
C++---C/C++預處理指令#define,#ifdef,#ifndef,#endif
本文主要記錄了C/C++預處理指令,常見的預處理指令如下:
- #空指令,無任何效果
- #include包含一個原始碼檔案
- #define定義巨集
- #undef取消已定義的巨集
- #if如果給定條件為真,則編譯下面程式碼
- #ifdef如果巨集已經定義,則編譯下面程式碼
- #ifndef如果巨集沒有定義,則編譯下面程式碼
- #elif如果前面的#if給定條件不為真,當前條件為真,則編譯下面程式碼
- #endif結束一個#if……#else條件編譯塊
- #error停止編譯並顯示錯誤資訊
本來只是想了解一下#ifdef,#ifndef,#endif的,沒想到查出來這麼多的預處理指令,上面的多數都是常見的,但是平時沒有怎麼注意預處理這方面的內容,所以這裡梳理一下知識吧。同時有什麼不妥的地方,或者遺漏了什麼內容,還請留言指出。
什麼是預處理指令?
預處理指令是以#號開頭的程式碼行。#號必須是該行除了任何空白字元外的第一個字元。#後是指令關鍵字,在關鍵字和#號之間允許存在任意個數的空白字元。整行語句構成了一條預處理指令,該指令將在編譯器進行編譯之前對原始碼做某些轉換。
以前沒有在意的學者注意了,預處理指令是在編譯器進行編譯之前進行的操作.預處理過程掃描原始碼,對其進行初步的轉換,產生新的原始碼提供給編譯器。可見預處理過程先於編譯器對原始碼進行處理。在很多程式語言中,並沒有任何內在的機制來完成如下一些功能:在編譯時包含其他原始檔、定義巨集、根據條件決定編譯時是否包含某些程式碼(防止重複包含某些檔案)。要完成這些工作,就需要使用預處理程式。儘管在目前絕大多數編譯器都包含了預處理程式,但通常認為它們是獨立於編譯器的。預處理過程讀入原始碼,檢查包含預處理指令的語句和巨集定義,並對原始碼進行響應的轉換。預處理過程還會刪除程式中的註釋和多餘的空白字元。
#include包含一個原始碼檔案
這個預處理指令,我想是見得最多的一個,簡單說一下,第一種方法是用尖括號把標頭檔案括起來。這種格式告訴預處理程式在編譯器自帶的或外部庫的標頭檔案中搜索被包含的標頭檔案。第二種方法是用雙引號把標頭檔案括起來。這種格式告訴預處理程式在當前被編譯的應用程式的原始碼檔案中搜索被包含的標頭檔案,如果找不到,再搜尋編譯器自帶的標頭檔案。採用兩種不同包含格式的理由在於,編譯器是安裝在公共子目錄下的,而被編譯的應用程式是在它們自己的私有子目錄下的。一個應用程式既包含編譯器提供的公共標頭檔案,也包含自定義的私有標頭檔案。採用兩種不同的包含格式使得編譯器能夠在很多標頭檔案中區別出一組公共的標頭檔案。
#define定義巨集
有關#define這個巨集定義,在C語言中使用的很多,因為#define存在一些不足,C++強調使用const來定義常量。巨集定義了一個代表特定內容的識別符號。預處理過程會把原始碼中出現的巨集識別符號替換成巨集定義時的值。記住僅僅是進行識別符號的替換。下面列舉一些#define的使用:
- 用#define實現求最大值和最小值的巨集

#include <stdio.h> #define MAX(x,y) (((x)>(y))?(x):(y)) #define MIN(x,y) (((x)<(y))?(x):(y)) int main(void) { #ifdef MAX //判斷這個巨集是否被定義 printf("3 and 5 the max is:%d\n",MAX(3,5)); #endif #ifdef MIN printf("3 and 5 the min is:%d\n",MIN(3,5)); #endif return 0; } /* * (1)三元運算子要比if,else效率高 * (2)巨集的使用一定要細心,需要把引數小心的用括號括起來, * 因為巨集只是簡單的文字替換,不注意,容易引起歧義錯誤。 */ - 巨集定義的錯誤使用
#include <stdio.h> #define SQR(x) (x*x) int main(void) { int b=3; #ifdef SQR//只需要巨集名就可以了,不需要引數,有引數的話會警告 printf("a = %d\n",SQR(b+2)); #endif return 0; } /* *首先說明,這個巨集的定義是錯誤的。並沒有實現程式中的B+2的平方 * 預處理的時候,替換成如下的結果:b+2*b+2 * 正確的巨集定義應該是:#define SQR(x) ((x)*(x)) * 所以,儘量使用小括號,將引數括起來。 */ - 巨集引數的連線
#include <stdio.h> #define STR(s) #s #define CONS(a,b) (int)(a##e##b) int main(void) { #ifdef STR printf(STR(VCK)); #endif #ifdef CONS printf("\n%d\n",CONS(2,3)); #endif return 0; } /* (絕大多數是使用不到這些的,使用到的話,檢視手冊就可以了) * 第一個巨集,用#把引數轉化為一個字串 * 第二個巨集,用##把2個巨集引數粘合在一起,及aeb,2e3也就是2000 */ - 用巨集得到一個字的高位或低位的位元組
#include <stdio.h> #define WORD_LO(xxx) ((byte)((word)(xxx) & 255)) #define WORD_HI(xxx) ((byte)((word)(xxx) >> 8)) int main(void) { return 0; } /* * 一個字2個位元組,獲得低位元組(低8位),與255(0000,0000,1111,1111)按位相與 * 獲得高位元組(高8位),右移8位即可。 */ - 用巨集定義得到一個數組所含元素的個數
#include <stdio.h> #define ARR_SIZE(a) (sizeof((a))/sizeof((a[0]))) int main(void) { int array[100]; #ifdef ARR_SIZE printf("array has %d items.\n",ARR_SIZE(array)); #endif return 0; } /* *總的大小除以每個型別的大小 */
關於#define巨集的使用,應該特別小心,尤其是含有引數計算的時候如小2示例,最保險的做法將引數用括號括起來。
#ifdef,#ifndef,#endif...的使用
以上這些預編譯指令,都是條件編譯指令,也就是說,將決定那些程式碼被編譯,而哪些不被編譯。
- 示例1:
#include <stdio.h> #include <stdlib.h> #define DEBUG int main(void) { int i = 0; char c; while(1) { i++; c = getchar(); if('\n' != c) { getchar(); } if('q' == c || 'Q' == c) { #ifdef DEBUG//判斷DEBUG是否被定義了 printf("We get:%c,about to exit.\n",c); #endif break; } else { printf("i = %d",i); #ifdef DEBUG printf(",we get:%c",c); #endif printf("\n"); } } printf("Hello World!\n"); return 0; } /*#endif用於終止#if預處理指令。*/ - ifdef 和 #ifndef
#include <stdio.h> #define DEBUG main() { #ifdef DEBUG printf("yes "); #endif #ifndef DEBUG printf("no "); #endif } //#ifdefined等價於#ifdef; //#if!defined等價於#ifndef - #else指令
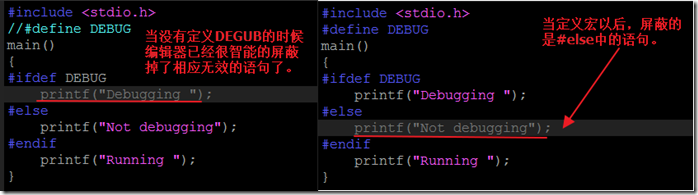
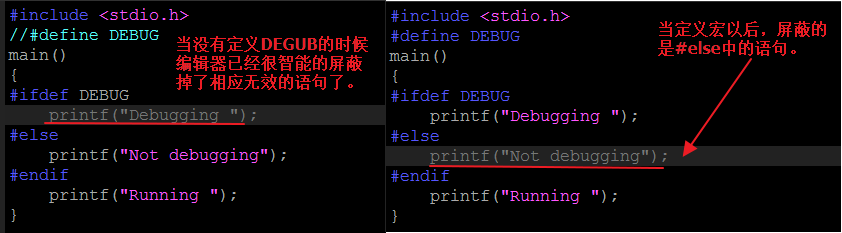
- #elif指令
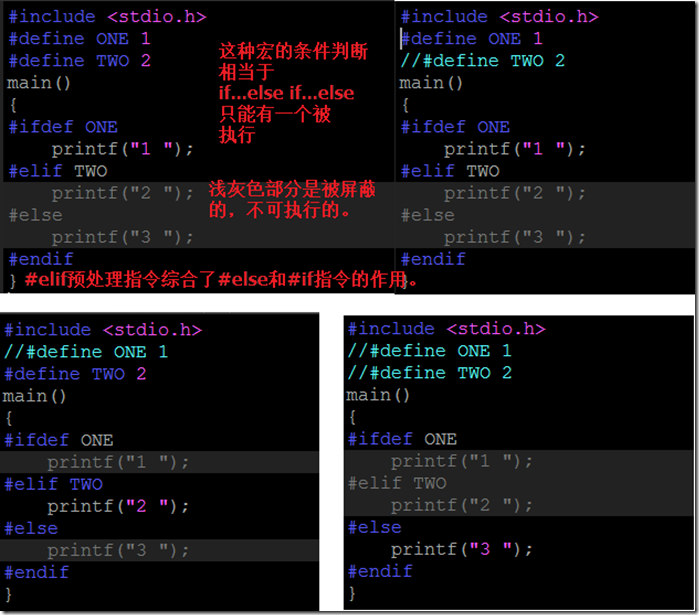
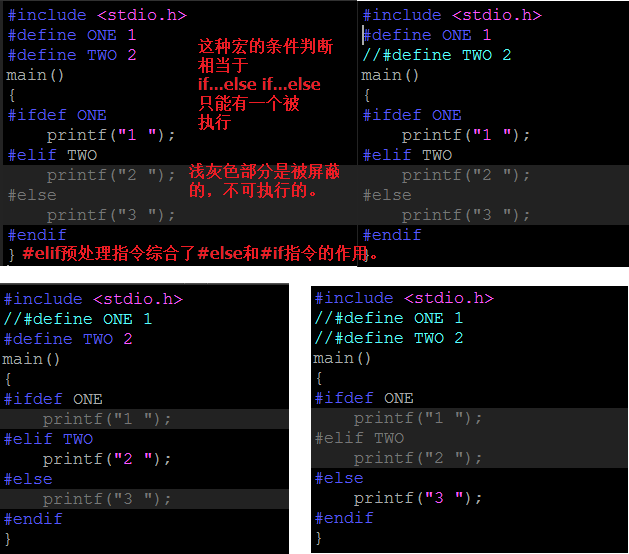
- 其他一些指令
#error指令將使編譯器顯示一條錯誤資訊,然後停止編譯。 #line指令可以改變編譯器用來指出警告和錯誤資訊的檔案號和行號。 #pragma指令沒有正式的定義。編譯器可以自定義其用途。典型的用法是禁止或允許某些煩人的警告資訊。
小結:
預處理就是在進行編譯的第一遍詞法掃描和語法分析之前所作的工作。說白了,就是對原始檔進行編譯前,先對預處理部分進行處理,然後對處理後的程式碼進行編譯。這樣做的好處是,經過處理後的程式碼,將會變的很精短。
參考資料:晚上的影子
2016年11月12日更新:
寫這篇博文的時候, 還沒有參加工作. 現在回過頭來, 感覺這篇內容寫的還是很晦澀難懂. 因為當時的我處於學生時代, 對於技術的理解只有輸入, 沒有過多的工程化的輸出, 導致一些東西理解的還是不夠透徹. 過於這些巨集的理解, 目前, 可以簡單的做一下的總結(巨集的基礎知識,往下看即可);
工作中經常這樣使用巨集:
1. 常常使用巨集來除錯程式碼:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
通過以上類似的方法, 可以防止由於過多的修改程式碼, 而把程式碼修改的一塌糊塗. 建議修改程式碼的時候, 做到保護好以前的程式碼, 儘量不進行程式碼的刪除操作. 切記, 能不刪除, 就不刪除...不要養成隨手就刪除的習慣. 要養成使用巨集和註釋程式碼的習慣.
2. 使用巨集來根據不同的平臺包含不同的檔案. 很多時候, 我們的程式碼是需要跨系統平臺編譯和執行的. 比如: 一個小功能程式碼, 需要既可以在Win下面執行, 還要可以在Max, linux上面執行. 可是, 因為系統的不一樣, 有些時候, 標頭檔案的包含的名字是不一樣的. 所以,這時候, 就是用到了巨集. 因為我們使用程式設計工具分不同的系統平臺, 程式設計工具自身的環境就會包含不同平臺的系統巨集, 假設OS_Win, OS_Mac, OS_Linux 分別程式碼三種系統不同的巨集. 而且,Win版本的程式設計工具中已經定義了OS_Win, 類似的Mac下, 程式設計工具定義的是OS_Mac, Linux...
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
3. 接著就是巨集定義了. 使用巨集來定義一些常量, 表示式...詳細內容, 見下面
2016年12月29日更新:
今天檢視以前檔案的時候, 突然發現了#error 這個預處理指令.然後回想一下工作, 發現這個指令使用場景還是很多的.比如: 一個專案的模組兒之多,原始檔之大,程式碼之多,那麼其中的巨集, 也會很多. 免不了衝突定義.這時候, 我們就需要編譯器能及早的告訴我們.那就是在編譯的時候.#error就可以這麼實現:
/** 如果JOE巨集沒有定義,那麼編譯就此結束, 編譯器就會顯示紅色的錯誤 */ #ifndef JOE #error "JOE is not exits" #endif