
zookeeper系列之:zookeeper簡介淺談
一、zookeeper的定義
開啟zookeeper官網,赫然一行大字,寫著:“Apache ZooKeeper致力於開發和維護實現高度可靠的分散式協調的開源伺服器”。什麼意思呢?就是Apache ZooKeeper的目標是開發和維護開源伺服器,這伺服器是幹什麼的呢?是做分散式協調的。這伺服器的特點是什麼呢?是高度可靠的。關鍵就是高度可靠,不用去驗證,也不用懷疑zookeeper的高度可靠性,搜尋應用界的大佬solr和大資料服務界的大佬Hadoop就是使用zookeeper提供叢集管理。
二、什麼是zookeeper
ZooKeeper誕生於Yahoo,後轉入Apache孵化,最終孵化成Apache的頂級專案,是Hadoop和Hbase的重要元件。ZooKeeper是一種集中式服務,用於維護配置資訊、命名、提供分散式同步和提供組服務。
三、zookeeper的三中部署方式
1、獨立部署模式,即部署在單臺機器上的一個zookeeper服務,適用於學習、瞭解zookeeper基礎功能。
2、偽分佈模式,即部署在一臺機器上的多個(原則上大於3個)zookeeper服務,虛擬分散式的zookeeper叢集,適用於學習、開發和測試,不適用生產環境。
3、全分散式模式(複製模式),即在多臺機器上部署zookeeper服務,真正的叢集模式,適合於學習、開發和測試,可投入到生產環境中使用。
三、在什麼場景下使用zookeeper
1、叢集管理
①、節點監控:叢集環境下,有很多節點,節點可能因為網路故障連線不上,可能因為機器故障無法工作,要求保證叢集中的節點都能正常工作,就需要把異常的節點從叢集中遮蔽掉,這時使用zookeeper的短暫節點和watcher機制,可以很好的實現叢集的管理。
②、領導者選舉:叢集是多個節點(可把節點理解為機器)協同工作,這是需要一個把控全域性的領導者節點來接收外部請求、任務派發等,那麼,領導者節點如何產生?領導者節點出現故障怎麼處理?領導者選舉是zookeeper最優秀的功能之一,如果當前領導者節點出現故障,zookeeper可在很短的時間內選舉出新的領導者來接替故障領導者的工作。
2、配置管理
實際應用中,配置使應用變得靈活,但是在分散式應用下,需要到每一臺機上面修改配置,維護配置則複雜很多,基於這種場景,把配置放在zookeeper的znode中,分散式應用的機器到zookeeper的znode中讀取配置應用到系統中即可。此外,利用zookeeper的watcher機制,如果配置(znode)發生改變,zookeeper通知各個機器配置資訊已經被修改,各機器通過重新整理來獲取到最新的配置。
zookeeper還可以應用到很多場景,比如分散式鎖、資料的釋出和訂閱、佇列管理等等,此處就不一一介紹了。
四、zookeeper的效能
zookeeper旨在提供高效能,但是zookeeper的效能如何呢?zookeeper官網提供了一份效能測試結果圖,通過分析測試結果圖,可以大概瞭解zookeeper的效能,如下圖所示:
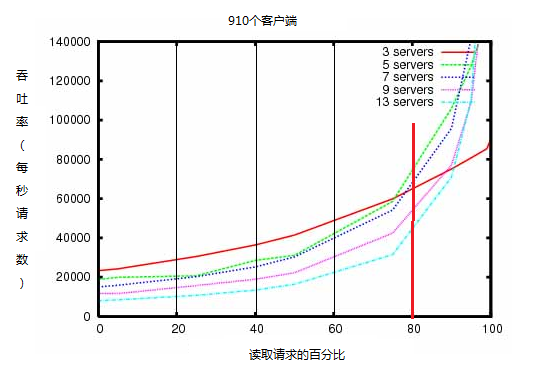
從測試結果圖得知測試分為5組,分別為3臺伺服器一組(暫且稱為A組)、5臺伺服器一組(暫且稱為B組)、7臺伺服器一組(暫且稱為C組)、9臺伺服器一組(暫且稱為D組)、13臺伺服器一組(暫且稱為E組),觀察到幾個現象:
①、讀取請求的百分比在60%之前,吞吐率為A>B>C>D>E。
②、讀取請求百分比到達80%偏左側一點,大概75%時,吞吐率開始發生變化,A組的吞吐率開始被其他組超越。
③、讀取請求百分比到達約95%時,吞吐率發生逆轉,約為E>D>C>B>A,讀取請求百分比趨近於瓶頸時,zookeeper叢集約龐大,滿足的吞吐率約高。
④、zookeeper叢集的吞吐率起點大約在10000左右,效能下限很高。
結論:
①、zookeeper小規模叢集也能提供較高的吞吐率,如果對吞吐率有較高要求時,可以通過新增zookeepe服務節點來滿足需求。
②、隨著zookeeper服務節點的增加,zookeeper的效能呈指數上升。
這篇博文是zookeeper系列的第一篇,對zookeeper做一個簡單的介紹,關於zookeeper的更多內容和實際操作,會在後續博文中詳述。
由於能力有限,如有不足和錯誤之處,還望不吝指出!