
非同步更新快取的邏輯
前言
高併發場景下使用快取可以有效降低併發QPS對於資料庫的壓力,但是使用快取就必須面對資料一致性的問題。
高併發處理
有效利用java多執行緒特性平行計算,充分利用CPU資源。 在序列化處理上考慮更好的工具,比如之前資料是用XML,JSON儲存,隨著訪問量的飆升,CPU和頻寬帶來了很大的壓力,後來我們自己定義了一種傳輸協議和序列化方案,一方面資料壓縮到原來的30%~40%,極大節約了寬頻,同時CPU的運算量大大降低,伺服器數量也隨之減少。
比如我們之前用Fastjson,正常情況下確實解析很快,但是一旦併發量上來後,就會越來越吃記憶體,甚至JVM很快記憶體溢位。 原因是Fastjson設計的初衷是先把整個資料裝載至記憶體,然後解析,所以執行很快,但會相當消耗記憶體。
所以Fastjson是有他適合的使用場景的,作為架構師需要對自己的場景有很好的理解,在技術選型上有很好的取捨。
同時引入NIO解決過多長連線導致的系統穩定性和開銷問題。
訊息佇列
為完成資料非同步更新到快取,可以採用訊息佇列方式(主備AMQ)來管理非同步任務。
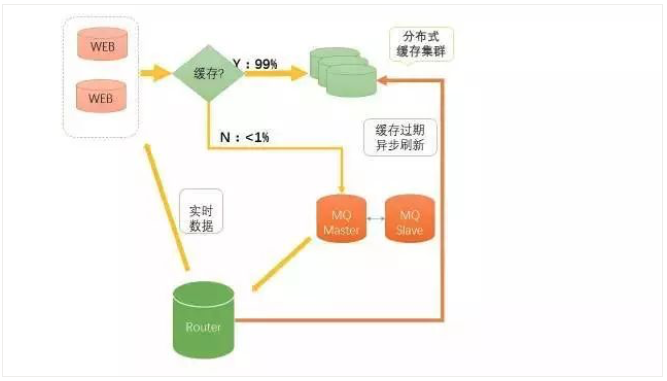 非同步更新快取的核心邏輯是,如何判斷快取過期。上圖中引入了一個Router。
舉個例子:運營會設定細化一個航班段的快取有效期,比如北京到紐約,一般來說買機票的人不多,航班資訊快取幾天沒有問題,但如果是北京到上海,可能只能最多5分鐘了。
非同步更新快取的核心邏輯是,如何判斷快取過期。上圖中引入了一個Router。
舉個例子:運營會設定細化一個航班段的快取有效期,比如北京到紐約,一般來說買機票的人不多,航班資訊快取幾天沒有問題,但如果是北京到上海,可能只能最多5分鐘了。
Router解決的複雜工作,我們叫“去偽存真”。進行一些規則設計,這個規則設計需要很靈活,也可以引入訊息佇列進行非同步化解耦,進行很好的讀寫分離。
整體系統流轉
當快取系統相關資料過期後,前臺搜尋告知MQ有實時搜尋任務,MQ統一把非同步任務交給Router,這是Router不會直接請求下游資料,而是找Node池。
Node池會動態分配一個Node節點給Router,最後Router查詢Node節點對映的資料,最後非同步更新到快取資料。