
用java搞資料庫
目的
- 設計一個簡化,高效的KV儲存引擎。
- 要求提供write,read,range搜尋介面。
要求
- 併發寫入資料效能。
- 任意執行kill -9來模擬程序意外退出而資料不丟失。
IO
- key固定為8位元組,可以用long表示。
- value為4kb,4kb整數落盤是非常磁碟IO友好的。
- 4kb可以在記憶體中做索引,可以使用int而不是long來記錄資料偏移,記憶體佔用會減少一半。
kill -9 資料不丟失
光使用記憶體做儲存很難滿足這一點。但是沒有要求斷電不丟失,也就是說:可以使用pageCache來做寫入快取。 所以想到使用pageCache來充當資料和索引的寫入緩衝(兩者策略不同)。 方案具體可以參考ES的pageCache方案。
隨機讀寫
按照隨機寫,隨機讀,順序讀進行實驗。 隨機寫階段不需要在記憶體維護索引,可以直接落盤。 隨機讀和順序讀,磁碟均存在資料,恢復索引可以採用多執行緒併發恢復。
pageCache處理
由於採用了pageCache,採用指令碼方式清空pageCache會比較耗時。 所以不能無節制的使用pageCache,所以準備引入Direct IO。
檔案IO
由於key可以均勻分佈,採用資料分割槽方式,可以大大減少順序讀寫的鎖衝突,key分佈均勻可以按照key搞n位來做hash,可以確保key兩個分割槽之間整體有序,於是可以嘗試將資料分成1024,2048個分割槽。
架構設計
隨機寫入key時,可以根據key進行hash將隨機寫轉換成對應分割槽的檔案順序寫。

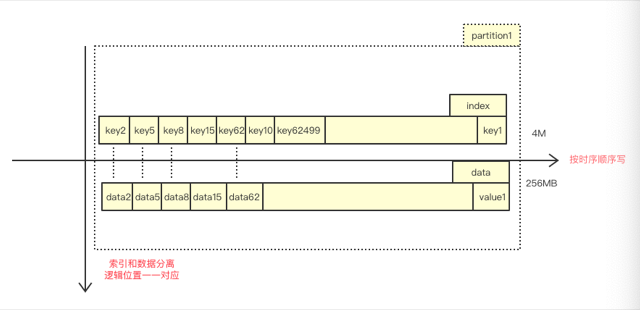
記憶體維護有序的 key[1024][625000] 陣列和 offset[1024][625000] 陣列。
利用資料分佈均勻特性,將全域性資料hash為1024分割槽,每個分割槽存放兩類檔案:索引檔案和資料檔案(對kafka熟悉的同學,是不是很親切)。
在隨機寫入階段,根據key獲得該資料對應分割槽位置,按照時序,順序追加到檔案尾部,將全域性隨機轉換為區域性順序。
利用索引和資料一一對應特性,不需要將資料的邏輯偏移落盤,在恢復階段可以按照恢復key的測序,反推value的邏輯偏移量。
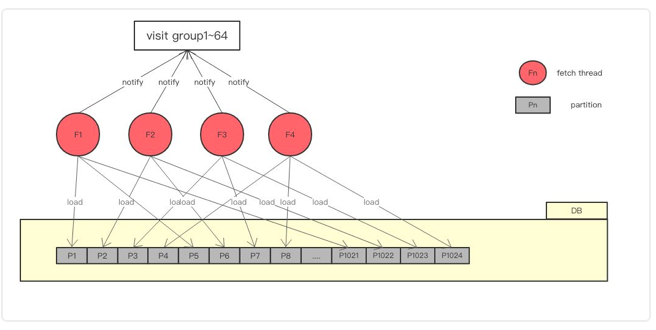
由於做了分割槽,在range查詢階段,partition(N)中任何一個數據一定大於partition(N-1)中任何一個數據,於是我們可以大塊的讀,將一個partition整體讀進記憶體,給64個執行緒消費。
讀盤執行緒負責按分割槽讀盤進入記憶體,64個消費執行緒消費記憶體,按照key順序訪問記憶體,進行回撥。
優化
使用pageCache實現寫入緩衝區
磁碟IO型別的系統,第一步是測量磁碟IOPS及多少個執行緒一次讀寫多大的快取能夠打滿IO,在固定64執行緒寫入前提下,16kb,64kb均可達到理想IOPS,所以可以為每個分割槽分配一個寫入快取,湊齊4個value落盤。
由於要求kill -9不丟失資料,不能簡單的在記憶體中分配一個ByteBuffer.allocate(4096*4);,可以考慮mmap記憶體對映一片寫入緩衝,湊齊4個刷盤,這樣kill -9之後,pageCache不會丟失。
索引檔案落盤比較簡單,key固定為8b,所以mmap可以發揮寫小資料的優勢,將pageCache利用起來,mmap相比filechannel寫索引快3s左右。
隨機寫入後不會立即隨機讀,所以不需要在寫入時維護記憶體索引,只需要在恢復階段恢復索引順序,反推出資料的邏輯偏移,因為key和value在同一個分割槽的位置是一一對應的。
恢復階段
需要在資料庫引擎啟動時,將索引從資料檔案恢復到記憶體中。
由於有1024個分割槽,可以使用64個執行緒併發恢復索引,使用快速排序對 key[1024][62500] 陣列和 offset[1024][62500] 進行 sort,之後再 compact,對 key 進行去重。
資料隨機讀取
根據key定位到分割槽,之後在有序的key資料中進行二分查詢key/offset,拿到資料的邏輯偏移和分割槽編號,可以隨機讀取了。
資料順序讀取
順序讀取思路是生產者消費者模型,n個生產者從磁碟讀資料放入記憶體,64個消費執行緒消費同時判斷記憶體資料以驗證資料。
直接記憶體的使用和JVM調優
堆外記憶體的好處是大大減少了一份記憶體拷貝,並且對gc友好。
-
server
-
Xms2560m
-
Xmx2560m
-
XX
:
MaxDirectMemorySize
=
1024m
-
XX
:
NewRatio
=
4
-
XX
:+
UseConcMarkSweepGC
-
XX
:+
UseParNewGC
-
XX
:-
UseBiasedLocking
- young區過大,物件在年輕代呆的太久,多次拷貝。
- old區太小,會頻繁觸發old區的cms gc。
對於那些需要反覆new出來的東西,都可以池化,分配記憶體在回收也是不小的開銷,直接可以使用threadlocal快取搞定。
減少執行緒切換
io執行緒的切換成本很高,為了減少io執行緒的時間片流失可以考慮使用while(true)輪訓,也可以採用sleep(1us)避免cpu空轉帶來的整體效能問題。
機器抖動在所難免,避免IO切換不能靠while(true),cpu級別的優化可以專門騰出4個核心專門給IO執行緒使用,避免IO執行緒的時間片徵用(採用Affinity )。