
匿名內部類類名規則($1,$2)
匿名內部類屬於內部類的其中一種,從內部類講起,內部類型別共有如下:
1.成員內部類
public class A {
String s;
class B{
}
}B就是成員內部類,例項化B需要先例項化A物件(B b = new A().new B();),B會持有A物件的引用,所以鑑於這點,引出java中的記憶體洩漏問題。
2.區域性內部類
public class A { public C getB(){ class B extends C{ String s = "B"; } return new B(); } } class C{ String s; }
區域性內部類是定義在一個方法或者一個作用域裡面的類,它和成員內部類的區別在於區域性內部類的訪問僅限於方法內或者該作用域內。
3.匿名內部類
匿名內部類應該是平時我們編寫程式碼時用得最多的,在編寫事件監聽的程式碼時使用匿名內部類不但方便,而且使程式碼更加容易維護。
例如點選事件
view.setOnClickListener(new OnClickListener() { @Override public void onClick(View v) { } });
再例如子執行緒的runnable物件
4.靜態內部類
這個把前面的成員內部類拿過來,前面加個static就行了
public class A {
String s;
static class B{
}
}然後例項化的時候就不需要先例項化A,(B b = new A.B();),B也不會再持有A的物件引用,所以將內部類改為static能解決記憶體洩漏這個說法原因是在這。
看完上面 回到本文的出發點上來,內部類命名規則。
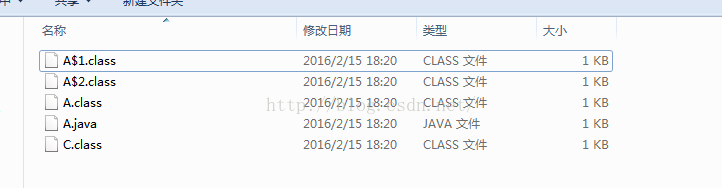
這麼記吧,所有內部類會在編譯的時候產生相對應的class檔案,非匿名內部類類名規則為 OutClass$InnerClass (外部類類名與內部類類名中間用$連線) 匿名內部類類名則為OutClass$數字(OutClass$1,OutClass$2,OutClass$3)
public class A {
C c = new C() {
String s = "i am c";
@Override
public void demo() {
}
};
C c2 = new C() {
String s = "i am c2";
@Override
public void demo() {
}
};
}
interface C {
public void demo();
}
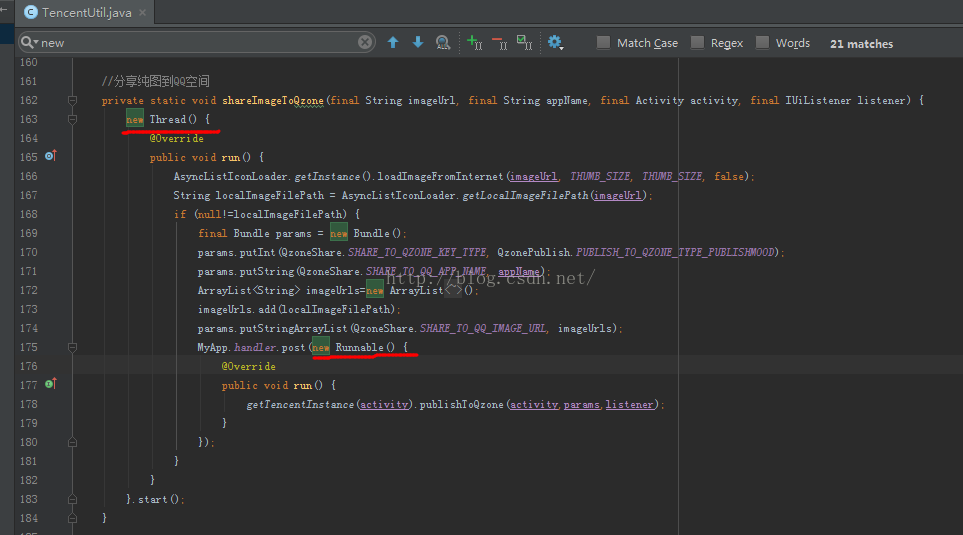
Thread物件是本類中第六個匿名內部類,runnable物件是這個thread物件中的第一個匿名內部類,OK TencentUtil$6$1.run代表的意思就是這個runnalbe中的run方法了。
===============================分割線===========================
最後說一個相關的問題。我們在用區域性內部類和匿名內部類時,都要求區域性變數為final,這是為啥呢?
想必這個問題也曾經困擾過很多人,在討論這個問題之前,先看下面這段程式碼:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
這段程式碼會被編譯成兩個class檔案:Test.class和Testx.class(x為正整數)。

根據上圖可知,test方法中的匿名內部類的名字被起為 Test$1。
上段程式碼中,如果把變數a和b前面的任一個final去掉,這段程式碼都編譯不過。我們先考慮這樣一個問題:
當test方法執行完畢之後,變數a的生命週期就結束了,而此時Thread物件的生命週期很可能還沒有結束,那麼在Thread的run方法中繼續訪問變數a就變成不可能了,但是又要實現這樣的效果,怎麼辦呢?Java採用了 複製 的手段來解決這個問題。將這段程式碼的位元組碼反編譯可以得到下面的內容:

我們看到在run方法中有一條指令:
bipush 10
這條指令表示將運算元10壓棧,表示使用的是一個本地區域性變數。這個過程是在編譯期間由編譯器預設進行,如果這個變數的值在編譯期間可以確定,則編譯器預設會在匿名內部類(區域性內部類)的常量池中新增一個內容相等的字面量或直接將相應的位元組碼嵌入到執行位元組碼中。這樣一來,匿名內部類使用的變數是另一個區域性變數,只不過值和方法中區域性變數的值相等,因此和方法中的區域性變數完全獨立開。
下面再看一個例子:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
反編譯得到:

我們看到匿名內部類Test$1的構造器含有兩個引數,一個是指向外部類物件的引用,一個是int型變數,很顯然,這裡是將變數test方法中的形參a以引數的形式傳進來對匿名內部類中的拷貝(變數a的拷貝)進行賦值初始化。
也就說如果區域性變數的值在編譯期間就可以確定,則直接在匿名內部裡面建立一個拷貝。如果區域性變數的值無法在編譯期間確定,則通過構造器傳參的方式來對拷貝進行初始化賦值。
從上面可以看出,在run方法中訪問的變數a根本就不是test方法中的區域性變數a。這樣一來就解決了前面所說的 生命週期不一致的問題。但是新的問題又來了,既然在run方法中訪問的變數a和test方法中的變數a不是同一個變數,當在run方法中改變變數a的值的話,會出現什麼情況?
對,會造成資料不一致性,這樣就達不到原本的意圖和要求。為了解決這個問題,java編譯器就限定必須將變數a限制為final變數,不允許對變數a進行更改(對於引用型別的變數,是不允許指向新的物件),這樣資料不一致性的問題就得以解決了。
到這裡,想必大家應該清楚為何 方法中的區域性變數和形參都必須用final進行限定了。
--------------------- 本文來自 高低調 的CSDN 部落格 ,全文地址請點選:https://blog.csdn.net/lazyer_dog/article/details/50669473?utm_source=copy