
String型別踩坑
阿新 • • 發佈:2018-12-12
1.
public static void main(String[] args) {
String a = "ab";
String b= new String("ab");
System.out.println(a==b);
}
輸出結果:false
解析:
當我們像上述程式碼第二行一樣聲明瞭一個字串變數並且給它賦值的時候,這個字串變數a儲存在字串常量池中;當我們像第三行一樣使用構造方法構建了一個字串物件並賦值的時候,這個字串變數b儲存在堆中。使用"=="符號比較的是兩個字串變數的地址,字串常量池中的變數的地址當然和堆中變數的地址不一樣,因此會顯示false。
2.
public static void main(String[] args) {
String a = "a"+"b";
String b = "ab";
System.out.println(a==b);
}
輸出結果:true
解析:
當使用第二行程式碼這樣拼接字串之後,在拼接完成後會自動在字串常量池中尋找是否有和拼接完成後相同的字串,如果有,就將字串指向那個拼接完成後的地址,因此,此時的a和b地址相同,那麼使用"=="去判斷當然就返回true了。
3.
public static void main(String[] args) {
String s1= 輸出結果:
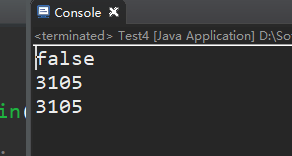
解析:
那麼如果使用這種方式去拼接為什麼和上一種結果不一樣呢?
這是因為,如果我們使用兩個字串物件拼接,java會自動轉化為StringBuffer型別去拼接字串,也就是說,上面的第四行程式碼等同於下面的這行程式碼:
String s = new StringBuffer 而StringBuffer是物件,是儲存在堆中的,因此這裡的s在堆中,t在字串常量池中,那麼地址當然不一樣了,所以會輸出false。那有人可能又要問了,既然地址不一樣,那麼為什麼s和t的hashcode是一樣的呢?注意,hashcode並不是真正的實體地址,並且,String型別對它的hashcode()方法做了重寫,重寫之後只要字串的值一樣那麼它們的hashcode()返回值就一樣。而字串的equals()方法正是使用hashcode()來判斷字串相等的,這也就解釋了為什麼equals方法可以判斷地址不同但是字串值相同的字串為true。