
JavaSE基礎複習---2---2018/9/28
目錄:
1、資料型別
2、變數
3、陣列
1.資料型別
談到java的資料型別,必須知道java是強型別語言。首先,每個變數有型別,每個表示式有型別,而且每種型別是嚴格定義的。其次,所有的數值傳遞,不管是直接的還是通過方法呼叫經由引數傳過去的都要先進行型別相容性的檢查。有些語言沒有自動強迫進行資料型別相容性的檢查或對衝突的型別進行轉換的機制。但是Java編譯器會對所有的表示式和引數進行型別相容性的檢查以保證型別是相容的。任何型別的不匹配都是錯誤的,在編譯器完成編譯以前,錯誤必須被改正。
java中的簡單資料型別有8個,代表簡單數值,而不是一個物件。同時這些簡單型別在任何平臺執行java程式時,都是固定位數,體現了java的可移植性。分別是以下八個,分為三大類: 整數型別:採用補碼的形式在記憶體中儲存。 位元組型(byte),佔8位,範圍:–28
字面量
字面量,意思就是一個值,比如23、19.8、a、false等。
首先整數字面量最好理解,他們都是基於十進位制的值。如果要使用8進位制,則在數值前面加上導0,比如023代表19。但是08將會沒有意義,因為八進位制中沒有8。如果要使用16進位制,則在數值前面加上0x或0X。整數字面量在java中是預設按照int進行處理,即在記憶體中佔用32位。可以通過在字面量後面加上l或者L來指定這是一個long型字面量。int型字面量賦值給long或者int當然沒有問題,但是賦值給byte或者short時,就要考慮是否越界。將int字面量賦值給byte時,會先對256取餘,再將餘數賦值給byte。顯然當字面量小於256可以正常賦值,但是大於256時,會出現錯誤。
浮點型字面量可以用3.44或者2.933e1(科學計數法)來表示。浮點型字面量預設是64位的double型,通過在字面量後面加上f或者F可以指定float型字面量。
布林型字面量最簡單,只有false或者true。注意0或者1不是布林型字面量,他們只能被賦給已定義的布林變數,或在布林的運算子表示式中使用。
對於字元型字面量,由於java採用Unicode碼錶示字元,可以對其進行類似整數的運算。一般用‘xxx’來表示xxx字元的字面量。對於一些不能被直接包括的字面量,有一些轉義符可以使用。
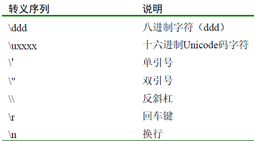
字串字面量,比如“this is a string”,用“”括起來。注意之前的c或者c++都是講字串當做是字元的陣列進行處理,java中不同,是當做一個物件來處理的。因此就有很多專用於java字串處理的類與對應的方法。常見的String,StringBuilder,StringBuffer(執行緒安全的StringBuilder)。
2.變數
典型定義變數的表示式:type identifier [ = value][,identifier [= value] ...] ;其中,type是變數型別,identifier是變數識別符號,[]內可以省略,可選是否初始化以及同時定義多個同類型變數。同時定義變數時也支援動態初始化,只要表示式是有效的。比如說: double c = Math.sqrt(a * a + b * b);
變數的作用域與生存期
Java中,有程式塊的概念。首先,程式塊是指兩個{}之間的程式碼塊,程式碼塊建立後也就產生了一個作用域。一般的程式語言都有區域性變數以及全域性變數的概念。Java中變數作用域主要取決於類與方法(類似於程式塊)。類暫不討論,此處先討論方法中變數的作用域。方法中定義的變數,只能在整個方法中使用,對外界不可見。方法中又巢狀程式塊時,程式塊內的變數對塊外不可見。同時,同一方法內,程式塊內與程式塊外變數不可同名。
變數在被定義後才是合法,可以使用的,也就是在記憶體中開闢了一塊空間給變數。同時,當變數所在的程式塊或者方法執行完畢後,變數也隨之銷燬,開闢的記憶體空間也就被回收。因此變數的生命期就是從其開始被定義到其所在程式塊執行結束。
型別轉換、強制型別轉換與自動轉換
自動型別轉換需要滿足兩個條件:1.這兩種型別相容(數值型別與char不相容)2.目的型別數的範圍大於源型別。當不滿足自動轉換時,便要進行強制型別轉換,會出現兩種情況:1.將int賦給byte,見上字面量中描述。2.將浮點賦給整型,此時會發生截斷,即小數部分被捨棄,只有整數部分被賦給整型變量了。
byte b; int i = 257; double d = 323.142; b = (byte) i; System.out.println("i and b " + i + " " + b);//i and b 257 1 i = (int) d; System.out.println("d and i " + d + " " + i);//d and I 323.142 323 b = (byte) d; System.out.println("d and b " + d + " " + b);//d and b 323.142 67
自動型別提升發生在表示式的計算中,看如下程式碼:
short a=23; byte b=22,c=41; int I = b*c/a;
當分析表示式時,Java自動提升各個byte型或short型的運算元到int型。這意味著子表示式b*c使用整數而不是位元組型來執行,儘管變數b和c都被指定為byte型,22*41中間表示式的結果是合法的。下面有一個特例:byte a=2;a = a*3;看起來沒有發生越界,但實際上a*3已經是int型別數值,直接賦給byte型的a肯定不對,因此編譯會報錯,解決辦法是:a=(byte)a*3;即加上強制型別轉換。自動型別提升的約定:所有的byte跟short會預設提升到int;表示式有long就全部預設到long;表示式有float就預設全部到float;表示式有double就全部預設到double。即:byte/short->int->long->float->double。
3.陣列
談到Java中的陣列,首先要分清其餘C或者C++中陣列的區別。Java中的陣列是類似於物件的一種實物。比如說int[ ] A;看上去是定義了一個名為A的int型陣列,但是在記憶體中編譯器實際上還沒有給該陣列分配記憶體空間。只有int[ ] A = new int[10];這樣,才在記憶體中開闢了10個int型別大小的儲存空間給A陣列。同時可以定義陣列的時候就對其初始化,並用A[x]的形式訪問陣列第x+1個元素,這點類似於c語言。
一個注意點時,Java會嚴格檢查我們是否訪問或儲存了陣列範圍以外的值。。Java的執行系統會檢查以確保所有的陣列下標都在正確的範圍以內(在這方面,Java與C/C++從根本上不同,C/C++不提供執行邊界檢查)。
多維陣列
多維陣列可以理解為是陣列的陣列。比如說一個二維陣列int[ ][ ] A= new int[3][4];就是定義了一個3個數組,每個陣列含有4個元素。理解為3*4,即3行4列,每行是一個數組,有3個數組。
同時,多維陣列允許我們指定每一個數組大小不同。比如int[ ][ ] A= new int[3][ ];然後分別對這三個陣列指定大小;A[0] = new int[1]; A[1] = new int[2]; A[2] = new int[3];這樣二維陣列A的三個子陣列A[0],A[1],A[2]大小分別為1,2,3,這樣就定義了一個下三角矩陣。多維陣列同樣也可以定義的時候就初始化,比如說:int[ ][ ] A = new int{{1},{1,2},{1,2,3}};這樣就給上面描述的下三角矩陣A陣列初始化了。
TIPS:java為何不支援指標?
眾所周知,c語言與C++全部都是支援指標操作的,即通過指標來直接訪問計算裝置中的記憶體。指標就是一個記憶體裝置的地址,通過其可以直接讀取或者修改該記憶體單元的值。而Java的特點就是通過在各種平臺上實現JVM,然後在JVM提供的執行環境下執行Java程式。如果說提供指標來直接訪問各種平臺的記憶體,那麼程式的執行將會脫離JVM的控制,這樣由JVM提供的跨平臺移植性,安全性均無法得到保證。但也無需擔心丟失了指標特性會對我們寫Java程式有多大的影響,只要是在JVM的執行環境下,我們就不需要使用指標,使用指標也不會帶來任何好處。