
ELK學習記錄
介紹
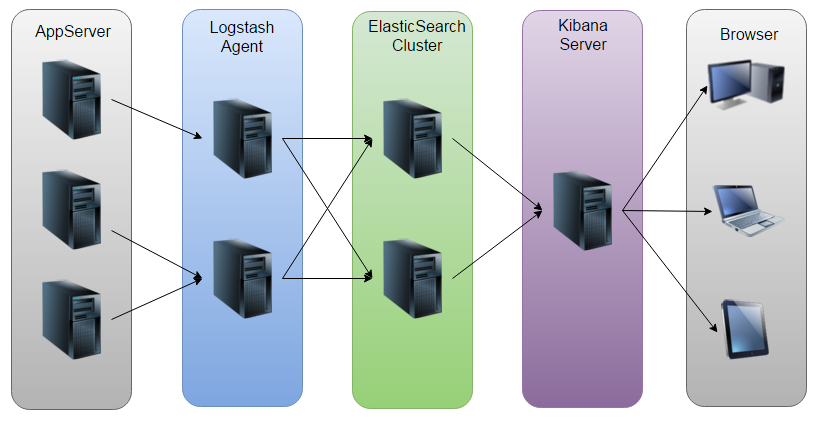
開源實時日誌分析平臺ELK能夠解決1.日誌分散;2.日誌量大,查詢麻煩。ELK由ElasticSearch、Logstash和Kiabana三個開源工具組成。ElasticSearch主要優化日誌搜尋,Logstash主要解決日誌收集,Kiabana主要是視覺化。
這三個主要關係如圖:
環境搭建:
ElasticSearch
啟動elasticsearch
遇見的一些問題以及解決辦法:

安裝外掛
(外網訪問不需要考慮。公司內網沒辦法使用npm安裝,只能搞一個bignet或者是用公司內搞的npm,參考文章)
elasticsearch版本過高的話,只能用server的形式和head通訊,需要更新下ea-head和es的配置,

可以通過紅框判斷es和es-head是否互動成功。
部署多臺機器
我是部署了3臺機器,每個機器都拷貝同一個版本的elasticsearch,然後更改配置檔案,都啟動起來就行,主要配置檔案比較麻煩。
# cluster同一個叢集是相同的 cluster.name: es_cluster #每個機器的node.name設定不同的來區分 node.name: node0 path.data: ./data0 path.logs: ./logs # 當前hostname或IP,這個不能寫0.0.0.0,單機的時候可以寫,多個機器的時候其他節點會找不到 network.host: 10.64.13.24 http.port: 8200 # 增加跨域的配置 http.cors.enabled: true http.cors.allow-origin: "*" # 是否是master,是否儲存資料,3臺機器一般要有2個master(n/2+1個) # data我是都存了,可以只有兩臺機器來存 node.master: true node.data: true # 這是其實沒搞的太明白,但是不配置會錯 discovery.zen.ping.unicast.hosts: ["10.64.13.24", "10.99.204.219", "10.100.47.192"] #一般要有(n/2+1個)個master #discovery.zen.minimum_master_nodes: 2 bootstrap.memory_lock: false bootstrap.system_call_filter: false
Logstash
下載的話上面的連結有,需要注意的幾點:
- logstash是需要安裝在日誌所在機器。
- 需要添加個配置,要搞清楚input,filter,output的概念,input是怎樣輸入的,filter是日誌過濾的一些方式,output我這裡配置的就是傳輸到elasticsearch上面。配置詳解參考文章,很多類似文章,隨便搜。
傳輸的時候是一行行傳輸的,檔案稍微一丟丟大就卡死了,解決ing------> 這是機器不穩定的問題,nohup後臺啟動就沒問題了。- 日誌合併的問題:使用logstash的Multiline外掛,參考文章。需要注意的是,我是使用的正則表示式,logstash的正則是ruby的正則,所以語法搜ruby就好了。
Kibana
自己賊傻逼的開了個9000多的埠號和5000多的埠號,用Chrome連不上,糾結了好多天,後來我浩哥告訴說,外面連基本上是8000-9000的端口才行,我就xxx...
其他的安裝之類的參考文章最開始的連結就全部都可以搞定
許可權

其他
下面記錄下其他需要考慮的優化方面的問題。
日誌的合併。因為是幾條一起過來的,但是合併的好像有點問題,最好是能同一條請求合併一條。---->參見logstash- 日誌過濾。需要看看拿debug還是什麼日誌,然後日誌取那一部分。
- 正則
- 模糊匹配改成精準匹配
一些優化方案:
問題:

這個message太長了,然後比如按照request id搜尋,結果根本沒搜尋出來的欄位(實際是有的,就是沒展示出來),而且有一些欄位是無效的,所以打算在logstash(因為是在logstash進行欄位合併以及過濾匹配的)上面做些處理,過濾一些欄位,然後欄位細化下
其他的還未通,繼續搞,不斷更新
filebeat
目前遇到的問題是,logstash能夠讀取出來日誌,但是可能會佔用機器太多資源,還有log4j2這個東西我用不明白,導致日誌格式很亂。所以考慮直接用filebeat好了。
下載之後解壓,修改filebeat.yml檔案進行配置。
同時更改下logstash的配置,這個參考文章