
Spark SQL簡介及以程式設計方式實現SQL查詢
阿新 • • 發佈:2018-12-12
1.什麼是SparkSQL?
2.SparkSQL的特點:
我們已經學習了Hive,它是將Hive SQL轉換成MapReduce然後提交到叢集上執行,大大簡化了編寫MapReduce的程式的複雜性,由於MapReduce這種計算模型執行效率比較慢。所有Spark SQL的應運而生,它是將Spark SQL轉換成RDD,然後提交到叢集執行,執行效率非常快!


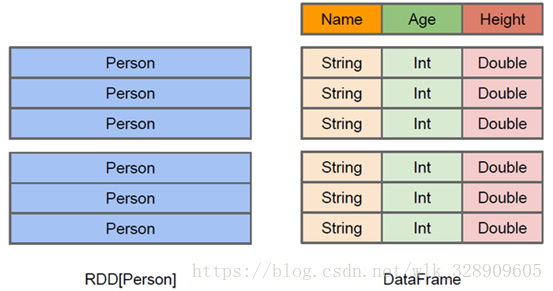
3.DataFrame介紹
與RDD類似,DataFrame也是一個分散式資料容器。然而DataFrame更像傳統資料庫的二維表格,除了資料以外,還記錄資料的結構資訊,即schema。同時,與Hive類似,DataFrame也支援巢狀資料型別(struct、array和map)。從API易用性的角度上 看,DataFrame API提供的是一套高層的關係操作,比函式式的RDD API要更加友好,門檻更低。由於與R和Pandas的DataFrame類似,Spark DataFrame很好地繼承了傳統單機資料分析的開發體驗。
4.以程式設計方式實現SQL查詢
SparkSQL很多API和RDD的類似。 Spark 1.x和Spark 2.x在企業中都在使用,所以都得掌握。 首先得有SparkSQL的環境,在pom.xml中假如以下內容:
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> //都得和自己的spark環境一一對應 <version>${spark.version}</version> </dependency>
Spark 1.x實現:
package day04 import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame, SQLContext} import org.apache.spark.{SparkConf, SparkContext} /** * @author WangLeiKai * 2018/9/28 15:38 */ case class User(id:Int,name : String,age:Int,fv:Int) object SQLDemo1 { def main(args: Array[String])= { //程式的入口 val conf = new SparkConf().setAppName("SQLDemo1").setMaster("local[*]") val sc = new SparkContext(conf) //包裝SparkContext val sqlContext = new SQLContext(sc) val lines = sc.textFile("d://data//person.txt") val boyRDD: RDD[User] = lines.map(tp => { val fields = tp.split(",") val id = fields(0).toInt val name = fields(1) val age = fields(2).toInt val fv = fields(3).toInt User(id, name, age, fv) }) //匯入sqlContext的隱式轉換 import sqlContext.implicits._ //將RDD轉換成DataFrame val f: DataFrame = boyRDD.toDF //註冊臨時表 f.registerTempTable("t_boy") //執行SQL語句 val result = sqlContext.sql("select id,name,age,fv from t_boy order by fv desc,age asc") //呼叫action 因為sql類似於transformation 是lazy的 result.show() sc.stop() } }
Spark 2.x實現
package day04
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, SQLContext, SparkSession}
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author WangLeiKai
* 2018/9/28 15:38
*/
case class User(id:Int,name : String,age:Int,fv:Int)
object SQLDemo4 {
def main(args: Array[String])= {
//建立SparkSession 如果有Spark Context 則呼叫,如果沒有則建立
val spark = SparkSession
.builder()
.appName("SQLDemo4")
.master("local[*]")
.getOrCreate()
val lines = spark.read.textFile("d://data//person.txt")
//注意:返回值是DataSet型別
val dst: Dataset[User] = lines.map(tp => {
val fields = tp.split(",")
val id = fields(0).toInt
val name = fields(1)
val age = fields(2).toInt
val fv = fields(3).toInt
User(id, name, age, fv)
})
//匯入spark的隱式轉換
import spark.implicits._
//建立臨時檢視
dst.createTempView("t_boy")
val result = spark.sql("select id,name,age,fv from t_boy order by fv desc,age asc")
result.show()
spark.stop()
}
}