
高效能MySQL--建立高效能的索引
關於MySQL的優化,相信很多人都聽過這一條:避免使用select *來查詢欄位,而是要在select後面寫上具體的欄位。
那麼這麼做的原因相信大家都應該知道:減少資料量的傳輸。
但我要講的是另外一個原因:使用select *,就基本不可能使用到覆蓋索引(什麼是覆蓋索引,後面會說)。
而將一個本該可以用覆蓋索引的查詢變成了不能使用覆蓋索引的查詢,就會導致隨機I/O或回表查詢(回表查詢在介紹聚簇索引的時候會說)。
一、索引的型別
1、B-Tree索引
大部分的MySQL引擎都支援這種索引,它是使用B-TREE的資料結構來儲存資料(INNODB使用的B+TREE)。B+TREE是B-TREE的一個變種,區別是B+TREE為所有葉子結點增加了一個儲存指向下個葉子結點的鏈指標和所有關鍵字都在葉子結點中出現(關於B+TREE和B-TREE的詳細介紹,可以去百度搜下,這裡就不詳細介紹了)。
B-TREE通常就意味著裡面儲存的所有值都是有序的,並且查詢的時候,不用全表掃描,而是按照索引結構查詢,所以會更快。
適用查詢:
- 全值匹配。是指和索引中的所有列進行匹配。
- 匹配最左字首。就是多列索引的最左字首原則。例如一個多列索引為(A,B,C),當你的查詢中包括A或A,B或A,B,C都可以用到索引,如果只有B,則無法用到該索引。
- 匹配列字首。舉個栗子就是,像like 'abc%'可以用到索引,而like '%abc%'就無法用到該類索引。
- 匹配範圍值。其實就是範圍查詢,但記住,當多列索引中有一列用到範圍查詢時,那麼該列後面的索引都沒法被用到。例如還是又一個索引為(A,B,C),又一個查詢為where A=1, B>1, C=1,那麼這個查詢只會用到(A,B,C)中的A,B列,C是不會被用到。
- 只訪問索引的查詢。其實就是覆蓋索引查詢。
當然如果查詢滿足以上條件,當然也就可以用這些列進行排序。
2、雜湊索引
雜湊索引是基於雜湊表實現的。只支援精確索引查詢。在MySQL中,目前只有Memory引擎支援雜湊索引,但我們可以自定義雜湊索引。具體思路是這樣的:
在表中建立一列用來儲存雜湊值,然後還是用B-TREE索引進行查詢。下面是一個例項:
例如一個表中需要儲存大量的URL,如果正常使用B-TREE來儲存URL,儲存的內容就會很大,導致索引會很大。如果我們增加一列(url_hash)儲存URL的雜湊值,然後在這列上建立B-TREE索引,這樣做的效能會高很多。因為當資料量非常大的時候,雜湊會存在雜湊衝突,所以在查詢的時候要用到url和url_hash兩列進行篩選。如:
select id from url where url='www.baidu.com' and url_hash='123213512987';
至於雜湊演算法,可以考慮自己實現一個簡單的64位雜湊函式。注意這個自定義函式一定要返回整數,而不是字串。
3、全文索引
這是一種特殊型別的索引。後面會有一篇部落格單獨討論全文索引,這裡就不詳細說了。
二、索引的優點
- 索引大大減少了伺服器需要掃描的資料量
- 索引可以幫助伺服器避免排序和臨時表
- 索引可以將隨機I/O變成順序I/O
那麼索引就一定是最好的解決方案嗎?我們都知道維護索引需要做一些額外的工作,所以簡單的說,當使用索引利大於弊時,索引就是有效的。
三、高效能的索引策略
1、獨立的列
通常會看到一些不當的查詢使得MySQL無法使用已有的索引。例如
select id from users where id+1=5;
這種查詢是不會使用到索引的,而且這種查詢完全可以寫成
select id from users where id=4;
所以我們應該養成簡化WHERE條件的習慣,始終將索引列單獨放在比較符號的一側。
2、字首索引和索引選擇性
有時候我們需要索引很長的字串列,這時候我們就需要使用字首索引,在MySQL中,對於TEXT,BLOB和很長的字元列,必須使用字首索引,因為MySQL不允許索引這些列的所有長度。那麼相應的,字首索引必然會降低索引的選擇性。索引的選擇性是指,不重複的索引列與資料表的總記錄數的比值。
那麼怎麼才能找到字首索引和索引選擇性間的一個平衡呢?套用《高效能MySQL》中的一個栗子:
一張表中的一個欄位儲存的各個城市的名字。首先,我們找到最常見的城市列表:

然後嘗試下從3個字首開始:

可以看出這個與原來的差距還是挺大的。經過實現後,我們發現,當前綴索引長度為7時,比較合適:

我們還可以利用另外一種演算法計算下:計算選擇性

這是完整列的選擇性。然後我們看下當前綴索引分別為3,4,5,6,7時的選擇性為多少:

這裡可能有一個誤區,會讓我們感覺在索引字首長度為4或5的時候,就已經足夠了。那麼我們在用之前的方法驗證一下:

可以看到最常出現的字首次數要比最常出現的城市次數大很多。即使它們的選擇性比較低。找到字首索引長度後,我們就可以建立字首索引了。
mysql> ALTER TABLE city ADD KEY (city(7));
字首索引是一種能使索引更小、更快的有效辦法。它的缺點是:MySQL無法使用字首索引做ORDER BY和GROUP BY,也無法使用字首索引做覆蓋掃描。
3、多列索引
看到這裡,你可以開啟自己的資料庫表,然後看看結構,是不是為每個列建立的單獨的索引,我們公司現在就是這麼做的。

這是一個常見的錯誤。在MySQL5.0之前,下面的查詢將無法用到索引,需要全表掃描:
select id from `shops_orders` where user_id=11 and shop_id=1;
在MySQL5.0之後,引入了‘索引合併’的概念。這種演算法包括:OR條件的聯合(union),AND條件的相交(intersect),組合前兩種情況的聯合和相交。
- 首先看下OR條件的聯合(union):

會看到在EXTRA列中, 有一個Using union()。而AND條件的相交(intersect)會有一個Using intersect()。
這種索引合併策略是一種優化結果。但也間接說明了你的表上的索引建的很糟糕:
- 當伺服器對多個索引做相交操作時(通常是多個AND條件),通常意味著需要一個包含相關列的多列索引,而不是多個獨立的單獨索引。
- 當伺服器對多個索引做聯合操作時(通常是多個OR條件),通常需要消耗大量的CPU和記憶體資源在演算法的快取、排序和合並操作上。特別是其中有些索引選擇性不高,需要合併掃描返回的大量資料。
- 更重要的是,這種索引合併策略不會被優化器計算到"查詢成本"(cost)中去,優化器只關心隨機頁面的讀取。
4、選擇合適的索引列順序
既然要建立多列索引,那麼選擇合適的順序就相當重要了。對於如何選擇合適的索引順序有一個經驗法則:將選擇性最高的列放到索引最前列。
最開始,你可以按照這個法則建立多列索引,因為這可以在使用第一個索引列的時候就篩選出最少的資料量。隨著經驗的積累,你會有自己的索引列排序的經驗。
5、聚簇索引
聚簇索引並不是一種單獨的索引型別,而是一種資料儲存方式。聚簇索引總是把資料行儲存在葉子頁中,因此一個表中只能有一個聚簇索引。並不是所有的儲存引擎都支援聚簇索引,這裡我們主要討論InnoDB,在InnoDB中,聚簇索引其實就是主鍵索引。如果表中沒有定義主鍵,InnoDB會選擇一個唯一的非空索引作為主鍵。如果沒有這樣的索引,InnoDB會隱式的定義一個主鍵來作為聚簇索引。聚簇索引的優點如下:
- 可以把相關資料儲存在一起。
- 資料訪問更快。
- 使用覆蓋索引掃描的查詢可以直接使用頁節點中的主鍵值。
如果表在設計和查詢的時候能充分利用以上特點,將會極大提高效能。當然,聚簇索引也有它的缺點:
- 聚簇索引最大限度提高了I/O密集型應用的效能,但如果所有的資料都存放在記憶體中,聚簇索引就沒有優勢了。
- 插入速度嚴重依賴插入順序。這也是為什麼InnoDB一般都會設定一個自增的int列作為主鍵。
- 更新聚簇索引的代價很高,因為會強制InnoDB將每個被更新的行移到新的位置。
- 如果不安順序插入新資料時,可能會導致"頁分裂"。
- 二級索引可能會比想象的更大。因為在二級索引的頁子節點中包含了引用行的主鍵列。
- 二級索引訪問可能會需要進行回表查詢。
有人可能會有疑問。什麼是回表查詢呢?二級索引為什麼要回表查詢?答案在二級索引中儲存的“行指標”的實質。因為二級索引在頁子節點中儲存的並不是指向行的物理位置的指標,而是行的主鍵值。那麼如果此次查詢不是覆蓋查詢,就會利用二級索引頁子節點中儲存的行主鍵值再去表裡進行二次查詢。這是才會得到我們真正想要的資料,這樣就是導致使用兩次B-TREE查詢,而不是一次。這也是文章開頭所提到的,避免使用select *的另一個原因。看一下聚簇索引的資料分佈:
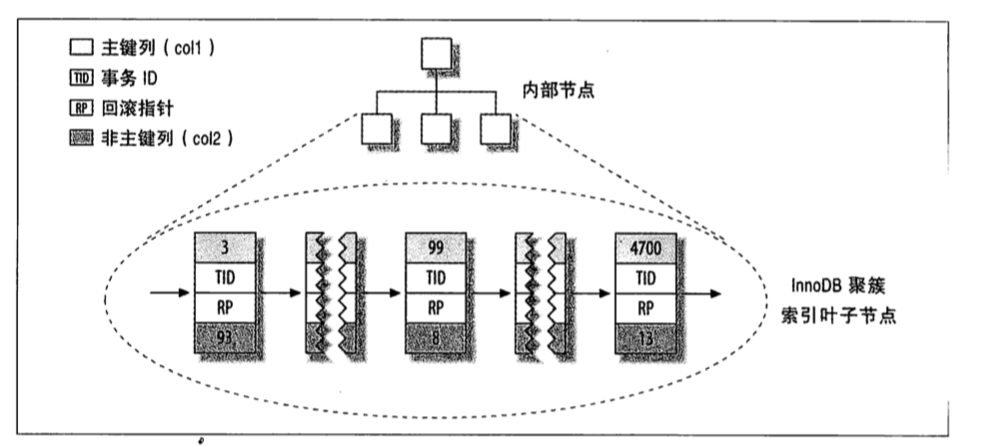
6、覆蓋索引
看到這裡,相信大家對覆蓋索引應該有一個概念了。
如果一個索引包含或覆蓋所有需要查詢的欄位值,我們就稱之為“覆蓋索引”。所以可能一個索引對於某些查詢是覆蓋索引,而對於其他的查詢則不是。其實就是一個二級索引,只不過滿足了一個特定條件。
覆蓋索引是一個非常有用的工具,可以極大的提升效能。試想一下,如果一個查詢只需要掃描索引而無需二次回表查詢,會帶來那些好處:
- 索引行通常遠小於資料行的大小,所以如果只需要索引,那麼MySQL就會極大地減少資料訪問量。
- 因為索引是按照順序儲存的,所以對於I/O密集型的範圍查詢會比隨機從磁碟讀取每一行資料的I/O要少的多。
- 由於InnoDB的聚簇索引,所以覆蓋索引對InnoDB特別有用。
當發起一個覆蓋查詢的時候,在Explain中的Extra列中可以看到“Using index”的資訊。讓我們回到select *這個問題上,沒有任何一個索引能夠覆蓋所有列。所以select * 可能會導致原本可以用到覆蓋索引的查詢而無法使用覆蓋索引。
7、使用索引掃描來做排序
ORDER BY和查詢型查詢的限制是一樣的:需要滿足索引的最左字首原則,否則,MySQL無法使用索引排序。但有一個特殊情況:就是前導列為常量。例如,有一個索引為(A,B,C),那麼這樣的SQL語句也會用索引排序。
select id from table where A=2 order by B,C;
而這種則不行
select id from table where A>2 order by B,C;
三、索引案例學習
理解索引最好的辦法就是結合例項,那麼這裡我就結合我們公司的一個訂單表來講一下。現在的索引就是在每個需要的列上建立單獨的索引。

首先company_id(企業ID)列的選擇性肯定很低,但基本上每個查詢都會用到。然後status(訂單狀態)和type(訂單型別)列的選擇性通常也都比較低,但也會在很多查詢中用到。所以這時候我們可以考慮在建立不同組合的索引時以(company_id,status,type)作為字首。
這裡肯定有很多人會有疑問?我們之前不是提到過一個經驗法則,儘可能將選擇性高的列放在多列索引的前面,那麼這裡為什麼在選擇性很低的列上建立索引,而且還把它作為索引字首列。這麼做的原因有兩點:
- 幾乎每一個查詢都會用到這三個列。甚至在可以把它設計成訂單必須按狀態查詢。
- 更重要的是,即使沒有用到這三個列,我們也可以用“訣竅”繞過它們。
這個“訣竅”就是,假如我們有一個查詢需要查詢所有狀態的訂單,那麼我們可以在WHERE條件中新增AND status IN (1,2,3,4)來讓MySQL選擇該索引。這麼用的話,需要一點,在IN()條件中,優化器需要做的組合是以指數增加的。比如我們之前提到的三個列,比如,company_id有5個值,status有4個值,type有3個值,那麼優化器就會轉化成5 x 4 x 3=60種組合。60種組合對於MySQL來說,並不是很誇張,但當這個組合數達到上千個的時候就需要特別小心了。
我們這邊最常用的是按照店鋪、客戶手機號、客戶姓名、時間段來查詢訂單。這裡面數值最少的店鋪,也有大幾十個。所以顯然不適合上面所提到的那個“訣竅”。所以我們可以建立這麼幾個索引。(company_id,status,type,shop_id,click_at)、(company_id,status,type,custom_name,click_at)、(company_id,status,type,custom_mobile,click_at)。
在建立多列索引的時候,一定要避免多個範圍條件,比如上面3個索引,如果你在click_at後面在加上任何列,是不會被索引命中的。除非你有特殊的原因,比如你需要新增一個欄位來讓某個查詢變成覆蓋查詢,否則最好不要在一個範圍列後面在加上其他列,只會浪費空間。
四、索引條件下推(ICP)
這個是題外話,MySQL在5.6中引入了這個優化--Index Condition Pushdown。MySQL官網手冊是這樣描述的:
The goal of ICP is to reduce the number of full-record reads and thereby reduce IO operations. For InnoDB clustered indexes, the complete record is already read into the InnoDB buffer. Using ICP in this case does not reduce IO.
在下粗略的翻譯了下,意思是:ICP的目的是通過減少完整記錄讀取的數量來減少IO操作。對於InnoDB的聚簇索引,完整記錄已經被讀取到InnoDB緩衝裡,在這種情況下使用ICP不能減少IO。
其實這個很好理解,我們先關閉ICP,
set optimizer_switch='index_merge_intersection=off';
在沒有ICP的時候,看下面這個SQL。
explain select * from `shops_orders` where `code` like '2018010419%';
結果為

然後我們開啟ICP,在執行上面的SQL。

我們可以看到下面的SQL用到了ICP。那麼ICP是什麼呢?
在沒有ICP的時候,WHERE條件中沒有被索引用到的列的過濾是在MySQL服務層中,而有了ICP之後,這種過濾就直接在儲存引擎層中完成了,而且是在二級索引回表查詢前就完成了過濾,這就避免了大量的資料傳輸,從而降低了IO。