
Spark中的角色介紹
阿新 • • 發佈:2018-12-12
Spark 是基於記憶體計算的大資料平行計算框架。因為其基於記憶體計算,比Hadoop 中 MapReduce 計算框架具有更高的實時性,同時保證了高效容錯性和可伸縮性。從 2009 年誕生於 AMPLab 到現在已經成為 Apache 頂級開源專案,併成功應用於商業叢集中,學習 Spark 就需要了解其架構。
Spark 架構圖如下:
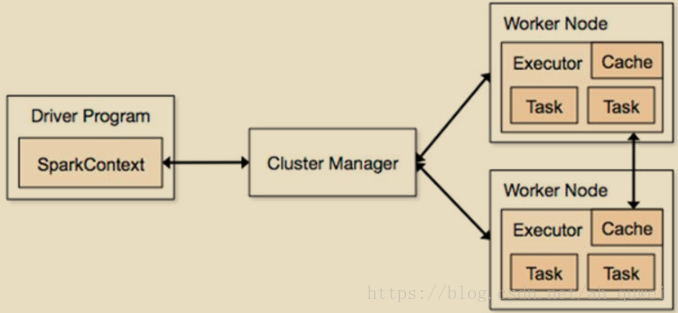
Spark架構使用了分散式計算中master-slave模型,master是叢集中含有master程序的節點,slave是叢集中含有worker程序的節點。
①Driver Program :運⾏main函式並且新建SparkContext的程式。
②Application:基於Spark的應用程式,包含了driver程式和叢集上的executor。
③Cluster Manager:指的是在叢集上獲取資源的外部服務。目前有三種類型 :
Standalone:spark原生的資源管理,由Master負責資源的分配
ApacheMesos:與hadoop MR相容性良好的一種資源排程框架
HadoopYarn: 主要是指Yarn中的ResourceManager
④Worker Node
⑤Executor:是在一個worker node上為某應⽤啟動的⼀個程序,該程序負責執行任務,並且負責將資料存在記憶體或者磁碟上。每個應⽤都有各自獨立的executor。
⑥Task :被送到某個executor上的工作單元。