
《Pro SQL Server Internals》翻譯之叢集索引
本文選自《Pro SQL Server Internals》
作者: Dmitri Korotkevitch
出版社: Apress
出版年: 2016-12-29
頁數: 804
作者簡介:Dmitri Korotkevitchis是微軟SQL Server MVP和微軟認證大師。作為應用程式和資料庫開發人員、資料庫管理員和資料庫架構師,他具有多年使用SQL Server的經驗。他專門從事OLTP系統在高負載下的設計、開發和效能調優。Dmitri經常在各種Microsoft和SQL PASS活動上發言,他為世界各地的客戶提供SQL Server培訓。
原文連結:http://www.doc88.com/p-4042504089228.html
叢集索引設計注意事項
每次更改叢集索引鍵的值時,都會發生兩件事。首先,SQL Server移動行到群集索引頁鏈和資料檔案中的另一個位置。其次,它更新行id,這是群集索引鍵。行id儲存在所有非叢集索引中就需要更新。就I/O而言,這可能很昂貴,尤其是在批量更新的情況下。此外,它可以增加叢集索引的碎片化,以及在行id大小增加的情況下,非叢集索引的碎片化。因此,在鍵值不變的情況下,最好使用靜態聚集索引。
所有非聚集索引都使用聚集索引鍵作為行id。一個太寬的聚集索引鍵增加非聚集索引行的大小,並需要更多空間來儲存它們。因此,SQL Server在索引或範圍掃描操作期間需要處理更多的資料頁,這使得索引更少非常高效。
對於非惟一非聚集索引,行id也儲存在非葉索引級別,反過來,也減少了每頁索引記錄的數量,並可能導致索引中額外的中間級別。即使非葉索引級別通常快取在記憶體中,這也會引入額外的邏輯讀取每次SQL Server遍歷非叢集索引B-樹。
最後,較大的非叢集索引會在緩衝池中使用更多空間,並在索引維護中帶來更多開銷。顯然,不可能提供一個通用閾值來定義可應用於任何表的鍵的最大可接受大小。但是,一般來說,最好是有一個窄的聚集索引鍵,索引鍵越小越好。
將聚集索引定義為惟一的也是有益的。這很重要的原因不是顯而易見的。考慮一個場景,其中一個表沒有惟一的聚集索引,希望執行一個在執行計劃中使用非叢集索引的查詢。在這種情況下,如果行
SQL Server通過向nonunique新增另一個名為uniquifier的可空整數列來解決此類問題聚集索引。SQL Server使用NULL填充第一次出現鍵的uniquifiers
值,為插入到表中的每個後續副本自動遞增該值。
■注意可能重複的數量每聚集索引鍵值是有限整數域值。使用相同的聚集索引鍵,不能有超過2,147,483,648行。這是一個理論極限,建立選擇性如此差的索引顯然不是一個好主意。
讓我們看看在非惟一聚集索引中uniquifiers引入的開銷。所示的程式碼在清單7-1中,建立了三個相同結構的不同表,並使用65,536行填充它們。表dbo.UniqueCI定義了惟一叢集索引。表dbo.NonUniqueCINoDups沒有任何重複的鍵值。最後,表dbo.NonUniqueCDups具有大量在索引中複製。
清單7 - 1。非惟一聚集索引:表建立
create table dbo.UniqueCI
(
KeyValue int not null,
ID int not null,
Data char(986) null,
VarData varchar(32) not null
constraint DEF_UniqueCI_VarData
default 'Data'
);
create unique clustered index IDX_UniqueCI_KeyValue
on dbo.UniqueCI(KeyValue);
create table dbo.NonUniqueCINoDups
(
KeyValue int not null,
ID int not null,
Data char(986) null,
VarData varchar(32) not null
constraint DEF_NonUniqueCINoDups_VarData
default 'Data'
);
create /*unique*/ clustered index IDX_NonUniqueCINoDups_KeyValue
on dbo.NonUniqueCINoDups(KeyValue);
create table dbo.NonUniqueCIDups
(
KeyValue int not null,
ID int not null,
Data char(986) null,
VarData varchar(32) not null
constraint DEF_NonUniqueCIDups_VarData
default 'Data'
);
create /*unique*/ clustered index IDX_NonUniqueCIDups_KeyValue
on dbo.NonUniqueCIDups(KeyValue);
-- Populating data
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows
,N5(C) as (select 0 from N4 as T1 cross join N4 as T2) -- 65,536 rows
,IDs(ID) as (select row_number() over (order by (select null)) from N5)
insert into dbo.UniqueCI(KeyValue, ID)
select ID, ID from IDs;
insert into dbo.NonUniqueCINoDups(KeyValue, ID)
select KeyValue, ID from dbo.UniqueCI;
insert into dbo.NonUniqueCIDups(KeyValue, ID)
select KeyValue % 10, ID from dbo.UniqueCI;
現在,讓我們看看每個表的聚集索引的物理統計資訊。其程式碼顯示在清單7-2,結果如圖7-1所示。
清單7 - 2。非唯一聚集索引:檢查聚集索引的行大小
select index_level, page_count, min_record_size_in_bytes as [min row size]
,max_record_size_in_bytes as [max row size]
,avg_record_size_in_bytes as [avg row size]
from
sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.UniqueCI'), 1, null ,'DETAILED');
select index_level, page_count, min_record_size_in_bytes as [min row size]
,max_record_size_in_bytes as [max row size]
, avg_record_size_in_bytes as [avg row size]
from
sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.NonUniqueCINoDups'), 1, null,'DETAILED');
select index_level, page_count, min_record_size_in_bytes as [min row size]
,max_record_size_in_bytes as [max row size]
,avg_record_size_in_bytes as [avg row size]
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.NonUniqueCIDups'), 1, null
,'DETAILED');
圖7 - 1。非唯一聚集索引:聚集索引的行大小
即使表dbo.NonUniqueCINoDups中沒有重複的鍵值,表中還有兩個新增到行的額外位元組。SQL Server在資料的可變長度部分儲存一個uniquifier,和這兩個位元組由可變長度資料偏移陣列中的另一個條目新增。
在這種情況下,當叢集索引具有重複值時,uniquifiers將再新增4個位元組,即導致總共6位元組的開銷。
值得一提的是,在某些邊緣情況下,uniquifier使用的額外儲存空間可以減少資料頁上可以容納的行數。我們的示例演示了這種情況。你可以看到,表dbo.UniqueCI與其他兩個表相比使用的資料頁少了大約15%。
現在,讓我們看看uniquifier如何影響非叢集索引。清單7-3所示的程式碼建立三個表中的非聚集索引。圖7-2顯示了這些索引的物理統計資訊。
清單7。非唯一聚集索引:檢查非聚集索引的行大小
create nonclustered index IDX_UniqueCI_ID
on dbo.UniqueCI(ID);
create nonclustered index IDX_NonUniqueCINoDups_ID
on dbo.NonUniqueCINoDups(ID);
create nonclustered index IDX_NonUniqueCIDups_ID
on dbo.NonUniqueCIDups(ID);
select index_level, page_count, min_record_size_in_bytes as [min row size]
,max_record_size_in_bytes as [max row size]
,avg_record_size_in_bytes as [avg row size]
from
sys. dm_db_index_physical_stats(db_id(), object_id(N'dbo.UniqueCI'), 2, null
,'DETAILED');
select index_level, page_count, min_record_size_in_bytes as [min row size]
,max_record_size_in_bytes as [max row size]
,avg_record_size_in_bytes as [avg row size]
from
sys. dm_db_index_physical_stats(db_id(), object_id(N'dbo.NonUniqueCINoDups'), 2, null
,'DETAILED');
select index_level, page_count, min_record_size_in_bytes as [min row size]
,max_record_size_in_bytes as [max row size]
,avg_record_size_in_bytes as [avg row size]
from
sys. dm_db_index_physical_stats(db_id(), object_id(N'dbo.NonUniqueCIDups'), 2, null
,'DETAILED');
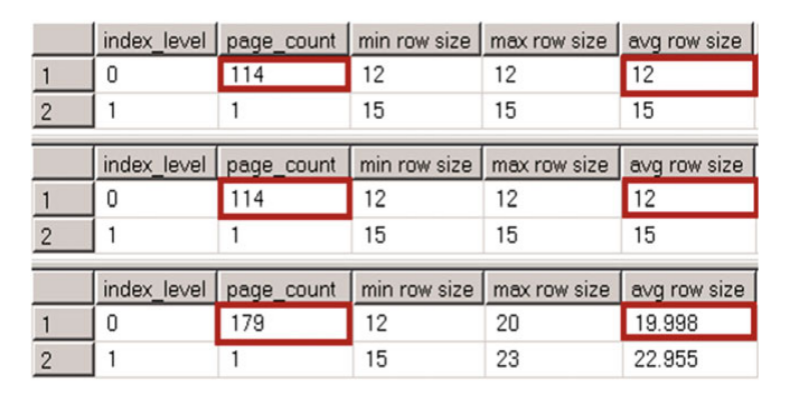
圖7-2 不唯一聚集索引:非聚集索引大小
dbo.NonUniqueCINoDups表中的非聚集索引沒有開銷。 您可能還記得,SQL Server不會將偏移量資訊儲存在可變長度偏移陣列中,以便跟蹤列儲存空資料。 儘管如此,識別符號介紹八個位元組在dbo.NonUniqueCIDups表中的開銷。 這八個位元組包括一個四位元組的識別符號值,兩個位元組的可變長度資料的偏移陣列條目,和兩個位元組的條目中儲存的行中的可變長度的列數的。
我們可以總結的識別符號的儲存開銷以下列方式。 對於具有識別符號為空的行,如果索引至少有一個儲存不為空值的可變長度列,則會產生兩位元組開銷。該開銷來自識別符號列的可變長度偏移陣列條目。 否則沒有開銷。在填充識別符號的情況下,如果存在儲存不為空的值的可變長度列,則開銷為六個位元組。 否則,開銷是8個位元組
■提示如果預計聚簇索引值中存在大量重複項,則可以將整數標識列作為索引的最右列新增,從而使其唯一。 與由識別符號引入的不可預測的高達8位元組的儲存開銷相比,這為每一行增加了四位元組可預測的儲存開銷。 當您通過其所有聚簇索引列引用該行時,這還可以提高單個查詢操作的效能。
以最小化插入新行導致的索引碎片的方式設計聚簇索引是有益的。 實現此目標的方法之一是使聚簇索引值不斷增加。 標識列上的索引就是一個這樣的例子。 另一個示例是使用插入時的當前系統時間填充的日期時間列。
然而,不斷增加的指數存在兩個潛在的問題。 第一個涉及統計。 正如您在第3章中學到的,當直方圖中不存在引數值時,SQL Server中的遺留基數估計器會低估基數。 您應該將此類行為納入系統的統計資訊維護策略,除非您使用新的SQL Server 2014-2016基數估算器,該估算器假定直方圖之外的資料具有與表中其他資料類似的分佈。
下一個問題更復雜。 隨著索引的不斷增加,資料總是插入到索引的末尾。 一方面,它可以防止頁面拆分並減少碎片。 另一方面,它可能導致熱點,這是多個會話嘗試修改同一資料頁和/或分配新頁面或擴充套件區時發生的序列化延遲SQL Server不允許多個會話更新相同的資料結構,而是序列化這些操作。
除非系統以非常高的速率收集資料並且索引每秒處理數百個插入,否則熱點通常不是問題。 我們將在第27章“系統故障排除”中討論如何檢測此類問題。
最後,如果系統具有一組頻繁執行且重要的查詢,則考慮聚合索引可能是有益的,這會優化它們。 這消除了昂貴的金鑰查詢操作並提高了系統的效能。
即使可以使用覆蓋非聚集索引來優化此類查詢,但它並不總是理想的解決方案。 在某些情況下,它需要您建立非常寬的非聚集索引,這將佔用磁碟和緩衝池中的大量儲存空間。
另一個重要因素是修改列的頻率。 將經常修改的列新增到非聚集索引需要SQL Server在多個位置更改資料,這會對系統的更新效能產生負面影響並增加阻塞。
儘管如此,並不總是能夠設計滿足所有這些準則的聚集索引。 此外,您不應將這些指南視為絕對要求。 您應該分析系統,業務需求,工作負載和查詢,並選擇有益於您的聚集索引,即使它們違反了某些準則。
標識、序列和識別符號
人們通常選擇身份,序列和唯一識別符號作聚集索引鍵。 與往常一樣,這種方法有其自身的優缺點。
在此類列上定義的聚集索引是唯一的,靜態的和窄的。 此外,身份和序列不斷增加,這減少了索引碎片。 其中一個理想的用例是目錄實體表。 作為示例,您可以考慮儲存客戶,文章或裝置列表的表。 這些表儲存數千甚至數百萬行,儘管資料相對靜態,因此熱點不是問題。 此外,這些表通常由外來鍵引用並用於連線。 整型或bigint型列上的索引非常緊湊和高效,這將提高查詢的效能。
■注意我們將在第8章“約束”中更詳細地討論外來鍵約束。
在事務表的情況下,身份或序列列上的聚集索引效率較低,事務表由於它們引入的潛在熱點而以非常高的速率收集大量資料。
另一方面,識別符號號很少是叢集和非叢集索引的理想選擇。 使用NEWID()函式生成的隨機值極大地增加了索引碎片。 此外,識別符號號上的索引會降低批處理操作的效能。 讓我們看一個示例並建立兩個表:一個表在標識列上有聚集索引,另一個在識別符號號列上有聚集索引。 在下一步中,我們將在兩個表中插入65,536行。 您可以在清單7-4中看到執行此操作的程式碼。
清單7-4 識別符號:表建立
(
ID int not null identity(1,1),
Val int not null,
Placeholder char(100) null
);
create unique clustered index IDX_IdentityCI_ID
on dbo.IdentityCI(ID);
create table dbo.UniqueidentifierCI
(
ID uniqueidentifier not null
constraint DEF_UniqueidentifierCI_ID
default newid(),
Val int not null,
Placeholder char(100) null,
);
create unique clustered index IDX_UniqueidentifierCI_ID
on dbo.UniqueidentifierCI(ID)
go
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows
,N5(C) as (select 0 from N4 as T1 cross join N4 as T2) -- 65,536 rows
,IDs(ID) as (select row_number() over (order by (select null)) from N5)
insert into dbo.IdentityCI(Val)
select ID from IDs;
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows
,N5(C) as (select 0 from N4 as T1 cross join N4 as T2) -- 65,536 rows
,IDs(ID) as (select row_number() over (order by (select null)) from N5)
insert into dbo.UniqueidentifierCI(Val)
select ID from IDs;
我的計算機上的執行時間和讀取次數如表7-1所示。 圖7-3顯示了兩個查詢的執行計劃。
表7-1 將資料插入表:執行統計

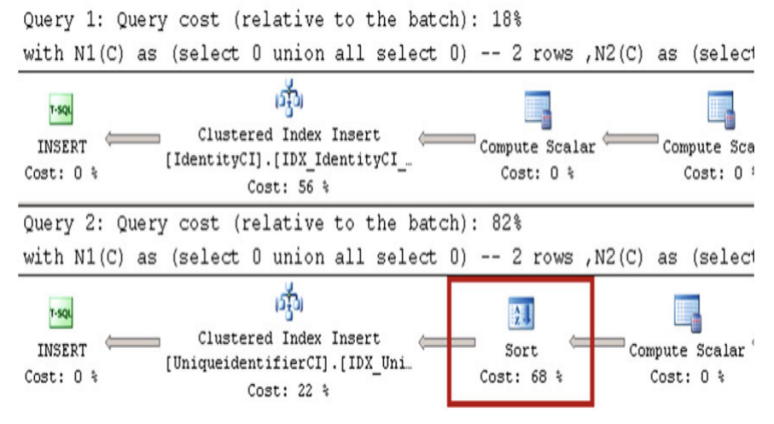
圖7-3 將資料插入表中:執行計劃
如您所見,識別符號列上的索引有另一個排序運算子。 SQL Server在插入之前對隨機生成的識別符號值進行排序,這會降低查詢的效能。
讓我們在表中插入另一批行並檢查索引碎片。 執行此操作的程式碼如清單7-5所示。 圖7-4顯示了查詢的結果。
清單7-5 識別符號:插入行並檢查碎片
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows
,N5(C) as (select 0 from N4 as T1 cross join N4 as T2) -- 65,536 rows
,IDs(ID) as (select row_number() over (order by (select null)) from N5)
insert into dbo.IdentityCI(Val)
select ID from IDs;
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows
,N5(C) as (select 0 from N4 as T1 cross join N4 as T2) -- 65,536 rows
,IDs(ID) as (select row_number() over (order by (select null)) from N5)
insert into dbo.UniqueidentifierCI(Val)
select ID from IDs;
select page_count, avg_page_space_used_in_percent, avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.IdentityCI'),1,null,'DETAILED');
select page_count, avg_page_space_used_in_percent, avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.UniqueidentifierCI'),1,null
,'DETAILED');
insert into dbo.UniqueidentifierCI(Val)
select ID from IDs;
select page_count, avg_page_space_used_in_percent, avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.IdentityCI'),1,null,'DETAILED');
select page_count, avg_page_space_used_in_percent, avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.UniqueidentifierCI'),1,null
,'DETAILED');

圖7-4。 索引碎片
如您所見,uniqueidentifier列上的索引嚴重碎片化,使用大約40個
與標識列上的索引相比,資料頁面的百分比更多。
在uniqueidentifier列的索引中的批量插入會在資料檔案的不同位置插入資料,這會導致在大型表的情況下出現繁重的隨機物理I / O.這會顯著降低操作的效能。
個人經驗
前段時間,我參與了一個系統的優化,該系統具有250 GB的表,其中包含一個聚簇索引和三個非聚簇索引。 其中一個非聚簇索引是uniqueidentifier列上的索引。 通過刪除此索引,我們能夠將50,000行的批量插入從45秒加速到7秒。
當您想要在uniqueidentifier列上建立索引時,有兩種常見用例。 第一個是支援跨多個數據庫的值的唯一性。考慮一個可以將行插入每個資料庫的分散式系統。開發人員通常使用uniqueidentifier來確保每個鍵值在系統範圍內都是唯一的。
此類實現中的關鍵元素是如何生成鍵值。 正如您已經看到的,使用NEWID()函式或客戶端程式碼生成的隨機值會對系統性能產生負面影響。但是,您可以使用NEWSEQUENTIALID()函式,該函式生成唯一且通常增加的值(SQL Server能夠隨時重置它們的值)。 使用NEWSEQUENTIALID()函式生成的uniqueidentifier列的索引類似於identity和sequence列的索引; 但是,您應該記住,uniqueidentifier資料型別使用16位元組的儲存空間,而4位元組的int或8位元組的bigint資料型別。
作為替代解決方案,您可以考慮建立一個包含兩列的複合索引(Installation Id,Unique_Id_Within Installation)。這兩列的組合保證了多個安裝和資料庫的唯一性,並且使用的儲存空間比uniqueidentifier更少。您可以使用整數 用於生成Unique_Id_Within_Installation值的標識或序列,這將減少索引的碎片。
如果需要在資料庫中的所有實體上生成唯一鍵值,則可以考慮在所有實體中使用單個序列物件。 此方法滿足要求,但使用比uniqueidentifier更小的資料型別。
另一個常見用例是安全性,其中uniqueidentifier值用作安全性令牌或隨機物件ID。 不幸的是,您無法在此方案中使用NEWSEQUENTIALID()函式,因為可以猜測該函式返回的下一個值。
在這種情況下,一種可能的改進是使用CHECKSUM()函式建立計算列,然後對其進行索引,而不在uniqueidentifier列上建立索引。 程式碼如清單7-6所示。
清單7-6。 使用CHECKSUM():表結構
create table dbo.Articles
(
ArticleId int not null identity(1,1),
ExternalId uniqueidentifier not null
constraint DEF_Articles_ExternalId
default newid(),
ExternalIdCheckSum as checksum(ExternalId),
/* Other Columns */
);
create unique clustered index IDX_Articles_ArticleId
on dbo.Articles(ArticleId);
create nonclustered index IDX_Articles_ExternalIdCheckSum
on dbo.Articles(ExternalIdCheckSum);
提示:可以索引計算列而不保留它。
儘管IDX Articles ExternalId CheckSum索引將會嚴重碎片化,但與uniqueidentifier列上的索引(4位元組金鑰與16位元組)相比,它將更加緊湊。 它還提高了批處理操作的效能,因為更快的排序,這也需要更少的記憶體來進行。
您必須記住的一件事是CHECKSUM()函式的結果不保證是唯一的。 您應該在查詢中包含兩個謂詞,如清單7-7所示。
清單7-7。 使用CHECKSUM():選擇資料
select ArticleId /* Other Columns */
from dbo.Articles
where checksum(@ExternalId) = ExternalIdCheckSum and ExternalId = @ExternalId
注意:在需要索引大於900 / 1,700位元組的字串列的情況下,可以使用相同的技術,這是非聚簇索引鍵的最大大小。 即使這樣的索引不支援範圍掃描操作,它也可以用於點查詢。
非聚集索引設計注意事項
當單非聚簇索引查詢和鍵查詢操作時,很難找到連線多個非聚簇索引比使用更有效的轉折點。當索引選擇性很高並且SQL Server估計索引查詢操作將返回少量行時,鍵查詢成本將相對較低。 在這種情況下,沒有理由使用另一個非聚集索引。或者,當索引選擇性較低時,索引查詢會返回大量行,而SQL Server通常不會使用它,因為效率不高。
讓我們看一個示例,我們將建立一個表並用1,048,576行填充它。 Col1在列中儲存50個不同的值,Col2儲存150個值,Col3儲存200個值。 最後,我們將在表上建立三個不同的非聚簇索引。 執行此操作的程式碼如清單7-8所示。
清單7-8。 多個非聚簇索引:表建立
create table dbo.IndexIntersection
(
Id int not null,
Placeholder char(100),
Col1 int not null,
Col2 int not null,
Col3 int not null
);
on dbo.IndexIntersection(ID);
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows
,N5(C) as (select 0 from N4 as T1 cross join N4 as T2) -- 65,536 rows
,N6(C) as (select 0 from N3 as T1 cross join N5 as T2) -- 1,048,576 rows
,IDs(ID) as (select row_number() over (order by (select null)) from N6)
insert into dbo.IndexIntersection(ID, Col1, Col2, Col3)
select ID, ID % 50, ID % 150, ID % 200 from IDs;
create nonclustered index IDX_IndexIntersection_Col1
on dbo.IndexIntersection(Col1);
create nonclustered index IDX_IndexIntersection_Col2
on dbo.IndexIntersection(Col2);
create nonclustered index IDX_IndexIntersection_Col3
on dbo.IndexIntersection(Col3);