
一起學python-opencv十四(影象閾值化,影象縮放)
影象閾值化也可以叫做二值化,其實我們前面已經用過了很多次的cv2.threshold,另外就是cv2.inRange,這個主要用HSV顏色空間來分離出某一種顏色的區域。前面我們只用了幾種閾值化的型別,那麼這篇文章的開頭,就讓我們來認識一下其它的閾值化型別。

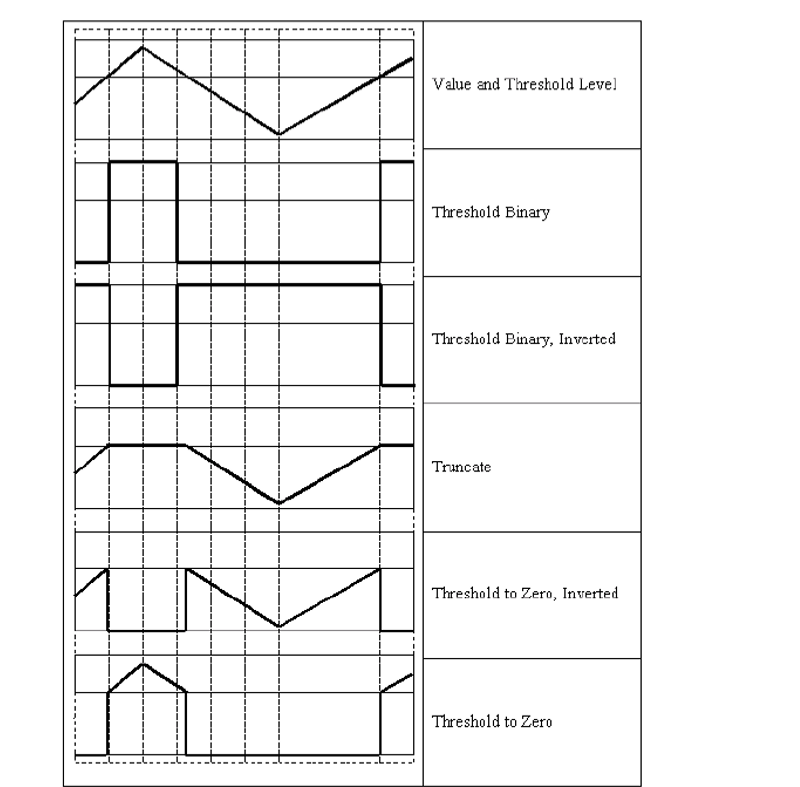
我覺得看圖還是非常直觀的,TRUNC就是設定一個閾值,高於這個閾值的話,就把值改為閾值這個值,當然這個maxVal就會直接被無視了。如果低於的話,就保持原來的值,TOZERO就是如果值低於閾值就變為0,高的保持,TOZERO_INV就是說如果值高於閾值變為0,低於保持,maxVal都是會被無視,但是這個引數肯定還是需要填的,不然就缺引數了。畢竟只有dst一個是用中括號括起來的,也就是隻有dst是可選的。而且注意返回的是一個元組,需要用retval,dst分別來接收,retVal是閾值。
我們來分別試一下:

效果:

前面說的方法都是從cv2.threshold函式外面獲得的,cv2.threshold還有根據直方圖自動計算出閾值的兩種方法:第一種是cv2.THRESH_OTSU。參考了https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_imgproc/py_thresholding/py_thresholding.html
在全域性閾值處理中,我們使用主觀值作為閾值,當然我們也可以計算一下影象的平均值或者中位數等其它統計特徵然後作為輸入。不過就有一個問題,我們如何知道我們選擇的值是好還是不好?答案是,試湊法,一個一個去試,然後根據結果的好壞評判值得好壞。但考慮雙峰影象
為此,使用了我們的cv2.threshold()函式,但傳遞了一個額外的標誌cv2.THRESH_OTSU。對於閾值,只需傳遞零。然後演算法找到最佳閾值並返回輸出,retVal。如果未使用Otsu閾值,則retVal與您使用的閾相同。當然上面還不是原理,原理在下面。OTSU演算法也叫大津法或最大類間方差法。

q1(t)和q2(t)分別是直方圖累積數,P是直方圖灰度值對應的數量,μ是被閾值分成的兩個區間類的灰度值的期望,σ分別是兩個區間灰度的方差,這樣算的叫做最小加權類內方差,這個是官網給的數學原理。方差是表徵資料資訊量大小或者說資料分散程度的一個量,方差越大,資料資訊量越大,資料越分散。最小化類內方差這種就是實現了分成的兩個類的灰度的分散度最小,也就是比較接近了。我在網上還搜到了另一種計算方法。參考了https://www.cnblogs.com/xiaomanon/p/4110006.html


到目前為止和官方的做法還是一致的,不過下面就稍微不一樣了。

這個等式其實蠻重要的。


有點不知道它是怎麼得出等式的,我這裡計算的是隻有當b=a=c的時候它們才會相等。可能是我的計算過程有疏漏或者是少考慮了什麼。

假如那個等式是對的,那麼其實最大類內方差的滿足也就意味著滿足了最小類內方差,因為它們的和σT的平方是不變的和k無關。

上面就是大概原理,當然其中還有一個問題沒有解決,希望有大神在評論區指導一下我了。
我們來看一下程式碼:
我找了一張圖片:


這個比較適合,因為有兩個波峰。還有一個只有一個波峰的。

先來試一試單峰的。
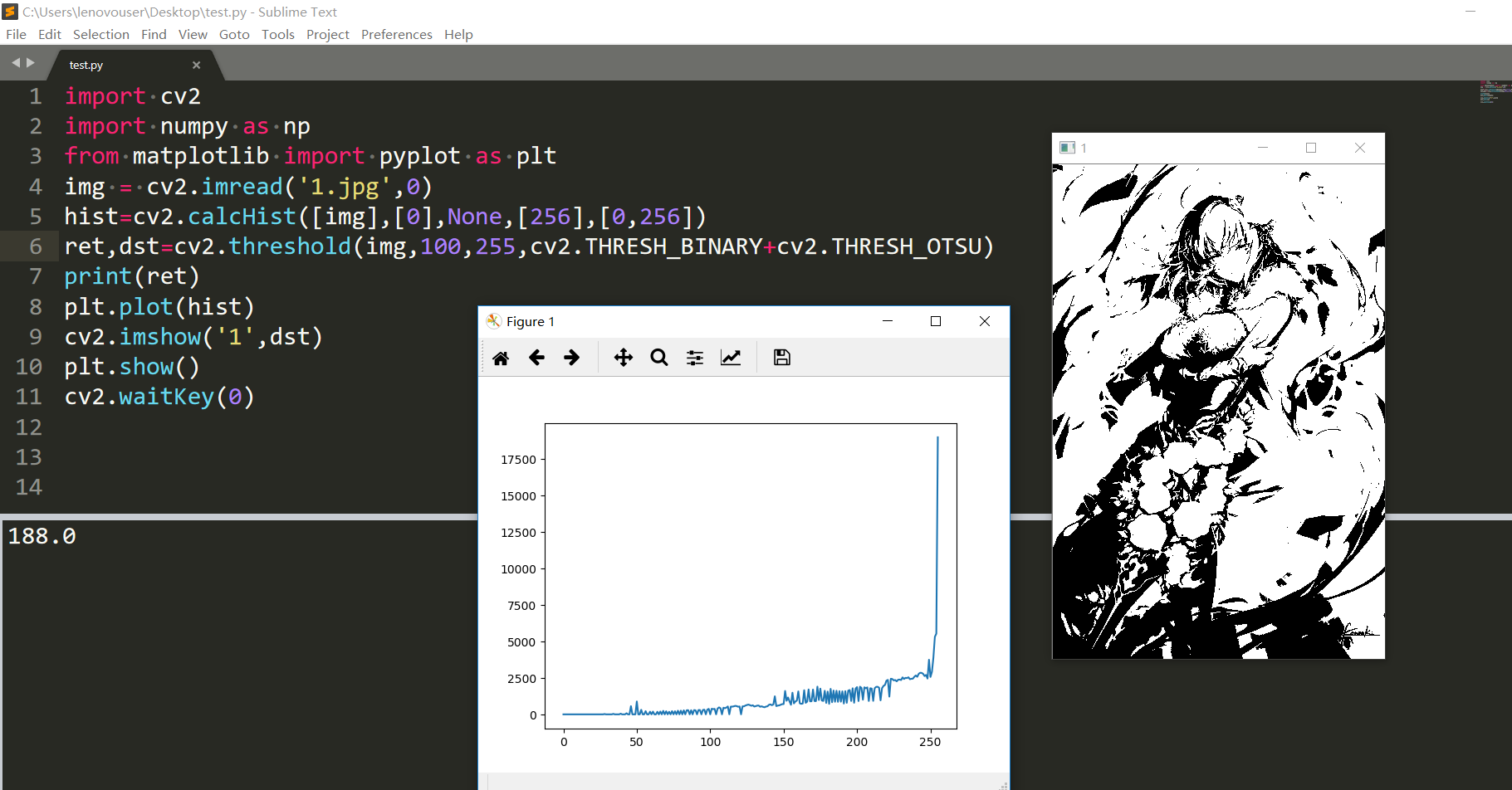
效果不怎麼樣,因為其實我們這張圖都是偏白的,看到ret返回的是188而不是我們設定的100。
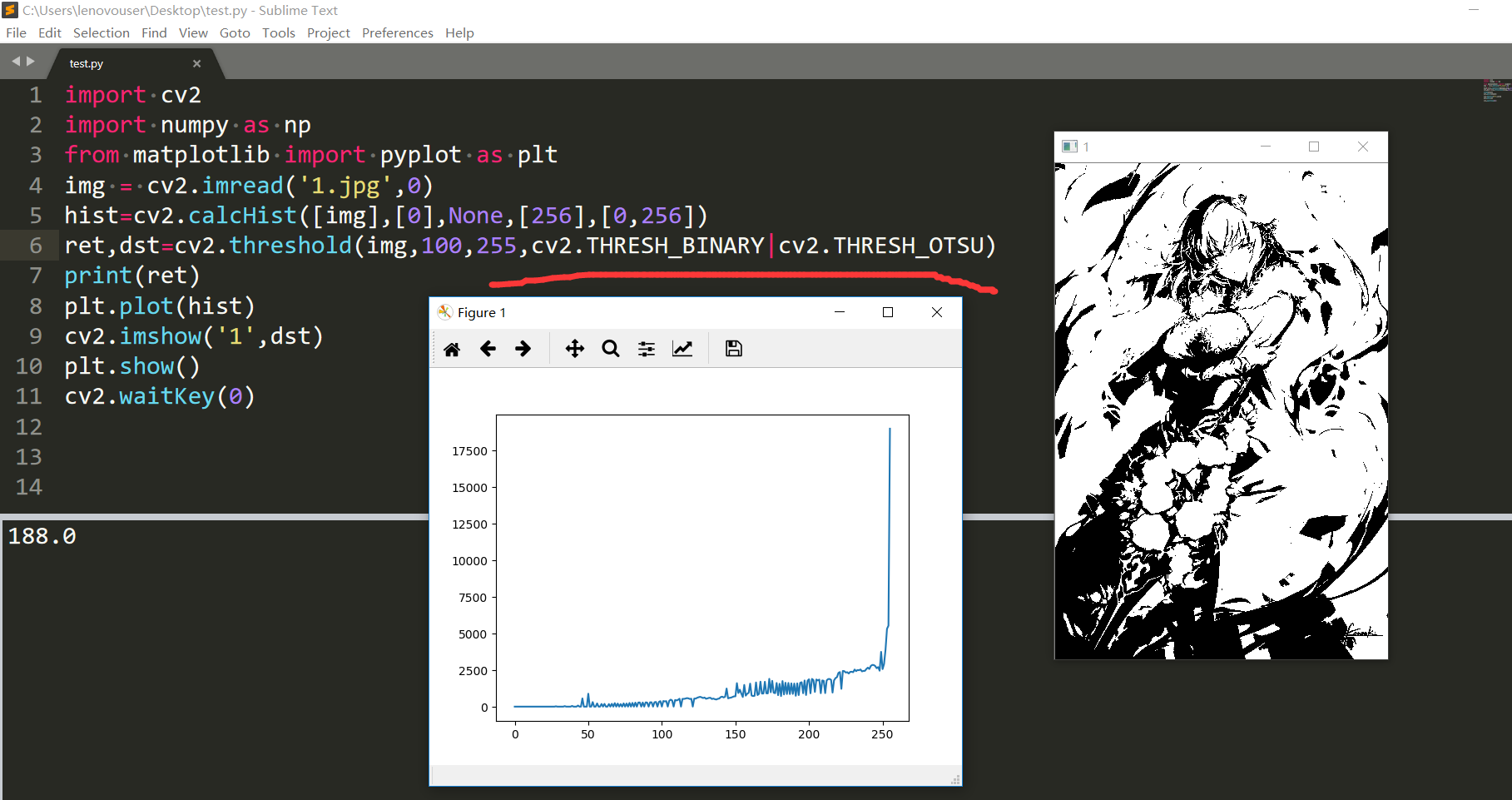
threshold輸入二值化方式這個地方有點像泛洪填充的flags引數,應該有好幾位,閾值選取方式和二值化方法應該是存在不同的位的,所以這裡加和或操作都是可以的。

還不錯,把黑貞的白貞的區域分得還是可以的。第二種方法是cv2.THRESH_TRIANGLE。參考https://blog.csdn.net/jia20003/article/details/53954092

上圖的閾值也就是在160左右了。


原理挺簡單的,但是更基本的數學原理沒有解釋清楚,就是到底是根據什麼數學方法得到的這個閾值呢?我們都來試驗一下,這次我用的是
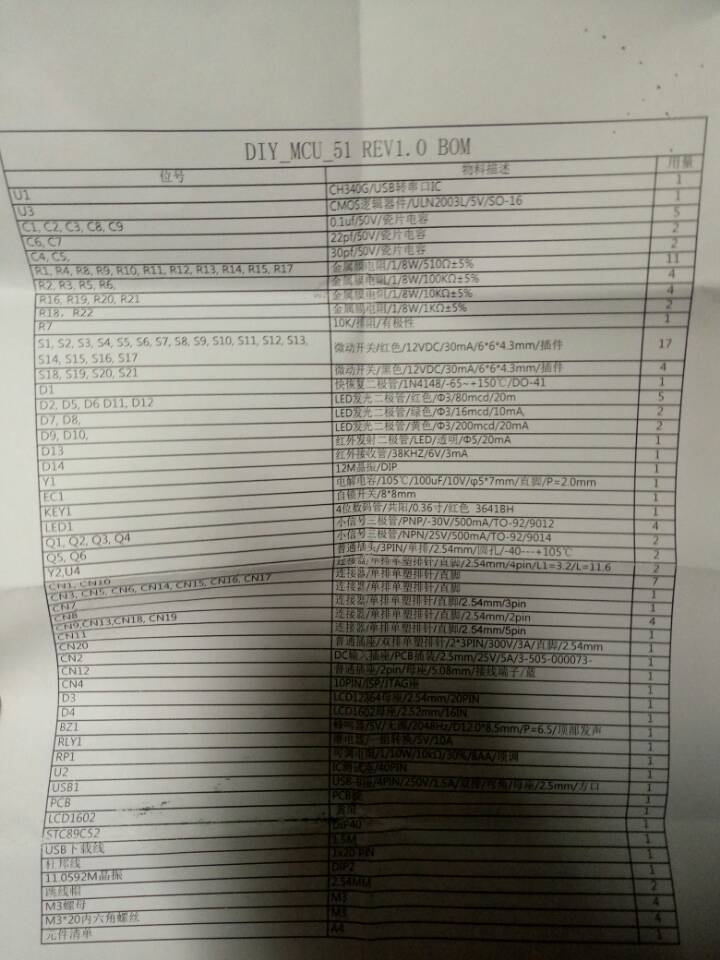

閾值是149,效果不是很好。主要還是照明太不均勻了。

那麼otsu呢?閾值時111效果也不是很好。
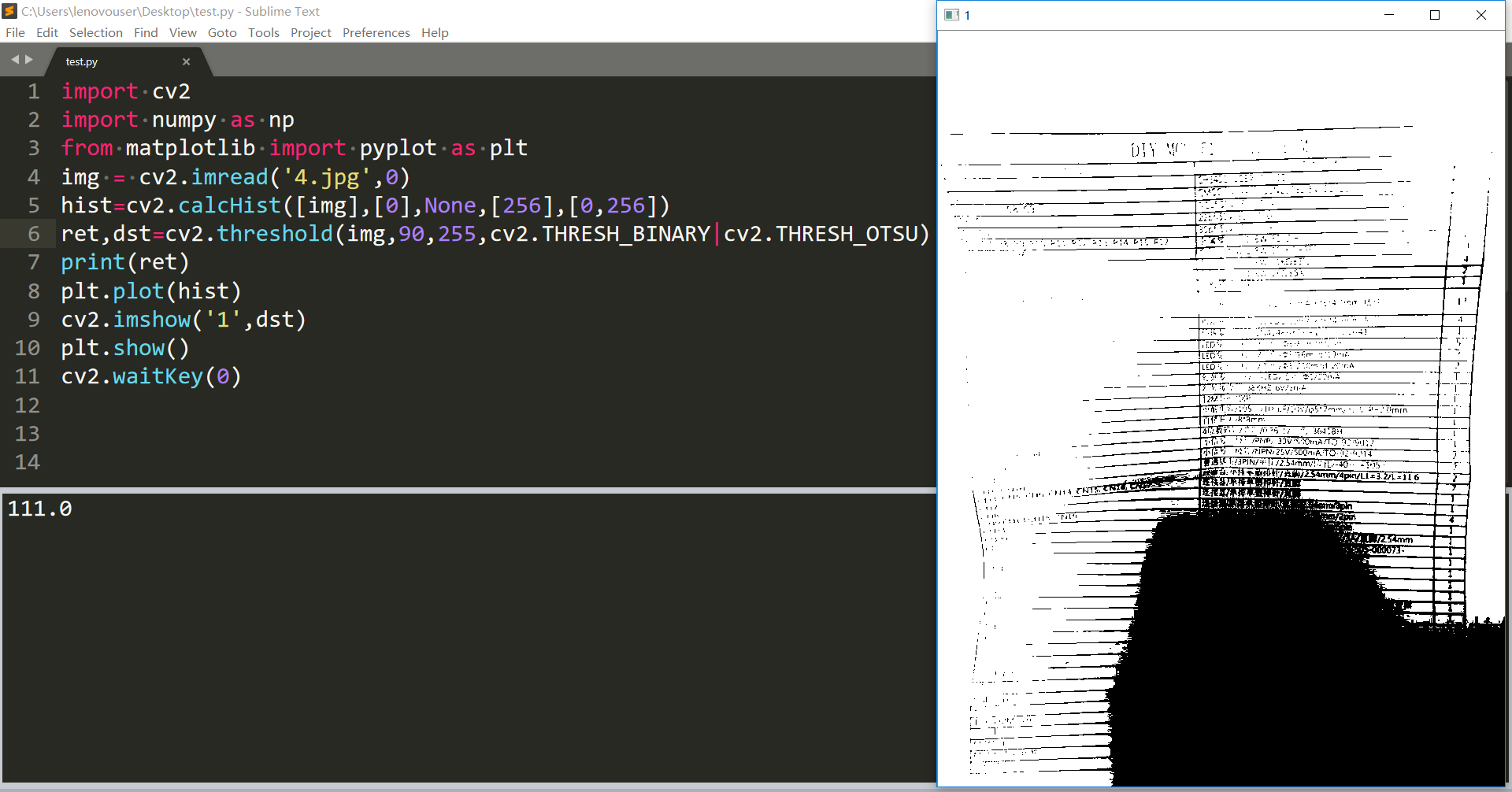
我用灰度值的期望作為閾值。
效果也不是很好。中值也不行。

這個究其原因還是照明不均引起的。這個時候就需要我們的自適應閾值化出場了。自適應閾值有點像CLAHE,其實也是用一個一個小的矩形在影象上滑動,在每個小矩形內進行閾值化操作,不過它不是對影象直方圖操作的,而是直接對影象操作的。
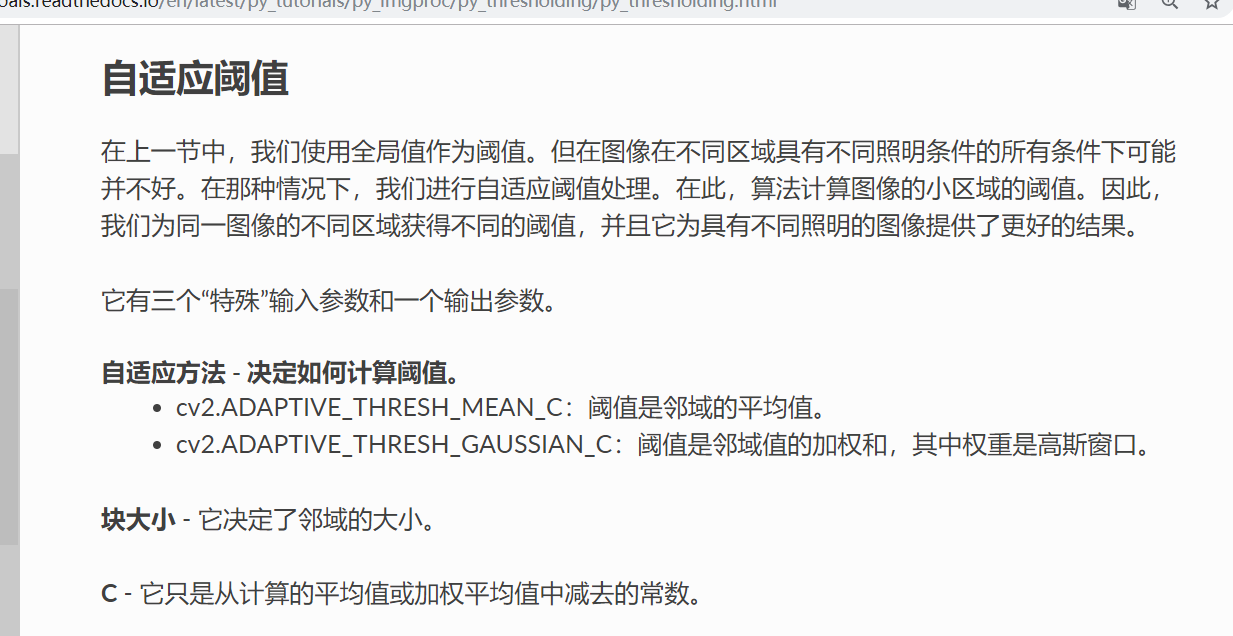
cv2.ADAPTIVE_THRESH_GAUSSIAN_C就是卷積核是高斯核而已。C是一個偏置量,閾值根據前面計算出來以後,還會減去這個值。塊大小就是卷積核的階數,必須是奇數。
自適應二值化的函式就是cv2.adaptiveThreshold。這個返回值是有一個dst,不返回閾值,因為返回閾值會有很多個,可能比較麻煩就不返回了。
先用一下閾值採用均值的方法:


問題在於有些空白的地方也給顯示黑的,這個是因為我的C是0,所以空白區域肯定還是會有區域要黑的。如果我把C變大一點,也就是說閾值減小,也就是說降低了成為255的門檻,本身那些白色區域的值都很接近,只是因為光照不均略有不同,很容易讓所有的都顯示為白色。

我把閾值降低7,就有了不錯的效果了。

只不過右邊的一些黑點沒有去掉。我們再來試一試高斯核。
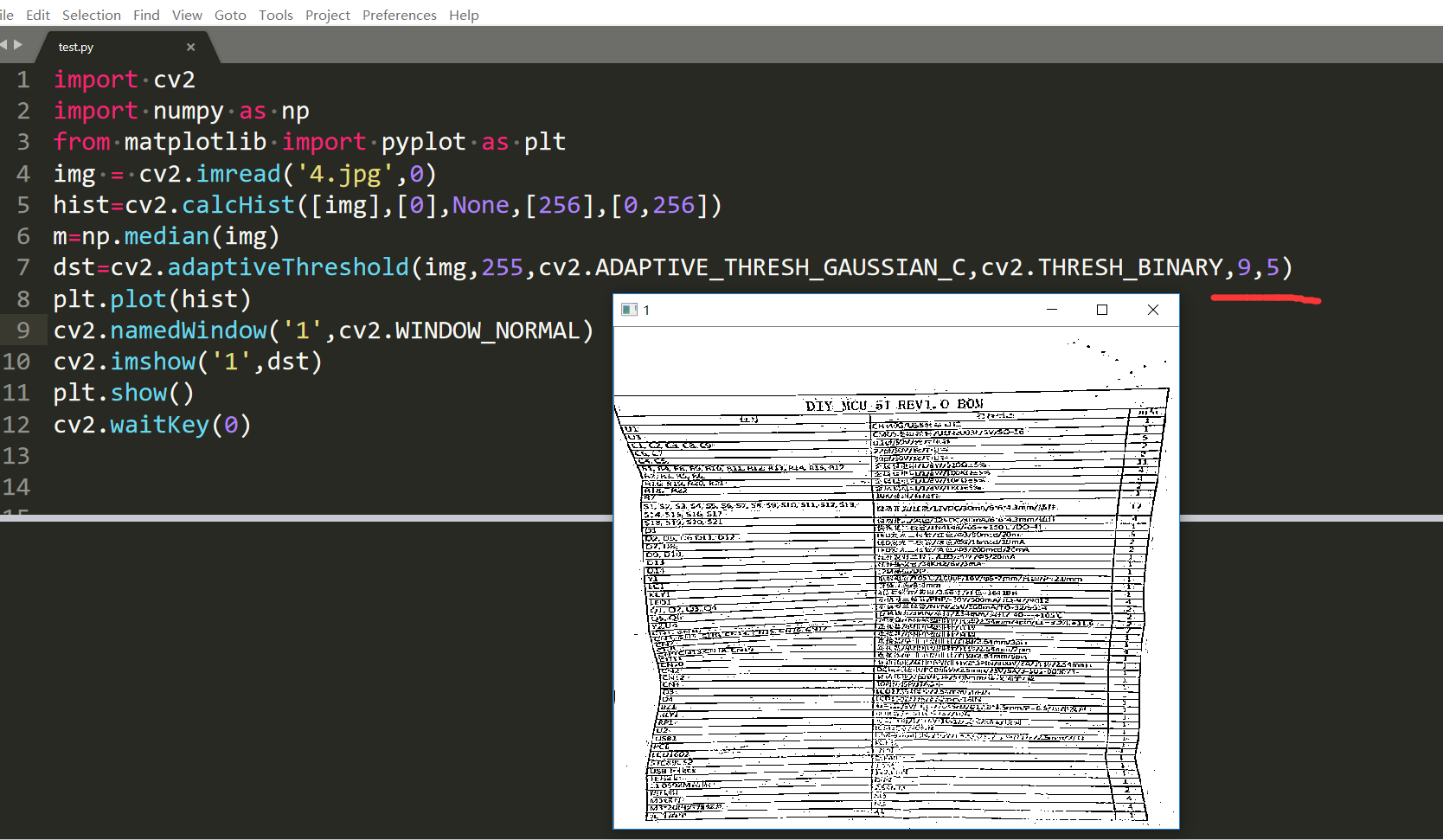
試了試C是5的效果比較好一些。我們還有一種處理空白的方法就是自己去處理。

加一個均值核標準差的判斷,這兩個閾值是自己選的。
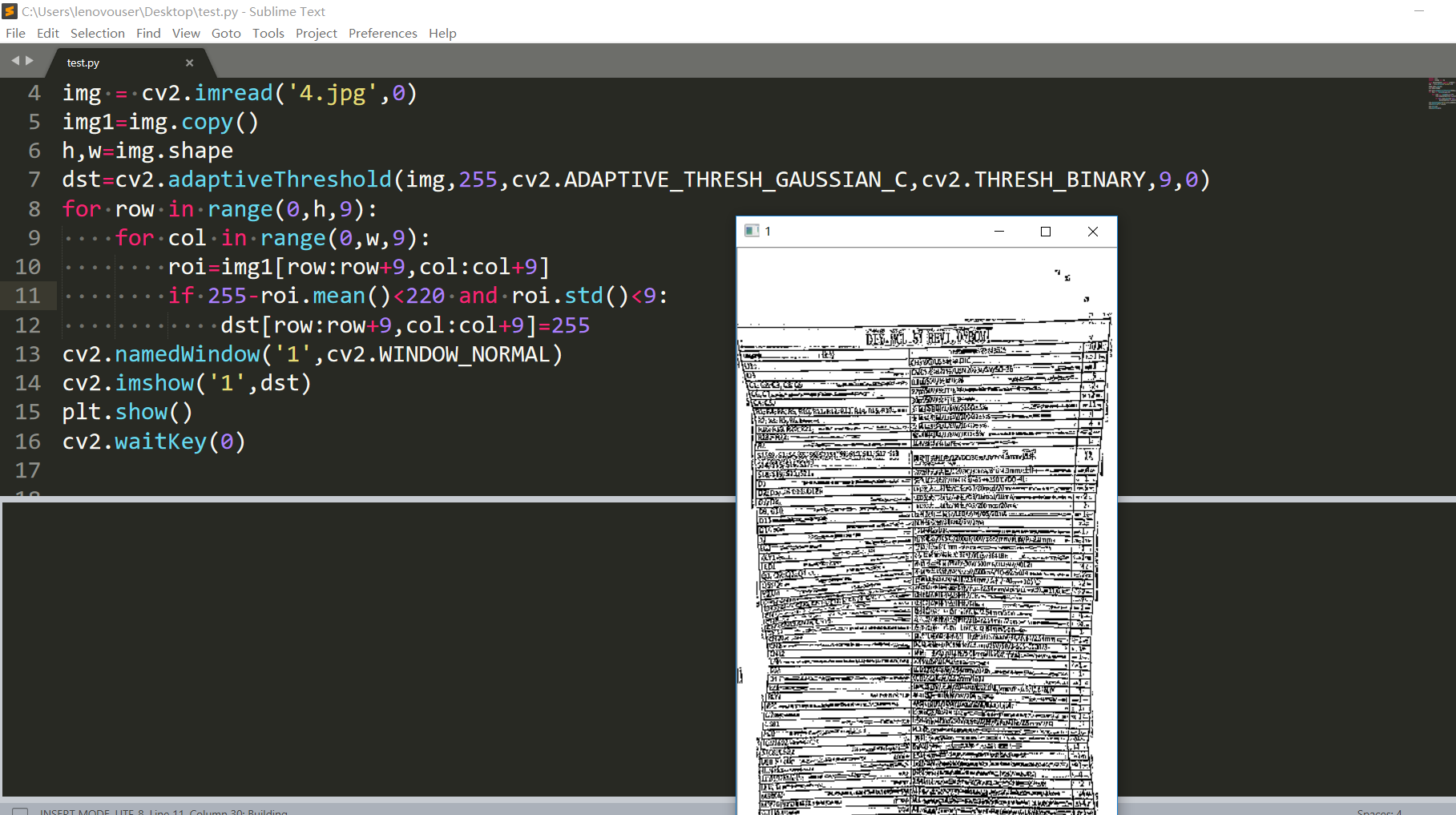
效果還算不錯。所以其實我們還可以分塊處理:
不過結果不算好。

還有

效果也不算很好。這樣其實和自適應的方法就是少了一個C,這個C還是比較有用的。
影象縮放
參考了https://blog.csdn.net/william_hehe/article/details/79604082
https://blog.csdn.net/qq78442761/article/details/61425664
https://blog.csdn.net/chaipp0607/article/details/60780472
在畫圖中我們就曾經體會過影象的縮放。我們現在來看一看opencv如何實現。
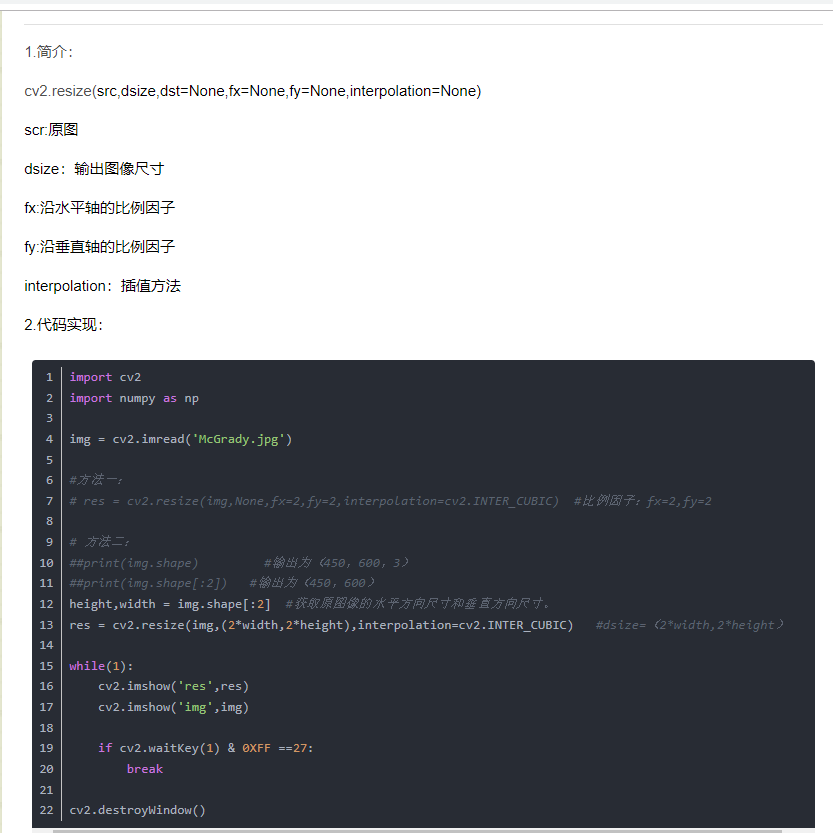


縮小的原理:

那麼如果不能整除該怎麼辦呢?比如16%3!=0,我的猜想是先進行補全到可以整除,例如16就補到18,然後再進行區平均值的操作,怎麼補全呢?就是用插值咯。放大還是比較好理解的,就是直接插值咯。

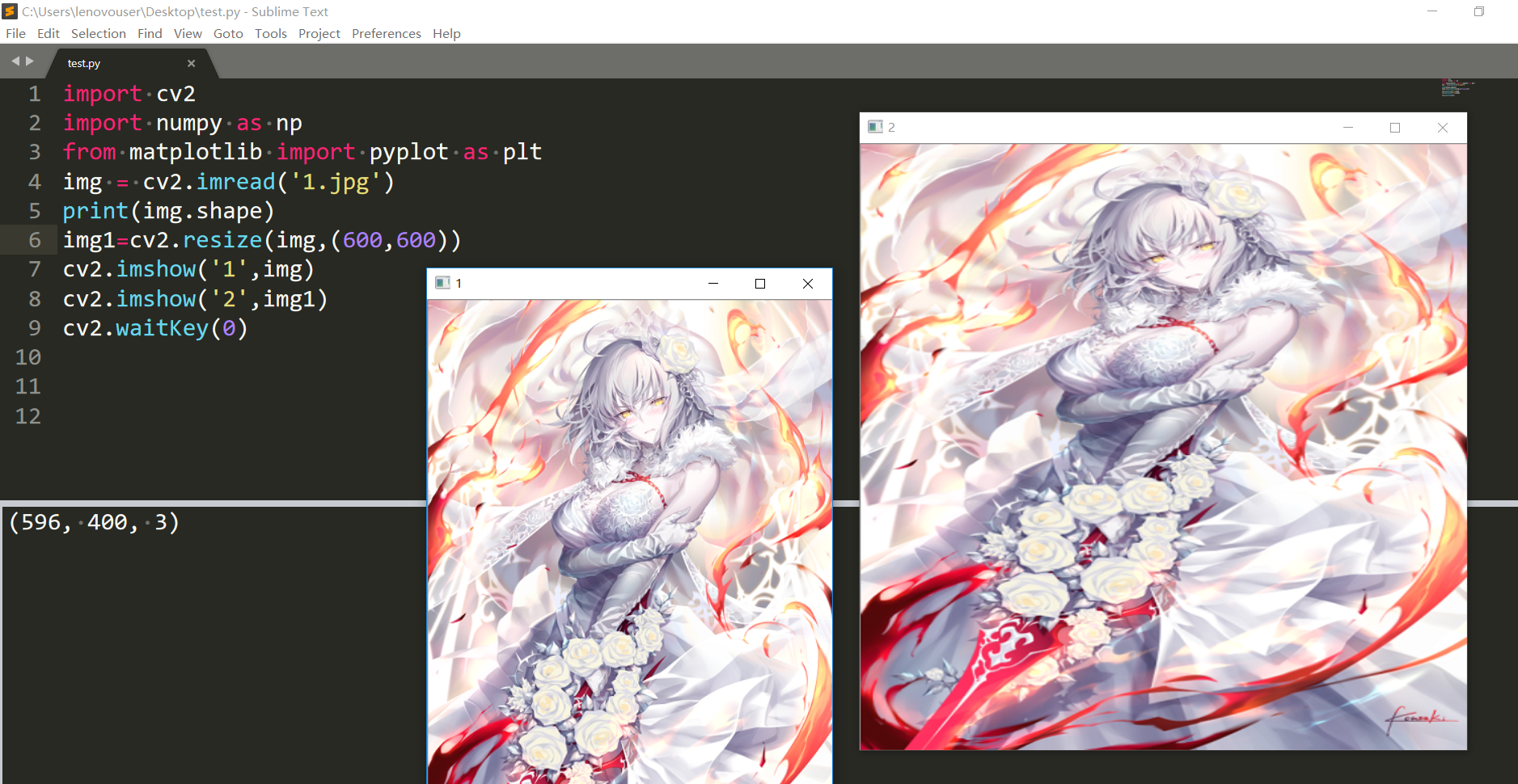

應該是我這個圖片選的比較特別,所以看不出來插值方式的區別。
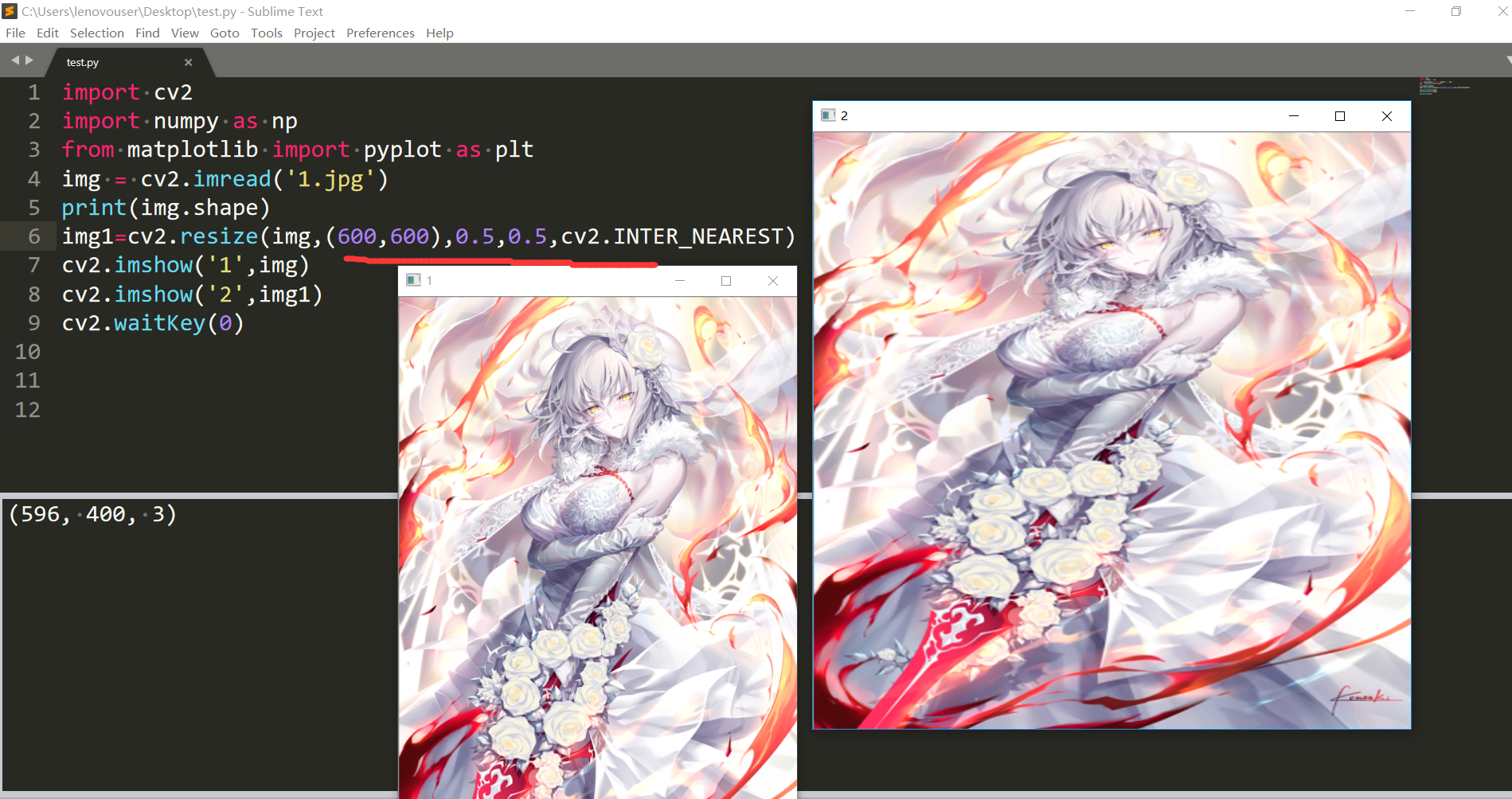
填了dsize就不要填fx,fy了,當然dszie必須得是非0才行。
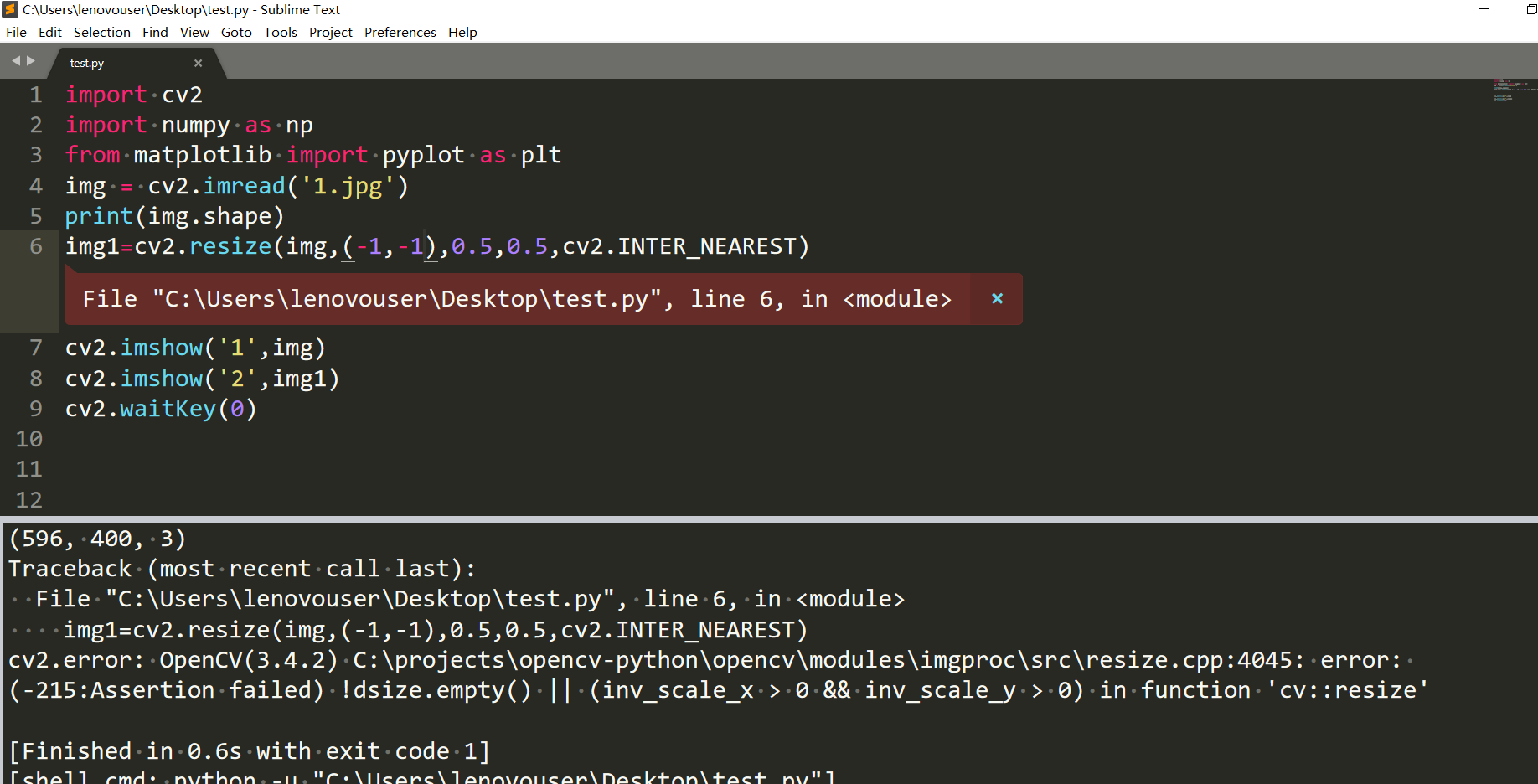
但是有要求都大於0,我是有點懵比了。

暫時不知道怎麼用fx,fy來縮放影象。不過我們可以計算,直接給dsize。