
sql 中count 在innodb 和myisam 表型別的查詢快慢
在sql中經常會用到count(*) 或者不常用的count(‘列’),在innodb和myisam 的查詢速度有多大,原理又是什麼?
下面我們首先嘮嘮myisam和innodb主要區別
1).MyISAM是非事務安全型的,而InnoDB是事務安全型的。
2).MyISAM鎖的粒度是表級,而InnoDB支援行級鎖定。
3).MyISAM支援全文型別索引,而InnoDB不支援全文索引。
4).MyISAM相對簡單,所以在效率上要優於InnoDB,小型應用可以考慮使用MyISAM。
5).MyISAM表是儲存成檔案的形式,在跨平臺的資料轉移中使用MyISAM儲存會省去不少的麻煩。
6).InnoDB表比MyISAM表更安全
myisam 和 innodb中count(*)查詢快慢原理
在myisam中count(*)查詢,myisam引擎很容易獲得總行數的統計。查詢速度變得更快。因為myisam儲存引擎已經儲存了表的總行數。每次新增加一行,這個計數器就加1。也就是說,把表的總數快取在索引中了。
注意一點
**:myisam儲存引擎的表,count()速度快的也僅僅是不帶where條件的count。這個想想容易理解的,因為你帶了where限制條件,原來所以中快取的表總數能夠直接返回用嗎?不能用。這個查詢引擎也是需要根據where條件去表中掃描資料,進行統計返回的。
**:針對Innodb表,儘量不執行 SELECT COUNT(
下面是一個myisam和innodb的300萬條資料count()查詢的結果(不帶where條件)
myisam:
查詢結果時間:
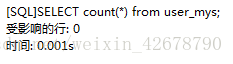
innodb:
比較得知:myisam 中count() 不帶where條件下較innodb快很多
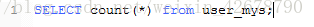
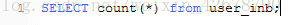
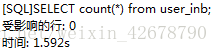
那麼帶上where條件後查詢速度會是怎樣,下面通過實踐來證明一下
myisam:
查詢結果:
innodb:



查詢結果:

所以,可根據自己的綜合情況,來進行count(*) 的使用.
那麼為什麼count(*) 加where條件,同樣是全表掃描myisam 比innodb查詢要快勒?
because…
INNODB在做SELECT的時候,要維護的東西比MYISAM引擎多很多;
1)INNODB要快取資料塊,MYISAM只快取索引塊, 這中間還有換進換出的減少;
2)innodb定址要對映到塊,再到行,MYISAM 記錄的直接是檔案的OFFSET,定位比INNODB要快
寫的可能不完善,歡迎大家指正,共同進步
-----------------------------------------------------------------------------------------------------行走的辛同學------------