如《毒液》、《神奇動物:格林德沃之罪》給 PK 了下去。這部劇從 16 日上映到現在,豆瓣評分 8.3 分,其中 5 星好評佔 34.8%,而在貓眼上好評則直接超過了 50%。看這個資料,還是一部不錯的國產劇。在一個貌似平常的日子,筆者用著一臺低配的 Mac 電腦跑了一下《無名之輩》貓眼的評論資料,來看看這部小成本喜劇片究竟值不值得看。

需要特別說明一下,為什麼要用貓眼的資料,而不用豆瓣的?主要還是因為豆瓣是直接渲染的 HTML,而貓眼的資料是 JSON,處理起來比較方便。
獲取貓眼介面資料
作為一個長期宅在家的程式設計師,對各種抓包簡直是信手拈來。在 Chrome 中檢視原始碼的模式,可以很清晰地看到介面,介面地址即為:
http://m.maoyan.com/mmdb/comments/movie/1208282.json?v=yes&offset=15
在 Python 中,我們可以很方便地使用 request 來發送網路請求,進而拿到返回結果:
def getMoveinfo(url) 根據上面的請求,我們能拿到此介面的返回資料,資料內容有很多資訊,但有很多資訊是我們並不需要的,先來總體看看返回的資料:
{
"cmts" 如此多的資料,我們感興趣的只有以下這幾個欄位:
nickName, cityName, content, startTime, score
接下來,進行我們比較重要的資料處理,從拿到的 JSON 資料中解析出需要的欄位:
def parseInfo(data):
data = json.loads(html)['cmts']
for item in data:
yield{
'date':item['startTime'],
'nickname':item['nickName'],
'city':item['cityName'],
'rate':item['score'],
'conment':item['content']
}
拿到資料後,我們就可以開始資料分析了。但是為了避免頻繁地去貓眼請求資料,需要將資料儲存起來,在這裡,筆者使用的是 SQLite3,放到資料庫中,更加方便後續的處理。儲存資料的程式碼如下:
def saveCommentInfo(moveId, nikename, comment, rate, city, start_time)
conn = sqlite3.connect('unknow_name.db')
conn.text_factory=str
cursor = conn.cursor()
ins="insert into comments values (?,?,?,?,?,?)"
v = (moveId, nikename, comment, rate, city, start_time)
cursor.execute(ins,v)
cursor.close()
conn.commit()
conn.close()
資料處理
因為前文我們是使用資料庫來進行資料儲存的,因此可以直接使用 SQL 來查詢自己想要的結果,比如評論前五的城市都有哪些:
SELECT city, count(*) rate_count FROM comments GROUP BY city ORDER BY rate_count DESC LIMIT 5
結果如下:
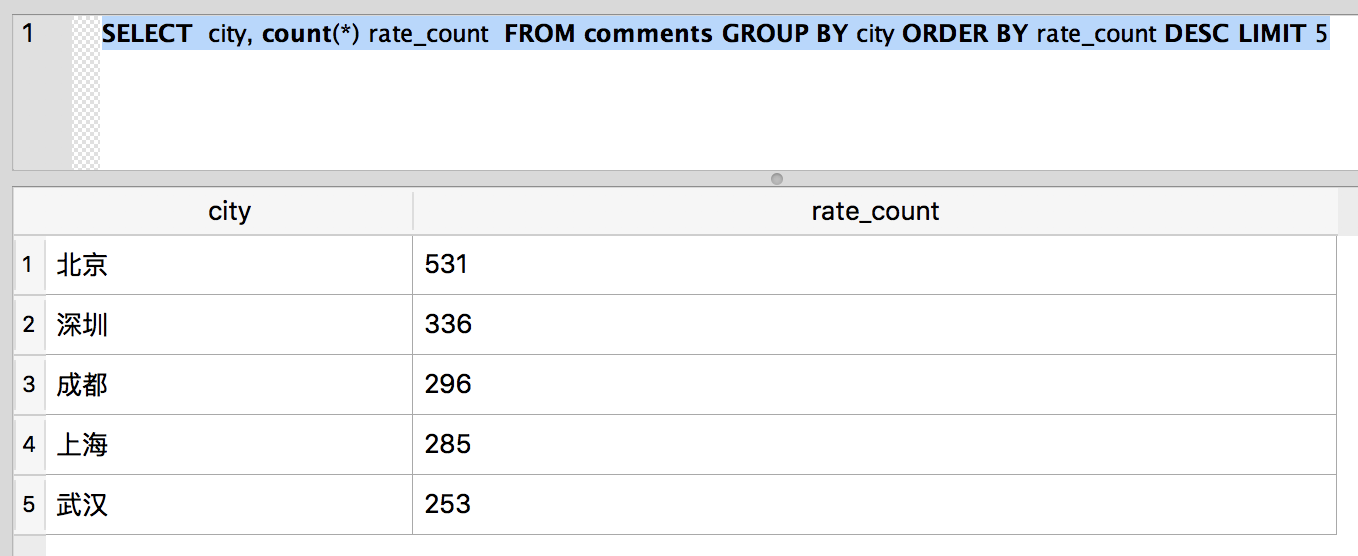
從上面的資料, 我們可以看出來,來自北京的評論數最多。
不僅如此,還可以使用更多的 SQL 語句來查詢想要的結果。比如每個評分的人數、所佔的比例等。如筆者有興趣,可以嘗試著去查詢一下資料,就是如此地簡單。
而為了更好地展示資料,我們使用 Pyecharts 這個庫來進行資料視覺化展示。
根據從貓眼拿到的資料,按照地理位置,直接使用 Pyecharts 來在中國地圖上展示資料:
data = pd.read_csv(f,sep='{',header=None,encoding='utf-8',names=['date','nickname','city','rate','comment'])
city = data.groupby(['city'])
city_com = city['rate'].agg(['mean','count'])
city_com.reset_index(inplace=True)
data_map = [(city_com['city'][i],city_com['count'][i]) for i in range(0,city_com.shape[0])]
geo = Geo("GEO地理位置分析",title_pos = "center",width = 1200,height = 800)
while True:
try:
attr,val = geo.cast(data_map)
geo.add("",attr,val,visual_range=[0,300],visual_text_color="#fff",
symbol_size=10, is_visualmap=True,maptype='china')
except ValueError as e:
e = e.message.split("No coordinate is specified for ")[1]
data_map = filter(lambda item: item[0] != e, data_map)
else :
break
geo.render('geo_city_location.html')
注:使用 Pyecharts 提供的資料地圖中,有一些貓眼資料中的城市找不到對應的從標,所以在程式碼中,GEO 添加出錯的城市,我們將其直接刪除,過濾掉了不少的資料。
使用 Python,就是如此簡單地生成了如下地圖:
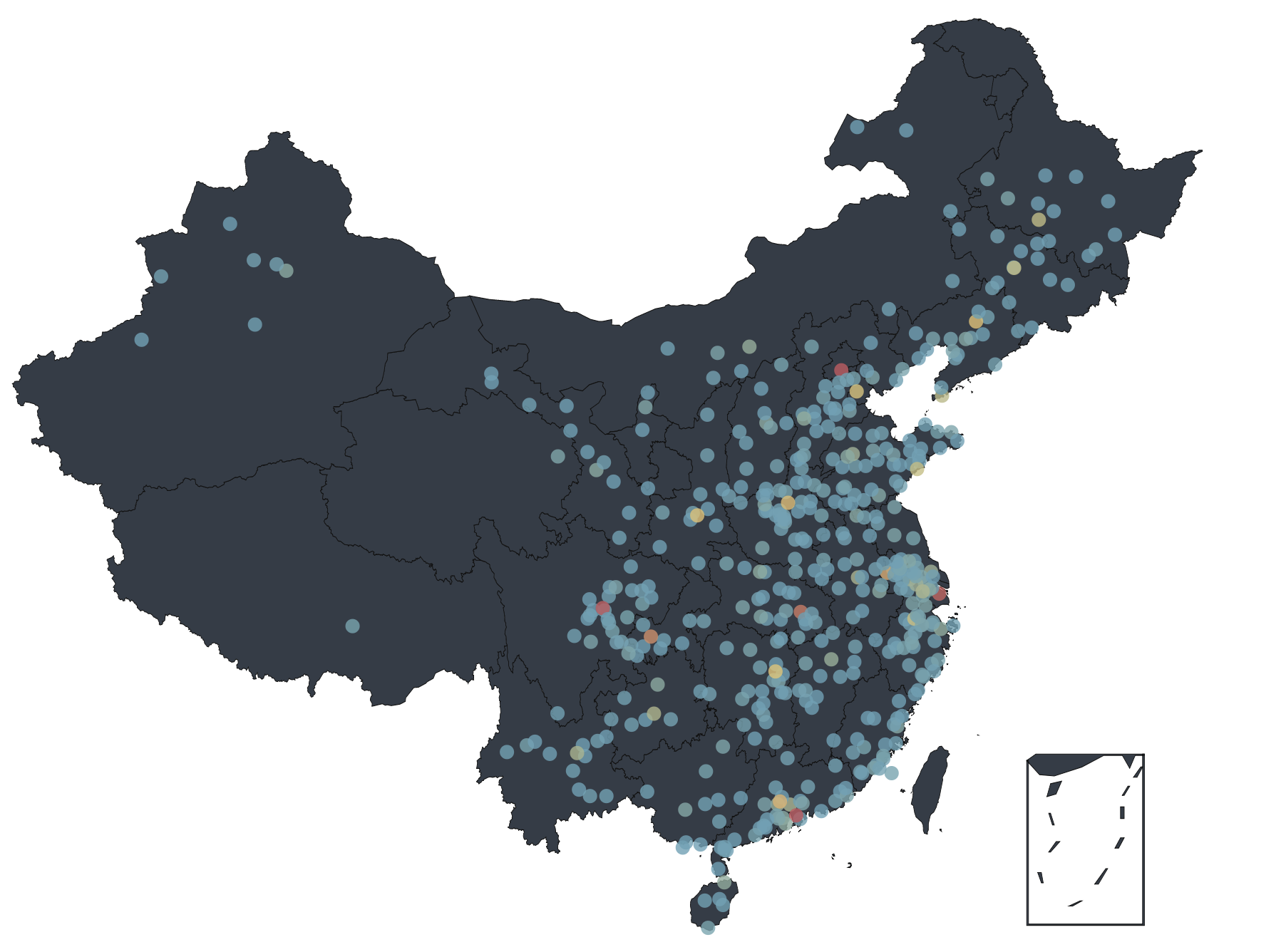
從視覺化資料中可以看出,既看電影又評論的人群主要分佈在中國東部,又以北京、上海、成都、深圳最多。雖然能從圖上看出來很多資料,但還是不夠直觀,如果想看到每個省/市的分佈情況,我們還需要進一步處理資料。
而在從貓眼中拿到的資料中,城市包含資料中具備縣城的資料,所以需要將拿到的資料做一次轉換,將所有的縣城轉換到對應省市裡去,然後再將同一個省市的評論數量相加,得到最後的結果。
data = pd.read_csv(f,sep='{',header=None,encoding='utf-8',names=['date','nickname','city','rate','comment'])
city = data.groupby(['city'])
city_com = city['rate'].agg(['mean','count'])
city_com.reset_index(inplace=True)
fo = open("citys.json",'r')
citys_info = fo.readlines()
citysJson = json.loads(str(citys_info[0]))
data_map_all = [(getRealName(city_com['city'][i], citysJson),city_com['count'][i]) for i in range(0,city_com.shape[0])]
data_map_list = {}
for item in data_map_all:
if data_map_list.has_key(item[0]):
value = data_map_list[item[0]]
value += item[1]
data_map_list[item[0]] = value
else:
data_map_list[item[0]] = item[1]
data_map = [(realKeys(key), data_map_list[key] ) for key in data_map_list.keys()]
def getRealName(name, jsonObj):
for item in jsonObj:
if item.startswith(name) :
return jsonObj[item]
return name
def realKeys(name):
return name.replace(u"省", "").replace(u"市", "")
.replace(u"回族自治區", "").replace(u"維吾爾自治區", "")
.replace(u"壯族自治區", "").replace(u"自治區", "")
經過上面的資料處理,使用 Pyecharts 提供的 map 來生成一個按省/市來展示的地圖:
def generateMap(data_map):
map = Map("城市評論數", width= 1200, height = 800, title_pos="center")
while True:
try:
attr,val = geo.cast(data_map)
map.add("",attr,val,visual_range=[0,800],
visual_text_color="#fff",symbol_size=5,
is_visualmap=True,maptype='china',
is_map_symbol_show=False,is_label_show=True,is_roam=False,
)
except ValueError as e:
e = e.message.split("No coordinate is specified for ")[1]
data_map = filter(lambda item: item[0] != e, data_map)
else :
break
map.render('city_rate_count.html')
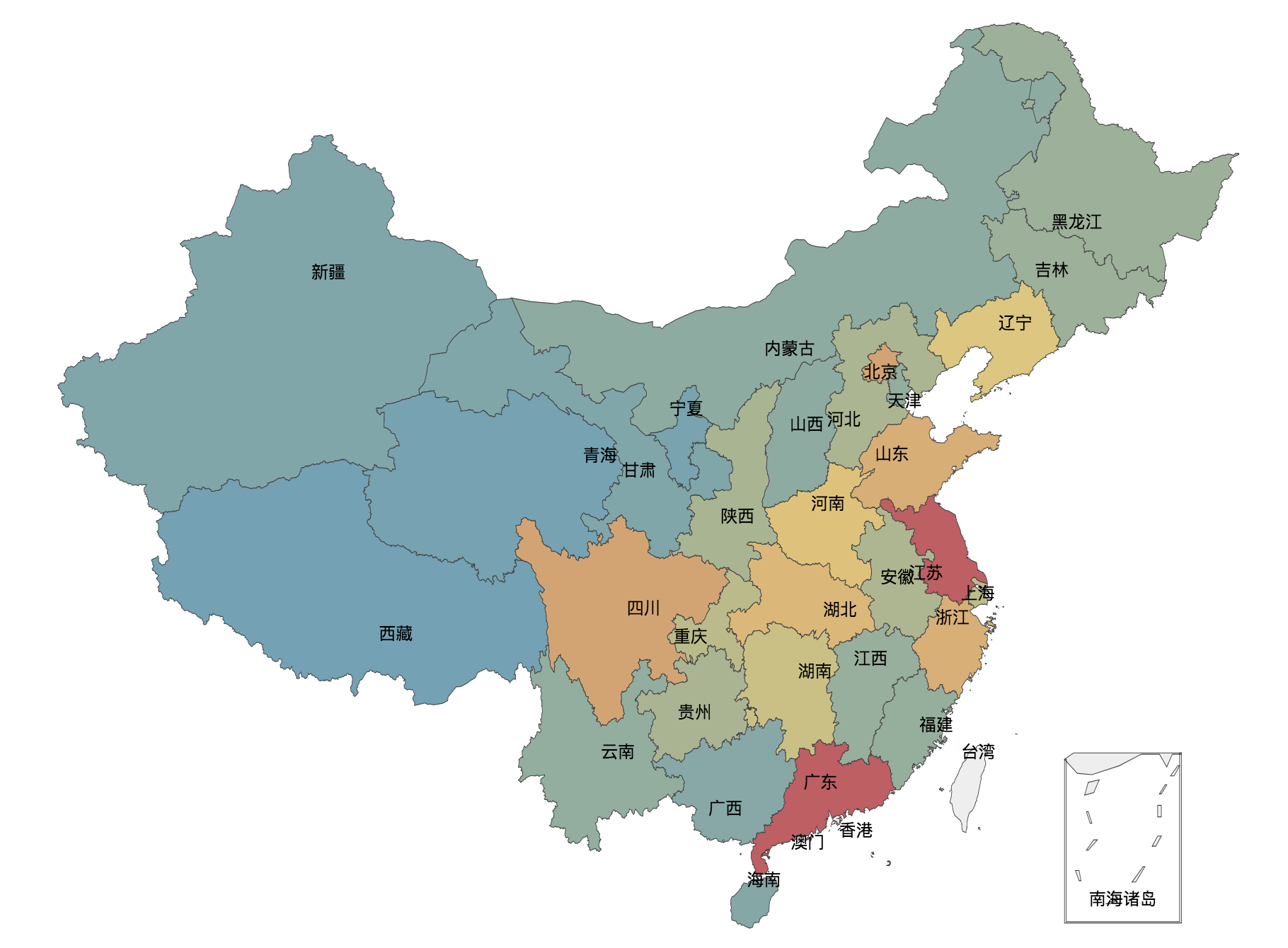
當然,我們還可以來視覺化一下每一個評分的人數,這個地方採用柱狀圖來顯示:
data = pd.read_csv(f,sep='{',header=None,encoding='utf-8',names=['date','nickname','city','rate','comment'])
# 按評分分類
rateData = data.groupby(['rate'])
rateDataCount = rateData["date"].agg([ "count"])
rateDataCount.reset_index(inplace=True)
count = rateDataCount.shape[0] - 1
attr = [rateDataCount["rate"][count - i] for i in range(0, rateDataCount.shape[0])]
v1 = [rateDataCount["count"][count - i] for i in range(0, rateDataCount.shape[0])]
bar = Bar("評分數量")
bar.add("數量",attr,v1,is_stack=True,xaxis_rotate=30,yaxix_min=4.2,
xaxis_interval=0,is_splitline_show=True)
bar.render("html/rate_count.html")
畫出來的圖,如下所示,在貓眼的資料中,五星好評的佔比超過了 50%,比豆瓣上 34.8% 的五星資料好很多。
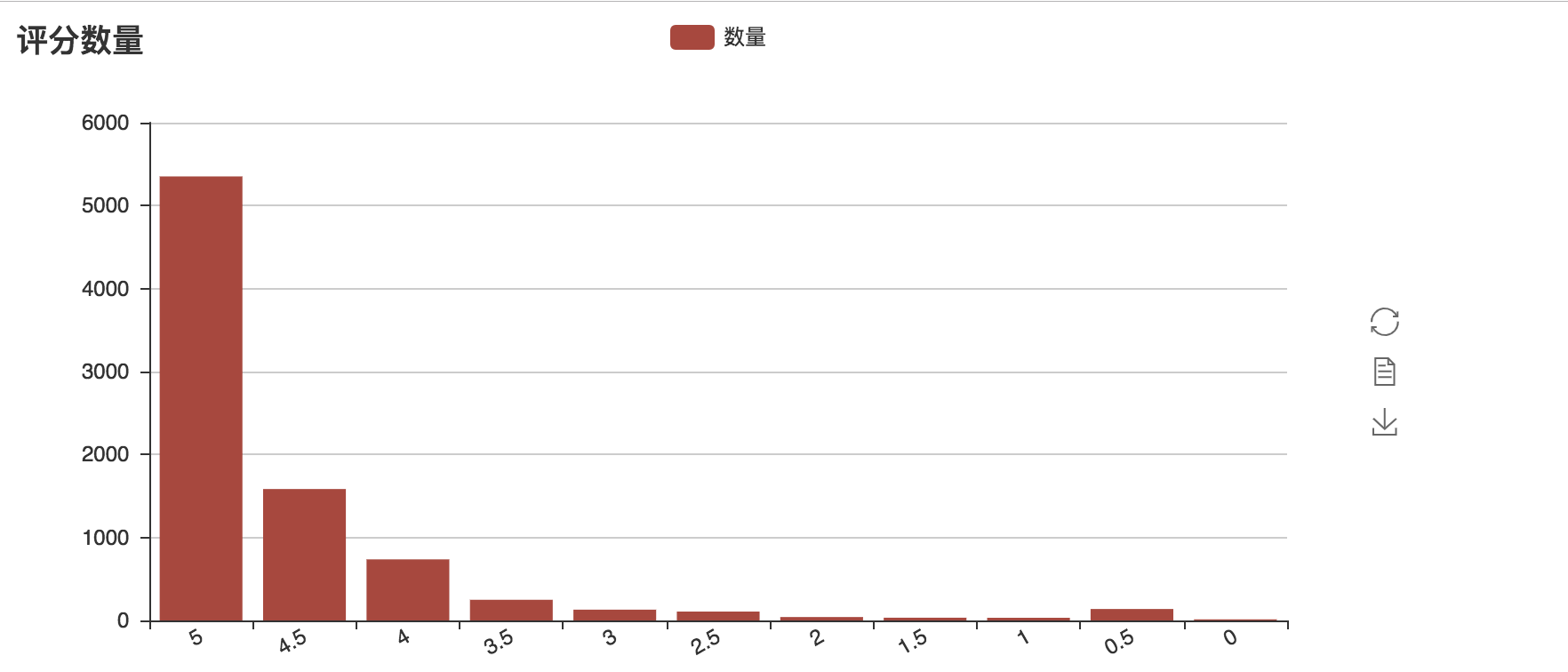
從以上觀眾分佈和評分的資料可以看到,這一部劇,觀眾朋友還是非常地喜歡。前面,從貓眼拿到了觀眾的評論資料。現在,筆者將通過 jieba 把評論進行分詞,然後通過 Wordcloud 製作詞雲,來看看,觀眾朋友們對《無名之輩》的整體評價:
data = pd.read_csv(f,sep='{',header=None,encoding='utf-8',names=['date','nickname','city','rate','comment'])
comment = jieba.cut(str(data['comment']),cut_all=False)
wl_space_split = " ".join(comment)
backgroudImage = np.array(Image.open(r"./unknow_3.png"))
stopword = STOPWORDS.copy()
wc = WordCloud(width=1920,height=1080,background_color='white',
mask=backgroudImage,
font_path="./Deng.ttf",
stopwords=stopword,max_font_size=400,
random_state=50)
wc.generate_from_text(wl_space_split)
plt.imshow(wc)
plt.axis("off")
wc.to_file('unknow_word_cloud.png')
匯出:

再說從這張詞雲圖我們可以明顯地看到“小人物”、“好看”、“喜劇”、“演技”這四個字非常地突出,歷來能夠稱得上黑馬的都是小成本並且反映小人物的荒誕喜劇為多,從這四個關鍵詞中我們似乎看出了這部電影究竟為什麼會收穫眾多好評。一如豆瓣上的一條短評所言:“不是愛情,勝似愛情。喪的剛剛好,黑的剛剛好,暖的剛剛好。有人說,中國沒有‘治癒系’的電影。從此片起,就有了。看這片,我們笑著流淚。刻畫底層人物的現實主義題材的電影不在少數,但此片是我近年來看過的,最具誠意、三觀最正,也最‘哀而不傷’的一部。你將充分感受到什麼叫‘真正的演技’,你將看到陳建斌任素汐章宇王硯輝等‘頂級演技天團’如何飆戲。真心期盼,從此片起,國產片將真正迎來‘好演員+好電影的春天’。”
傳送門
歡迎關注我的公眾號,一起交流技術事。
