
迴環檢測詳解
在視覺SLAM問題中,位姿的估計往往是一個遞推的過程,即由上一幀位姿解算當前幀位姿,因此其中的誤差便這樣一幀一幀的傳遞下去,也就是我們所說的累計誤差。
如下圖所示,我們的位姿約束都是與上一幀建立的,第五幀的位姿誤差中便已經積累了前面四個約束中的誤差。
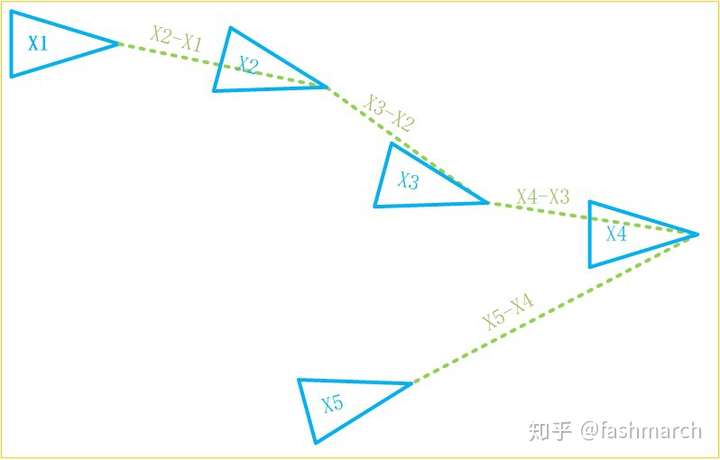
但此時,如果我們發現第五幀位姿不一定要由第四幀推出來,還可以由第二幀推算出來,那顯然這樣計算誤差更小呀,因為只有兩個約束的誤差了嘛。像這樣與之前的某一幀建立位姿約束關係就叫做迴環。迴環通過減少了約束數,起到了減小累計誤差的作用。
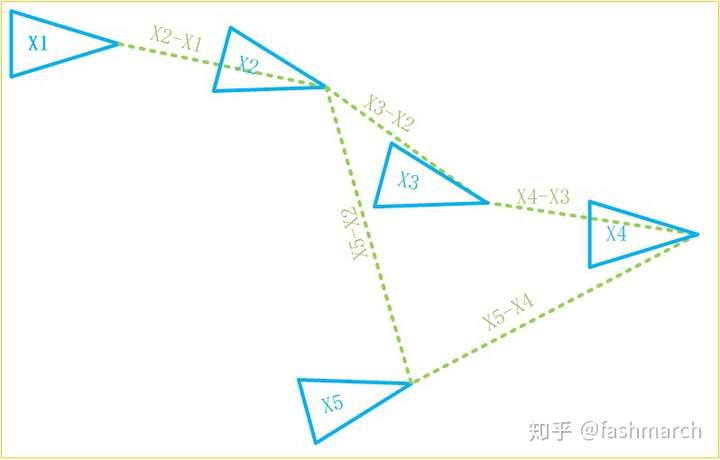
那現在又有新的問題了,我們怎麼知道可以由第二幀推算第五幀位姿呢?就像下圖,可能第一幀、第三幀也可以呀。確實,我們之所以用前一幀遞推下一幀位姿,因為這兩幀足夠近,肯定可以建立兩幀的約束,但是距離較遠的兩幀就不一定可以建立這樣的約束關係了。找出可以建立這種位姿約束的歷史幀,就是迴環檢測
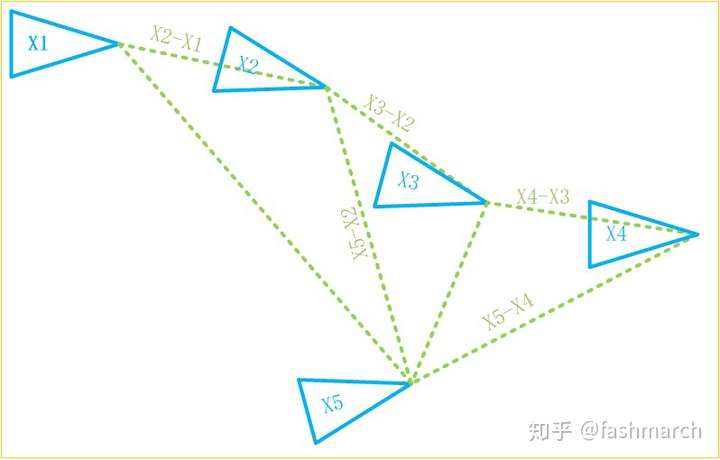
那我們現在的重點就是迴環檢測了。其實我們完全可以把以前的所有幀都拿過來和當前幀做匹配,匹配足夠好的就是迴環嘛,但問題是計算量太大了,兩幀匹配本來就慢,這樣做的話還沒有比較好的初值,需要匹配的數目又如此巨大,CPU和我們都會瘋的。
但其實,任意兩幀是否構成迴環可以由更簡單的方法做一個初步的篩選,就像一幀中有一個房子,另一幀中是一棵樹,那這兩幀明顯關係不大嘛。通過這種方式,我們便可以對迴環做出初步篩選。而這裡說的房子、樹就是詞袋模型中的單詞。也就是描述子的進一步抽象集合。
詞袋模型
單詞:差距較小的描述子的集合
字典:所有的單詞
因此每一幀都可以用單詞來描述,也就是這一幀中有哪些單詞,這裡只關心了有沒有,而不必關心具體在哪裡。只有兩幀中單詞種類相近才可能構成迴環。
因此,現在利用詞袋模型我們將回環檢測大致分為了以下三個步驟:
- 構建字典(所有單詞的集合)
- 確定一幀中具有哪些單詞,用向量表示 (1表示具有該單詞,0表示沒有)
- 比較兩幀描述向量的差異
字典結構
字典由單片語成,而單詞來自於描述子。並不是說一個描述子就是一個單詞,而是一個單詞表示了一組多個描述子,同組內的描述子差異較小。例如,描述子由256位組成,則描述子的種類便有 種,這個數相當大了,我們確定單詞,構建字典的過程就類似於將這
種描述子進行分類(聚類)的過程,我們可以指定具體分成多少類。那就很像我們現實中的字典了,有厚有薄,也就是看我們分類的多少了。
那現在字典的構建也就是一個描述子聚類的過程。聚類演算法也有很多了,這裡採用了K-means演算法,其過程也很簡單:

摘自《視覺SLAM14講》
也可以用下圖表示:
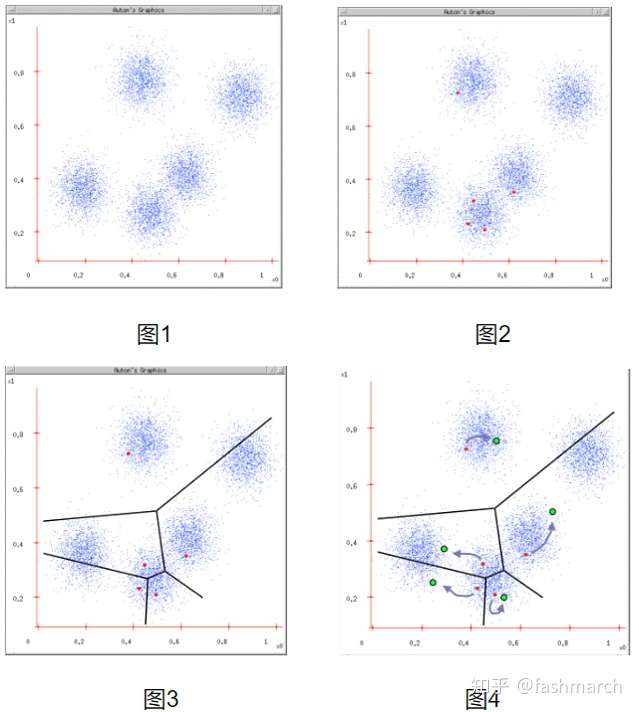
摘自https://www.cnblogs.com/ybjourney/p/4714870.html
現在通過聚類我們獲得了字典,但這裡又有一個問題。回想我們平時查字典的過程,不可能直接開啟一個一個去找吧,我們會利用目錄,首字母等方法方便我們查詢。這裡也一樣,一個個去查詢速度太慢了,因此我們將字典構建成一個K叉樹的結構來加速查詢。如下圖所示:
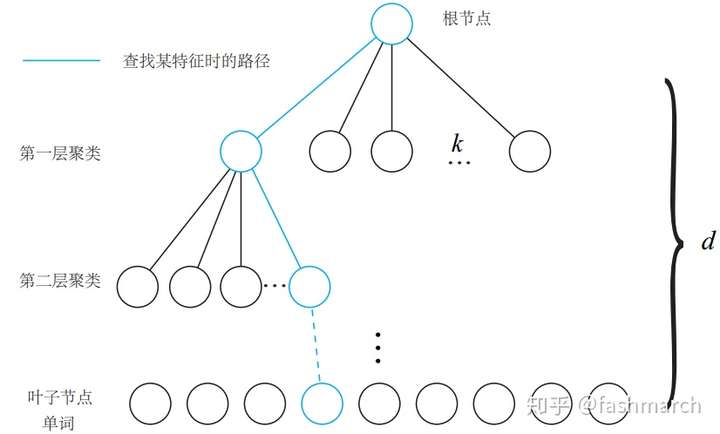
摘自《視覺SLAM14講》
我們在每一層中都用K-means演算法進行了聚類,分成了k個類,共有這樣的d層(不包括根節點)因此在查詢過程中,我們逐層向下,最終找到的葉節點也就是最終的單詞。
還可以用下圖理解:
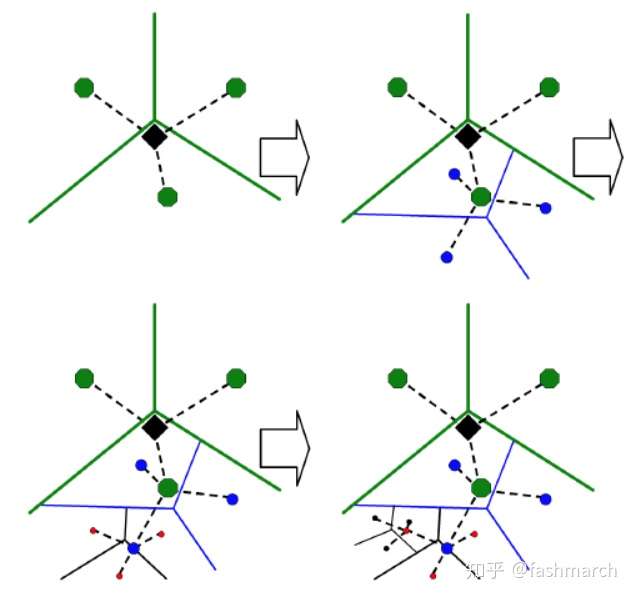
摘自[2]
相似度計算
現在我們有了字典,但還有一點需要注意。我們利用單詞表示影象,目的是發現迴環,也就是兩幀影象具有較高的相似性。那其實不同的單詞對這一目的的貢獻性是不同的。例如,我這篇文章中有很多“我們”這個詞,但這個詞並不能告訴我們太多資訊。而有些單詞例如“迴環”、“K-means”就比較具有代表性,能大概告訴我們這句話講了什麼。因此不同的單詞應該具有不同的權重。
我們用兩個量來描述這種權重:
- IDF(Inverse Document Frequency):描述單詞在字典中出現的頻率(構建字典時),越低越具有代表性
為所有描述子數,
為該單詞出現次數。
的作用大概是降低量級,畢竟
很大。
- TF(Term Frequency):單詞在單幀影象中出現的頻率,越高越具有代表性
為一幀影象中所有單詞數,
為一幀影象中該單詞出現次數。
因此將一幀影象轉化為單詞表示時,我們要計算其單詞的權重:
因此一幀影象 由單詞
、及對應的權重
表示:
同時,這裡我們要將一幀影象中的所有的權重歸一化:
我們在計算兩幀影象的差異時,就比較對應的權重即可。
計算q和d兩幀的差異(p表示範數,常取一範數)

第二個等號進行了一個分類:只在q中有的單詞、只在d中有的單詞、在q、d中都有的單詞。
第四個等號:因為進行了歸一化,前兩項都等於1
而兩幀相似度的評分定義如下(越大表示越相似):

當評分s足夠大時即可判斷兩幀可能為迴環。
迴環處理
在這裡簡單說一下,迴環出現後的處理,看得不多,如有錯誤還請指正。
當然迴環的判斷也並沒有這麼簡單,含有很多的篩選環節,畢竟錯誤的迴環將帶來巨大災難,寧可不要。例如某一位姿附近連續多次(ORB-SLAM中為3次)與歷史中某一位姿附近出現迴環才判斷為迴環;迴環候選幀仍然要匹配,匹配點足夠才為迴環。
在判斷出現迴環後,兩幀計算Sim3變換(因為有尺度漂移),也就是從歷史幀直接推算當前位姿。
當我們用第m幀推算了迴環幀n的位姿時,使得n的位姿漂移誤差較小,但其實同時可以用第n幀來計算n-1幀的位姿,使n-1幀的位姿漂移誤差也減小。因此,這裡還要有一個位姿傳播。
另外我們可以優化所有的位姿,也就是進行一個位姿圖優化(由位姿變換構建位姿約束)。
最後,我們還可以進行一起全域性所有變數的BA優化。
總結
總結來說,詞袋模型通過描述一幀影象中有哪些單詞,來加速尋找可能閉環幀的過程。
另外我們也可以利用單詞加速特徵點的匹配,例如幀A中的特徵點a屬於單詞 ,那在幀B中尋找匹配時,也要去找屬於單詞
的特徵點。
其實感覺詞袋模型更近一步就是語義了,也就是將單詞賦予真實的語義資訊,同樣可以起到閉環幀篩選,兩幀特徵點輔助匹配的作用。
程式碼
最後簡單看一下DBoW3中的程式碼
其中比較重要的大概就是以下幾個函式:

Vocabulary()
建構函式,可以從檔案中讀取字典,由影象序列生成字典、複製字典等
其預設的樹狀結構為分支數k=10,深度L=5(不包括根節點);
權重為TF_IDF;
評分型別為L1範數
create()
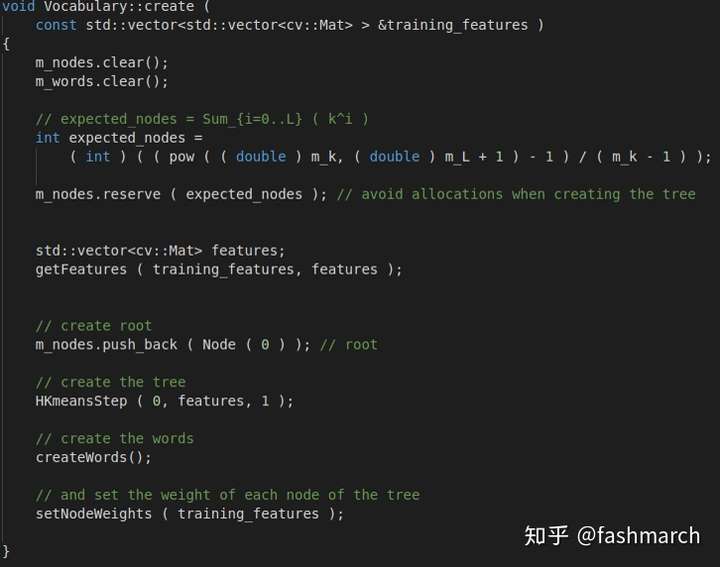
其主要步驟為:構建樹、構建單詞、計算權重(IDF)
構建樹:
主要就是一個k_means過程,不過每層都要聚類一次,所以有一個遞迴。
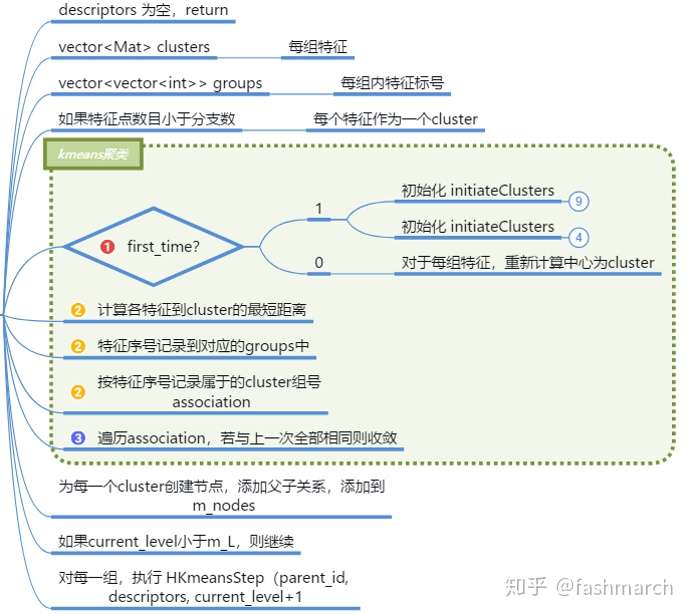
構建單詞
尋找葉節點,新增為單詞
計算權重
每個字典的IDF是不變的,所以在這裡計算IDF部分的權重

transform()
該函式將一幀影象轉換為單詞表示
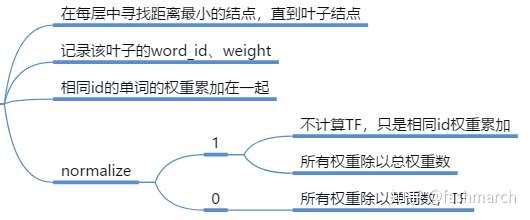
當然這裡預設是要normalize的
我們再來看一下權重計算公式
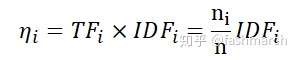
normalize之前我們相當於計算的是
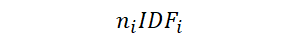
我們將它歸一化,而沒必要計算準確的TF,但也相當於綜合考慮了TF和IDF。
score()
計算兩幀相似度的評分
尋找具有相同單詞的權重按公式計算即可。
參考文獻:
[1] 高翔 《視覺SLAM十四講》
[2] D. Nister and H. Stewenius, “Scalable recognition with a vocabulary tree,”in 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), vol. 2, pp. 2161–2168, IEEE, 2006.