
簡單NLP分析套路(2)----分詞,詞頻,命名實體識別與關鍵詞抽取
文章大綱
google 近期釋出了顛覆性的NLP模型–BERT ,大家有空可以瞭解一下,
這是張俊林博士寫的科普文章:
https://mp.weixin.qq.com/s/EPEsVzbkOdz9GovrAM-p7g
上一篇文章講講解了,https://blog.csdn.net/wangyaninglm/article/details/83479837
如何使用python 爬取三種類型的網站語料庫,我就使用其中一種針對自己的部落格進行一些簡單的分析工作。
程式碼連結:
https://github.com/wynshiter/NLP_DEMO
主要包含以下一些內容:
- 分詞
- 詞頻
- 命名實體識別
- 關鍵詞抽取
中文分詞技術
之前寫過兩篇分詞相關的文章,裡面簡要介紹了中文分詞技術,我認為漢語分詞技術在深度學習之前完全是一種獨立的技術手段。主要使用規則,統計或者混合的方式進行分詞。
在文章,深度學習與中文短文字分析總結與梳理第三小節中
中我都曾簡單介紹過中文分詞技術。那麼文章中提到的各類分詞技術到底實戰效果如何,我們就來看看
評測參考
https://blog.csdn.net/riario/article/details/78259877
雲服務
哈工大語言云 ltp
準確率:
綜合準確率較高,windows下安裝時候坑比較多,linux 估計會好一些
文件:
https://pyltp.readthedocs.io/zh_CN/latest/api.html
github:
https://github.com/HIT-SCIR/ltp
分詞例子:nlp_demo
LTP_DATA_DIR = r'..\ltp_data_v3.4.0' # ltp模型目錄的路徑
cws_model_path = os. 安裝報錯參考
https://blog.csdn.net/weixin_40899194/article/details/79702468
基於深度學習方法的中文分詞
資訊檢索與關鍵詞提取
這個部分我們來介紹一些能夠衡量文章中詞彙重要性 的指標
早先我在做一個簡單POC 的時候現學現賣了一些,那時候居然 不知道jieba 庫直接提供了計算TF-IDF TEXTRANK的介面,還是找著論文自己寫了一段程式實現的。
之前文章:《短文字分析----基於python的TF-IDF特徵詞標籤自動化提取》沒有寫完,現在想針對NLP 的通用技術方法做一個階段性總結:
文字被分詞之後,會有如下兩個問題:
其一,並不是所有的詞彙都對錶達文章意思有意義;
其二,一個語料庫的詞量是非常大的,傳統的文字挖掘方法又是基於向量空間模型表示的,所以這會造成資料過於稀疏。
為了解決這兩個問題一般會進行停用詞過濾和關鍵字提取,而後者現有基於頻率的TF-IDF計算方法和基於圖迭代的TextRank的計算方法兩種。下面看看這兩種方法是怎麼工作的
tf-idf
資訊檢索概述
資訊檢索是當前應用十分廣泛的一種技術,論文檢索、搜尋引擎都屬於資訊檢索的範疇。通常,人們把資訊檢索問題抽象為:在文件集合D上,對於由關鍵詞w[1] … w[k]組成的查詢串q,返回一個按查詢q和文件d匹配度 relevance (q, d)排序的相關文件列表D。
對於這一基問題,先後出現了布林模型、向量模型等各種經典的資訊檢索模型,它們從不同的角度提出了自己的一套解決方案。
布林模型以集合的布林運算為基礎,查詢效率高,但模型過於簡單,無法有效地對不同文件進行排序,查詢效果不佳。
向量模型把文件和查詢串都視為詞所構成的多維向量,而文件與查詢的相關性即對應於向量間的夾角。不過,由於通常詞的數量巨大,向量維度非常高,而大量的維度都是0,計算向量夾角的效果並不好。另外,龐大的計算量也使得向量模型幾乎不具有在網際網路搜尋引擎這樣海量資料集上實施的可行性。
TF-IDF原理概述
如何衡量一個特徵詞在文字中的代表性呢?以往就是通過詞出現的頻率,簡單統計一下,從高到低,結果發現了一堆的地得,和英文的介詞in of with等等,於是TF-IDF應運而生。
TF-IDF不但考慮了一個詞出現的頻率TF,也考慮了這個詞在其他文件中不出現的逆頻率IDF,很好的表現出了特徵詞的區分度,是資訊檢索領域中廣泛使用的一種檢索方法。
Tf-idf演算法公式以及說明:
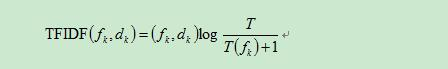
具體實現如下所示,公式分成兩項,詞頻*逆詞頻,逆詞頻取log值。

TEXTRANK
TextRank 演算法是一種用於文字的基於圖的排序演算法。其基本思想來源於谷歌的 PageRank演算法, 通過把文字分割成若干組成單元(單詞、句子)並建立圖模型, 利用投票機制對文字中的重要成分進行排序, 僅利用單篇文件本身的資訊即可實現關鍵詞提取、文摘。和 LDA、HMM 等模型不同, TextRank不需要事先對多篇文件進行學習訓練, 因其簡潔有效而得到廣泛應用。
TextRank 一般模型可以表示為一個有向有權圖 G =(V, E), 由點集合 V和邊集合 E 組成, E 是V ×V的子集。圖中任兩點 Vi , Vj 之間邊的權重為 wji , 對於一個給定的點 Vi, In(Vi) 為 指 向 該 點 的 點 集 合 , Out(Vi) 為點 Vi 指向的點集合。點 Vi 的得分定義如下:
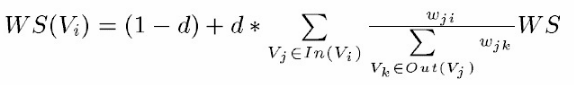
textRank認為一個節點如果入度多且權重大,那麼這個節點越重要。
其中, d 為阻尼係數, 取值範圍為 0 到 1, 代表從圖中某一特定點指向其他任意點的概率, 一般取值為 0.85。使用TextRank 演算法計算圖中各點的得分時, 需要給圖中的點指定任意的初值, 並遞迴計算直到收斂, 即圖中任意一點的誤差率小於給定的極限值時就可以達到收斂, 一般該極限值取 0.0001
word2vector
體驗一下百度的word2vector,在文章:
https://blog.csdn.net/wangyaninglm/article/details/81232724
我有說過百度目前為止提供的NLP相關服務業界領先,我們來體驗一下
# -*- coding:utf-8 -*-
"""@author:[email protected]:[email protected]:2018/6/1323:01"""
from aip import AipNlp
""" 你的 APPID AK SK """
APP_ID = ''
API_KEY = ''
SECRET_KEY = ''
client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
word1 = "張飛"
dict_zhangfei = {}
word2 = "關羽"
dict_liubei = {}
""" 呼叫詞向量表示 """
dict_zhangfei = client.wordEmbedding(word1)
print(dict_zhangfei)
dict_liubei = client.wordEmbedding(word2)
print(dict_liubei)
vector_zhangfei = dict_zhangfei['vec']
vector_liubei = dict_liubei['vec']
import numpy as np
import math
def Cosine(vec1, vec2):
npvec1, npvec2 = np.array(vec1), np.array(vec2)
return npvec1.dot(npvec2)/(math.sqrt((npvec1**2).sum()) * math.sqrt((npvec2**2).sum()))
# Cosine,餘弦夾角
print(""" 呼叫詞義相似度: """,client.wordSimEmbedding(word1, word2))
print("餘弦相似度:",Cosine(vector_zhangfei, vector_liubei))
百度詞向量其實返回的是一個1024維的詞向量,而且相似度的衡量用的就是餘弦相似度可以說是非常接地氣了
結果:

未完待續
NLP系列文章:
- 深度學習與中文短文字分析總結與梳理
- 錯誤使用tf-idf的例項分享
- 知識圖譜技術分享會----有關知識圖譜構建的部分關鍵技術簡介及思考
- 基於分散式的短文字命題實體識別之----人名識別(python實現)
- 簡單NLP分析套路(1)----語料庫積累之3種簡單爬蟲應對大部分網站
- 簡單NLP分析套路(2)----分詞,詞頻,命名實體識別與關鍵詞抽取
- 簡單NLP分析套路(3)---- 視覺化展現與語料收集整理