
python爬取知乎專欄使用者評論資訊
工具:python3,pycharm,火狐瀏覽器 模組:json,requests,time
登入知乎,進入專欄。
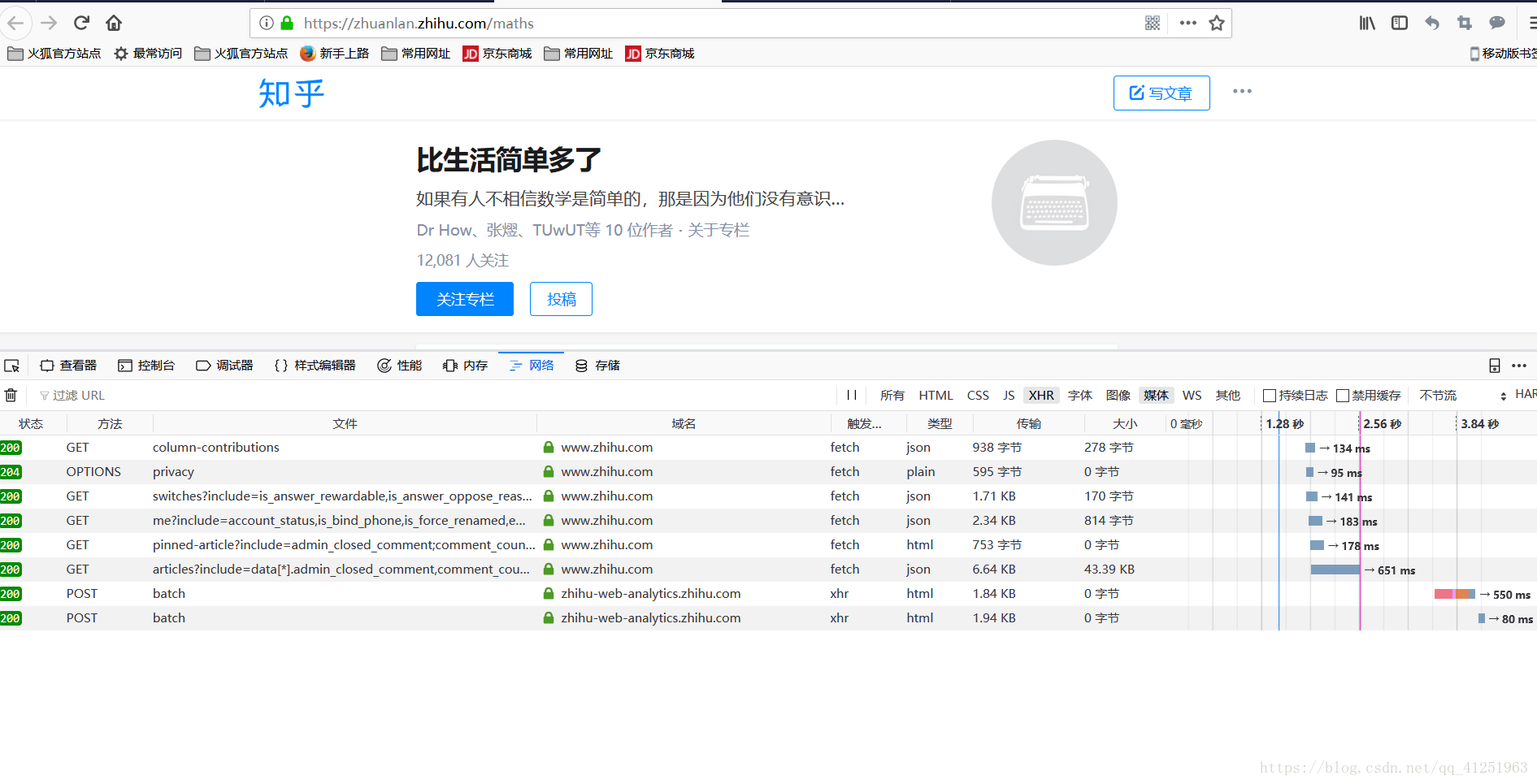
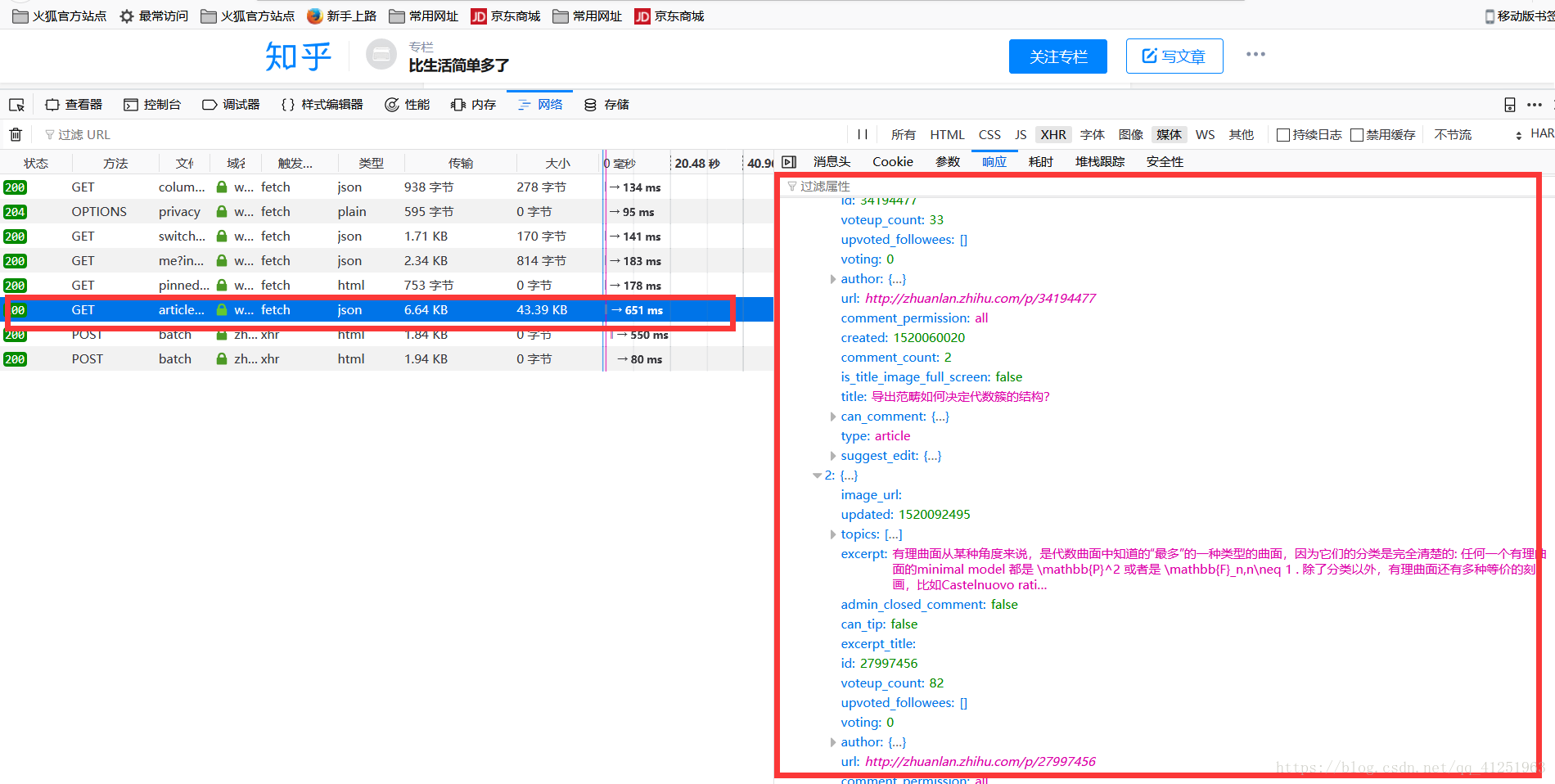
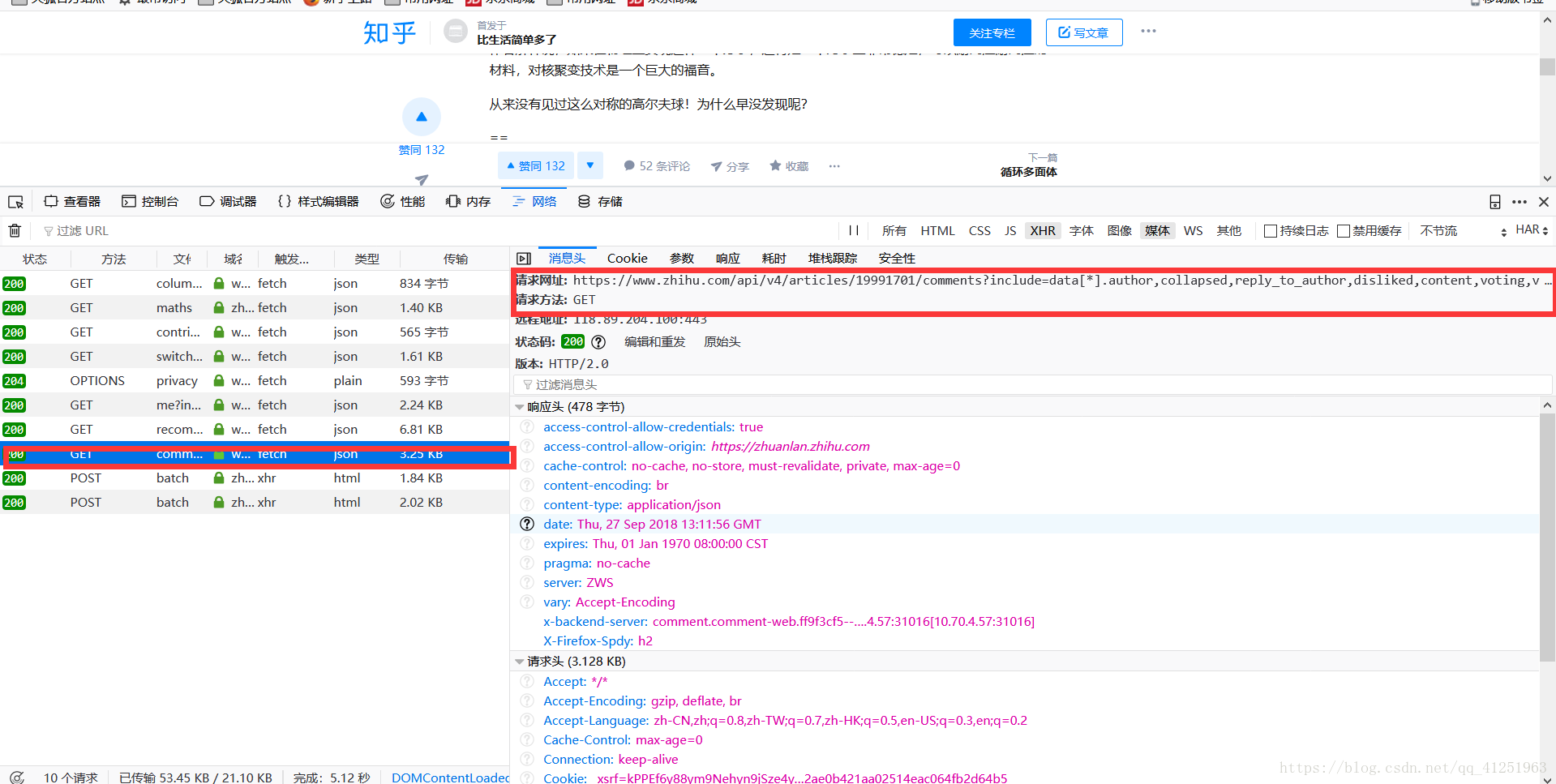
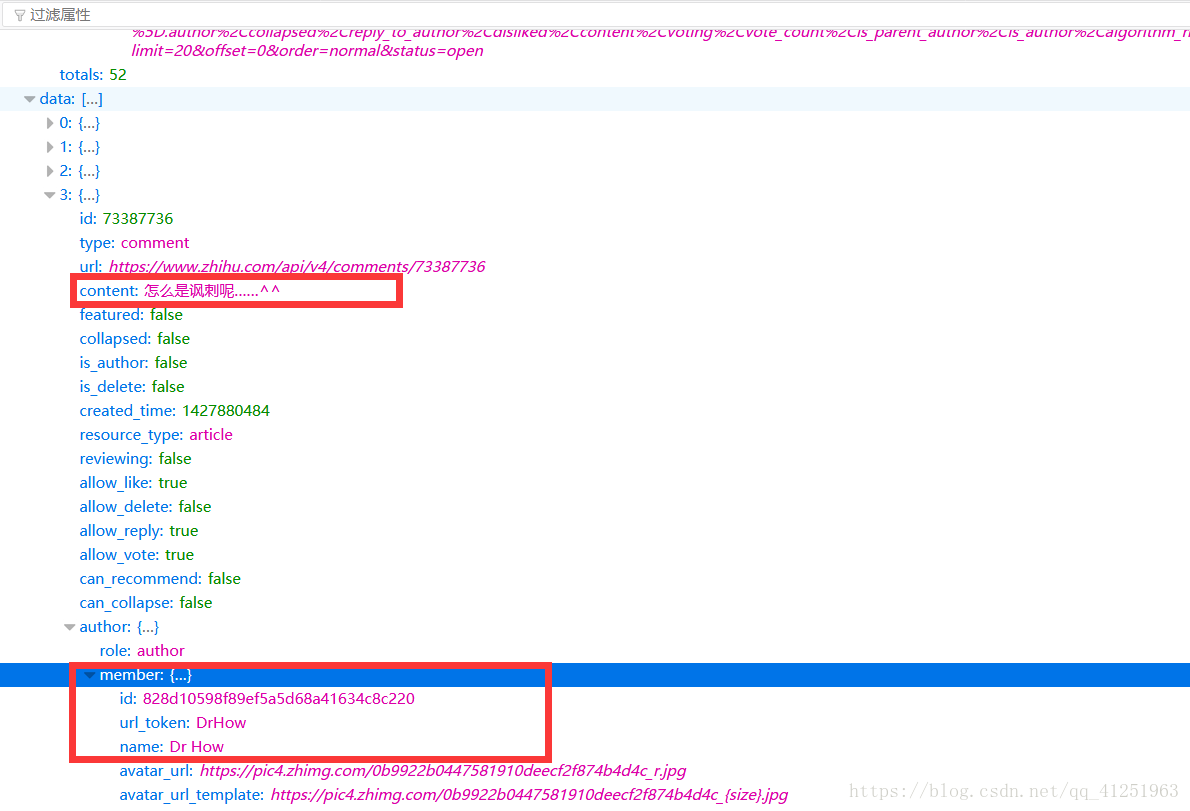
我們會發現一個問題,會發現這條資料的請求網址會很長,https://www.zhihu.com/api/v4/articles/19991701/comments?include=data[*].author,collapsed,reply_to_author,disliked,content,voting,vote_count,is_parent_author,is_author,algorithm_right&order=normal&limit=20&offset=0&status=open這樣寫到程式碼會很不方便。我們一看便知?後面攜帶的是引數。我們點選引數會發現一些資料。
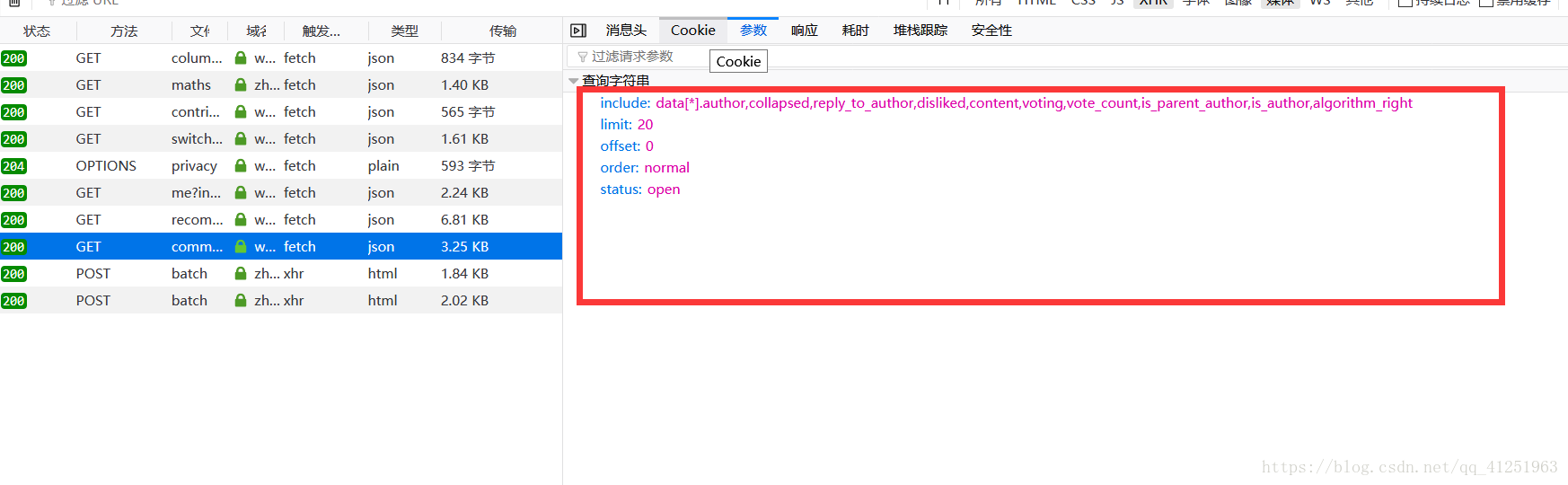
我們可以在請求的時候攜帶這些資料。用paramsrequests.get(url,params=date,headers=headers)
這樣請求的時候網址就可以寫成:https://www.zhihu.com/api/v4/articles/19991701/comments
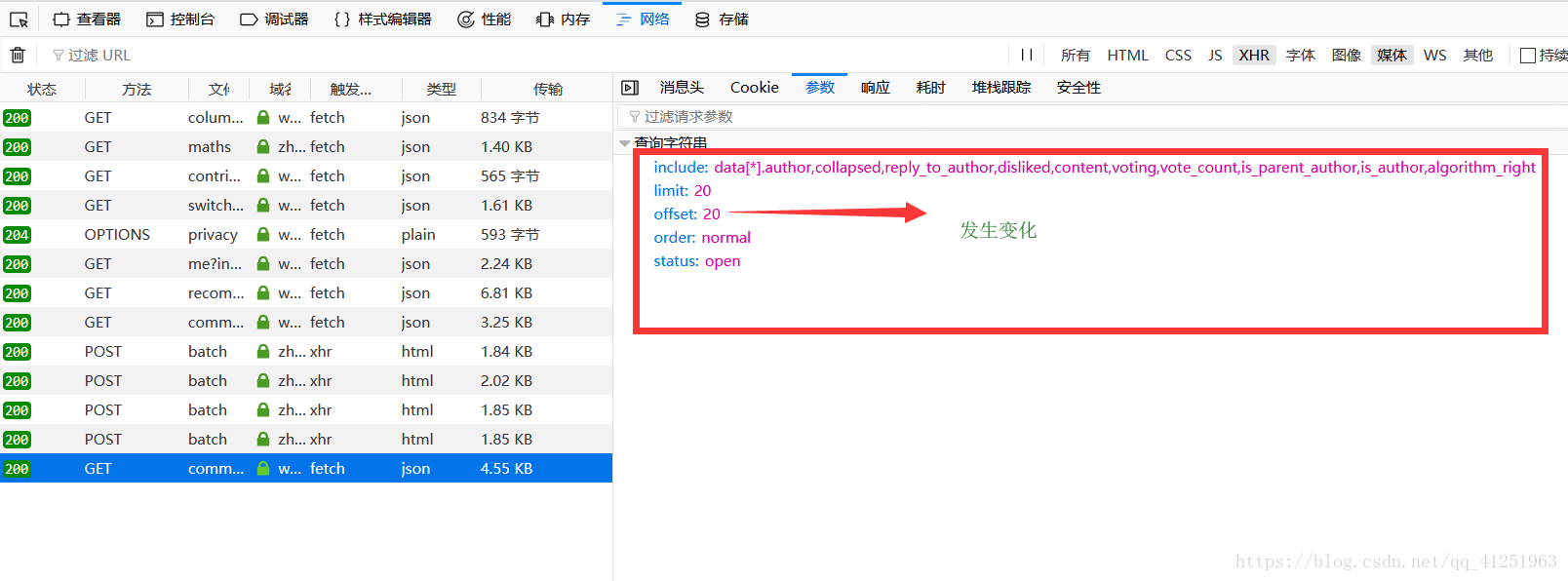
很顯然這裡有20條資料,並不是所有資料。我們點選評論的下一頁。
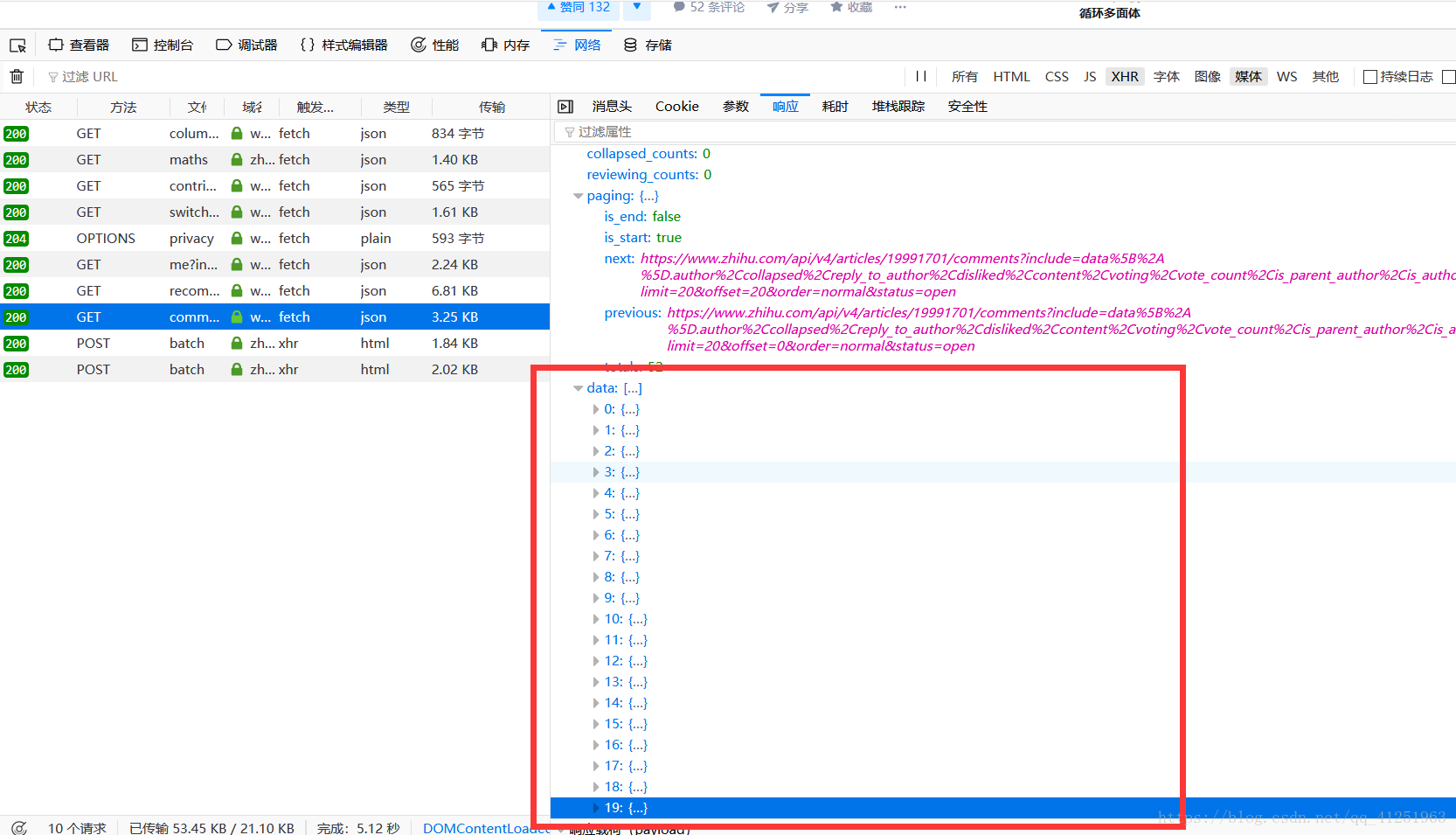
發現第二頁的資料,這樣也能獲取到第二頁的評論資訊 了。看一下引數有什麼變化。
完整程式碼:
import requests import json import time def content(a): url="https://www.zhihu.com/api/v4/articles/19991701/comments" date={ 'include':'data[*].author,collapsed,reply_to_author,disliked,content,voting,vote_count,is_parent_author,is_author,algorithm_right', 'limit':'20', 'offset':str(a), 'order':'normal', 'status':'open' } headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:57.0) Gecko/20100101 Firefox/57.0'} html=requests.get(url,params=date,headers=headers) #print(html.json()['data']) for i in html.json()['data']: content=i['content'] id=i['author']['member']['id'] name=i['author']['member']['name'] print(name+str(id)+":"+content) #資料寫入文件的過程中可能出現UnicodeEncodeError: 'gbk' codec can't encode character '\uXXX' in position XXX: illegal multibyte sequence #使用try,except忽略,並不影響資料的寫入。 with open("pinglun.txt",'a')as f: try: f.write(name+str(id)+":"+content) except: print("") if __name__ == '__main__': for i in range(0,4): content(i*20) time.sleep(5)
data用於拼接url,headers用於模擬瀏覽器,獲取到的json資料可以直接取到。將獲取的資料採用追加“a”的方式寫入到txt中。 資料寫入文件的過程中可能出現UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘\uXXX’ in position XXX: illegal multibyte sequence,使用try,except忽略,並不影響資料的寫入。 time.sleep()控制爬取速度。
程式碼寫的有些簡陋,主要說明思路