
HBase入門--HBase概念及表格設計
HBase概念及表格設計
1. 概述(扯淡~)
HBase是一幫傢伙看了Google釋出的一片名為“BigTable”的論文以後,猶如醍醐灌頂,進而“山寨”出來的一套系統。
由此可見:
1. 幾乎所有的HBase中的理念,都可以從BigTable論文中得到解釋。原文是英語的,而且還有不少數學概念,看了有點兒懵,建議網上找找學習筆記看看,差不多也就可以入門了。
2. Google確實牛X。
3. 老外也愛山寨~
第一次看HBase, 可能看到以下描述會懵:“基於列儲存”,“稀疏MAP”,“RowKey”,“ColumnFamily”。
其實沒那麼高深,我們需要分兩步來理解HBase, 就能夠理解為什麼HBase能夠“快速地”“分散式地”處理“大量資料”了。
1.記憶體結構
2.檔案儲存結構
2. 名詞概念以及記憶體結構
假設我們有一張表(其中只有一條資料):
| RowKey |
ColumnFamily : CF1 |
ColumnFamily : CF2 |
TimeStamp |
||
| Column: C11 |
Column: C12 |
Column: C21 |
Column: C22 |
||
| “com.google” |
“C11 good” |
“C12 good” |
“C12 bad” |
“C12 bad” |
T1 |
1) RowKey: 行鍵,可理解成MySQL中的主鍵列。
2) Column: 列,可理解成MySQL列。
3) ColumnFamily: 列族, HBase引入的概念:
-
- 將多個列聚合成一個列族。
- 可以理解成MySQL的垂直分割槽(將一張寬表,切分成幾張不那麼寬的表)。
- 此機制引入的原因,是因為HBase相信,查詢可能並不需要將一整行的所有列資料全部返回。(就像我們往往在寫SQL時不太會寫select all一樣)
- 對應到檔案儲存結構(不同的ColumnFamily會寫入不同的檔案)。
4) TimeStamp:在每次跟新資料時,用以標識一行資料的不同版本(事實上,TimeStamp是與列繫結的。)
那我們為何會得到HBase的讀寫高效能呢?其實所有資料庫操作如何得到高效能,答案几乎都是一致的,就是做索引。
HBase的設計拋棄了傳統RDBMS的行式資料模型,把索引和資料模型原生的整合在了一起。
以上圖的表為例,表資料在HBase內部用Map實現,我們把它寫成JSon的Object表述,即:
{ "com.google": { CF1: { C11:{ T1: good } C12:{ T1: good } CF2: { C21:{ T1: bad } C22:{ T1: bad } } } }
由於Map本身可以通過B+樹來實現,所以隨機訪問的速度大大加快(我們需要想象一下,表中有很多行的情況)。
現在我們在原來的表上修改一下(將Column: C22改為”good”):
| RowKey |
ColumnFamily : CF1 |
ColumnFamily : CF2 |
TimeStamp |
||
| Column: C11 |
Column: C12 |
Column: C21 |
Column: C22 |
||
| “com.google” |
“C11 good” |
“C12 good” |
“C12 bad” |
“C12 bad” |
T1 |
| “com.google” |
“C11 good” |
“C12 good” |
“C12 bad” |
“C12 good” |
T2 |
於是MAP變為了:
{ "com.google": { CF1: { C11:{ T1: good } C12:{ T1: good } CF2: { C21:{ T1: bad } C22:{ T1: bad T2:good } } } }

事實上,我們只需要在C22的object再加一個屬性即可。如果我們把這個MAP翻譯成表形狀,也可以表示為:
| RowKey |
ColumnFamily : CF1 |
ColumnFamily : CF2 |
TimeStamp |
||
| Column: C11 |
Column: C12 |
Column: C21 |
Column: C22 |
||
| “com.google” |
“C11 good” |
“C12 good” |
“C12 bad” |
“C12 bad” |
T1 |
|
|
|
|
|
“C12 good” |
T2 |
我們發現,這個表裡很多列是沒有value的。想象一下,如果再加入一行RowKey不同的資料,其中Column:C11內容為空,就可以在Json中省略該屬性了。
好了,扯了這麼多,就是為了說明HBase是“稀疏的高階MAP”。
為了查詢效率,HBase內部對RowKey做了排序,以保證類似的或者相同的RowKey都集中在一起,於是HBase就變成了一張“稀疏的,有序的,高階的MAP”。有沒有覺得這樣的表述很高冷? :)
3. 檔案儲存結構與程序模型
如上所述,HBase是一張“稀疏的,有序的,高階的MAP”。
通常來說,MAP可以用B+樹來實現。B+樹對查詢效能而言表現良好,但是對插入資料有些力不從心,尤其對於插入的資料需要持久化到磁碟的情況而言。
我們對RowKey做了排序,為了保證查詢效率,我們希望將連續RowKey的數值儲存在連續的磁軌上,以避免大量的磁碟隨機尋道。所以在插入資料時,對於B+樹而言,就面臨著大量的檔案搬移工作。
HBase使用了LSM樹實現了MAP,簡單說來,就是將插入/修改操作快取在記憶體中,當記憶體中積累足夠的資料後,再以塊的形式刷入到磁碟上。
HBase的程序模型:
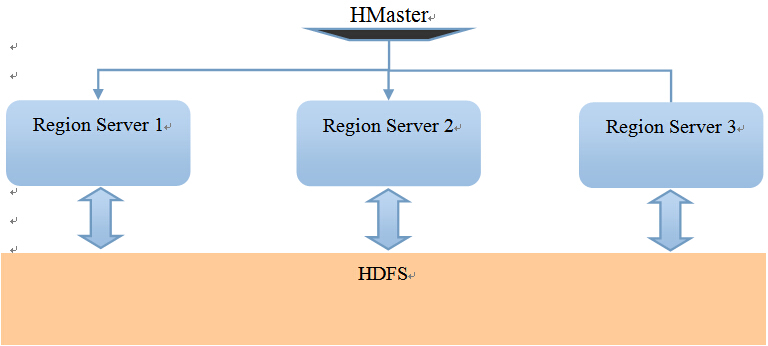
Region: 基於RowKey的分割槽,可理解成MySQL的水平切分。
每個Region Server就是Hadoop叢集中一臺機器上的一個程序。
比如我們的有1-300號的RowKey, 那麼1-100號RowKey的行被分配到Region Server 1上,同樣,101-200號分配到Region Server 2上, 201-300號分配到Region Server 3上。
在記憶體模型中,我們說RowKey保證了相鄰RowKey的記錄被連續地寫入了磁碟。在這裡,我們發現,RowKey決定了行操作(增,刪,改,查)會被交與哪臺Region Server操作。
讓我們假設一下,如果我們的RowKey以記錄的TimeStamp起始,從記憶體模型上說,這很合理,因為我們可能面臨大量的使用者流水記錄查詢,查詢的條件會設定一個時間片段,我們希望一次性從磁碟中讀取這些流水記錄,從而避免頻繁的磁碟尋道操作。
但是再另一方面,使用者的流水記錄查詢會很頻繁的出現“截至到至今”的查詢條件,依照我們上面的程序模型,Region Server 3一定會被分配到(因為最近的記錄排在最後),這樣就可能造成Region Server 3的“過熱”,而Region Server 1“過冷”的情況。
檔案儲存模型:
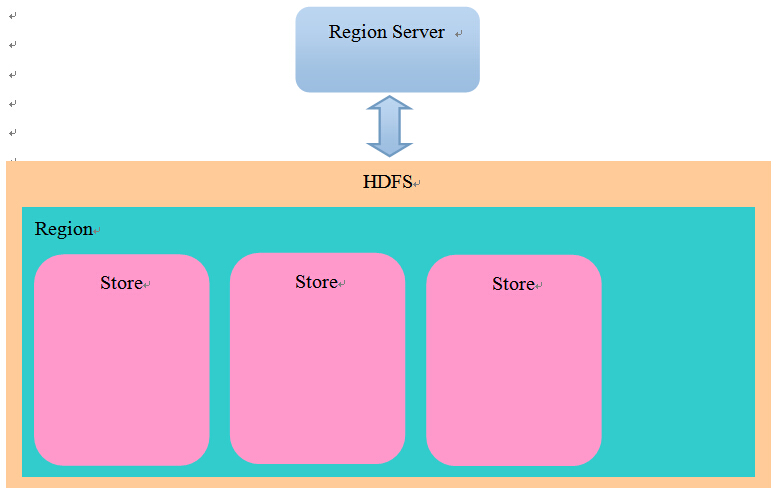
在HDFS中,每張表對應一個目錄,在表目錄下,每個Region對應一個目錄,在Region目錄下,每個Store對應一個目錄(一個Store對應一個ColumFamily)。結構如下:
HBase
|
---Table
|
---XXXX(Region的hash)
| |
| ----ColumnFamily
| |
| ---檔案
|
---YYYYY(另一個Region的hash)
我們的新發現是,不同的ColumnFamily對應不同的Store, 並且被寫入了不同的目錄, 這意味著:
1. 通過將一張表分解成了不同的ColumnFamily,HBase可以從磁碟一次讀取更少的內容(IO操作往往是計算機系統中最慢的一環)。
2. 我們不應該將需要一次查詢出的列,分解在不同的ColumnFamily中,否則以為著HBase不得不讀取兩個檔案來滿足查詢要求。
另外,一個ColumnFamily中的每一列是連續儲存的。即如果一個ColumnFamily中存在C1,C2兩列,一段具有100行記錄的儲存格式是:
C1(1),C2(1),C1(2),C2(2),C1(3),C2(3).............C1(100),C2(100)
與其說HBase是基於列的資料庫,更不如說HBase是基於“列族”的資料庫。
4 理解:
基於以上的模型,大致的理解是:
1. RowKey決定了行操作任務進入RegionServer的數量,我們應該儘量的讓一次操作呼叫更多的Region Server,已達到分散式的目的。
2. RowKey決定了查詢讀取連續磁碟塊的數量,最理想的情況是一次查詢,在每個Region Server上,只讀取一個磁碟塊。
3. ColumnFamily決定了一次查詢需要讀取的檔案數(不同的檔案不僅意味著分散的磁碟塊,還意味著多次的檔案開啟關閉操作)。我們應儘量將希望查詢的結果集合併到一個ColumnFamily中。同時儘量去除該ColumnFamily中不需要的列。
4. HBase官方建議儘量的減少ColumnFamily的數量。
再瞎總結一下:
1. RowKey由查詢條件決定。
2. ColumnFamily由查詢結果決定。
感謝感謝,感謝你看完了!以上純屬個人理解,歡迎拍磚。 :)