
決策樹演算法簡介及其MATLAB實現程式碼
目錄
決策樹原理概述
-
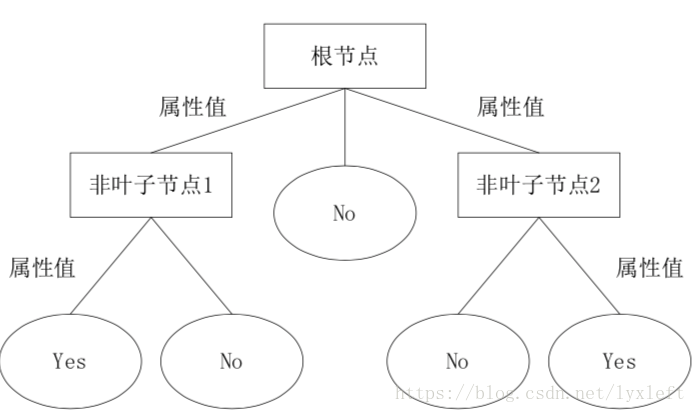
決策樹通過把樣本例項從根節點排列到某個葉子節點來對其進行分類。樹上的每個非葉子節點代表對一個屬性取值的測試, 其分支就代表測試的每個結果(yes no表示正類、負類);而樹上的每個葉子節點均代表一個分類的類別,樹的最高層節點是根節點。當所有葉子節點給出的分類結果都一樣時,就結束生長,即已經可以判定樣本的類別。
-
根節點並沒有什麼實際的意義。
-
簡單地說,決策樹就是一個類似流程圖的樹形結構,採用自頂向下的遞迴方式,從樹的根節點開始,在它的內部節點上進行屬性值的測試比較,然後按照給定例項的屬性值確定對應的分支,最後在決策樹的葉子節點得到結論。這個過程在以新的節點為根的子樹上重複。直到所有新節點給出的結果一致或足以判斷分類
(我們可以設計一些規則來決定)。

上圖是一個區分動物型別的例子。
-
決策樹其實很好理解。舉個例子,它就像我們玩的猜謎底遊戲。B向A提問,每次可以問不同的問題,而A只能回答是或不是,對或不對。通過多次發問,B越來越接近正確答案。這裡,每個問題實際上就是非葉子節點的屬性測試,是或者不是就是給出測試結果yes or no。如果一個謎底符合你所有問題(屬性),得到答案一致,那麼你一定能肯定這個謎底是什麼。
決策樹的經典演算法:ID3演算法
原則上講,對給定的資料集,可構造的決策樹數目達到指數級。但是由於算力優先,我們只能在一定條件下構造出具有一定準確率的較優的決策樹。這些演算法通常都是採用貪心策略,在選擇劃分資料的屬性時,採取一系列區域性最優決策來構造決策樹。
Hunt演算法是許多決策樹演算法的基礎,包括ID3、C4.5和CART。

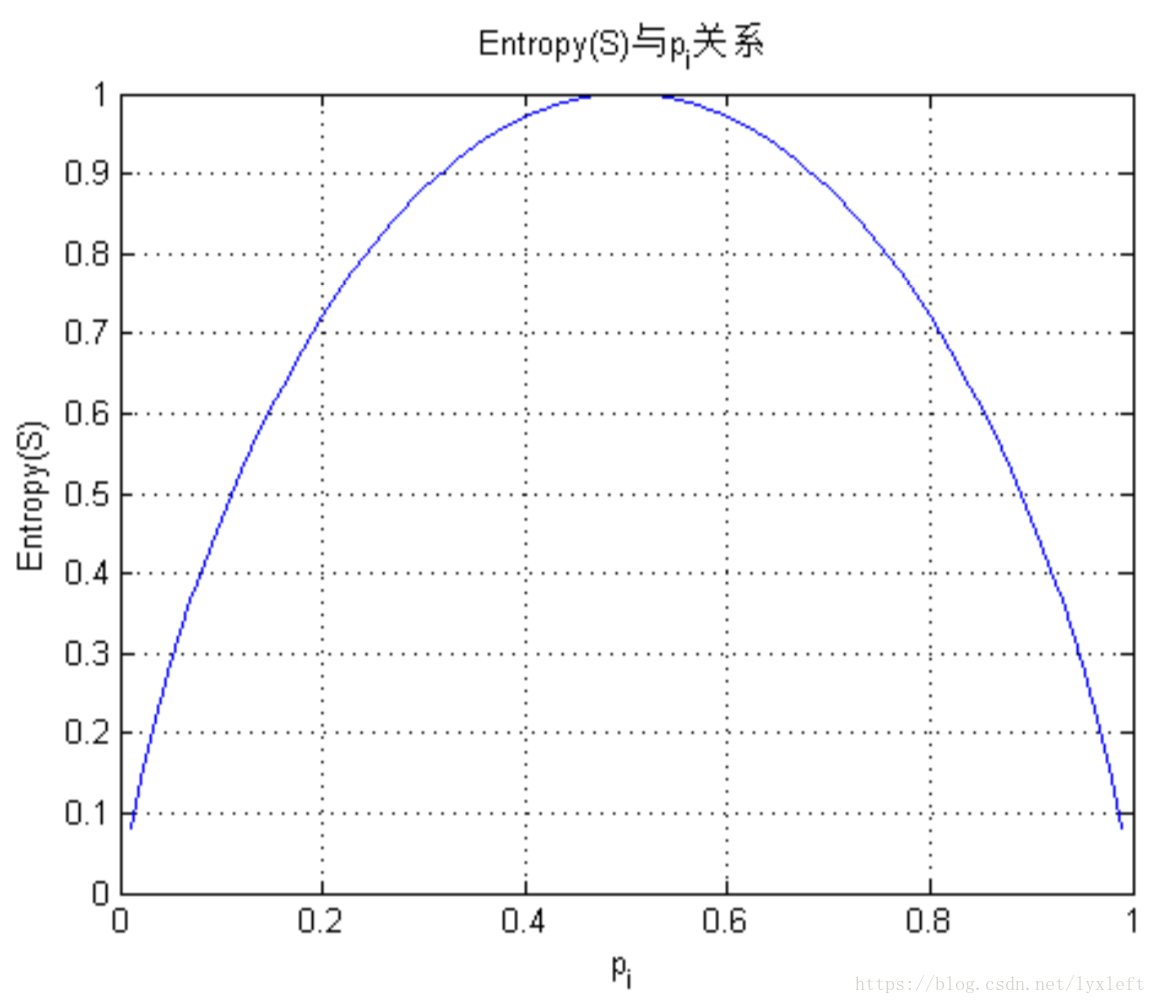

資訊增益越大代表這個屬性中包含的資訊量越多。因為它的定義式實際上是熵的變化。
改進:C4.5演算法
針對ID3演算法中可能存在的問題,學者提出了一些改進。

針對上述兩種演算法,具體解釋和舉例可以參考:《資料探勘系列(6)決策樹分類演算法》,此處不再贅述。
決策樹的優缺點
優點:
– 決策樹易於理解和實現。 人們在通過解釋後都有能力去理解決策樹所表達的意義。
– 對於決策樹,資料的準備往往是簡單或者是不必要的。其他的技術往往要求先把資料歸一化,比如去掉多餘的 或者空白的屬性。
– 能夠同時處理資料型和常規型屬性。 其他的技術往往要求資料屬性的單一。
– 是一個白盒模型。如果給定一個觀察的模型,那麼根據所產生的決策樹很容易推出相應的邏輯表示式。
缺點:
– 對於各類別樣本數量不一致的資料,在決策樹當中資訊增益的結果偏向於那些具有更多數值的特徵。
– 決策樹內部節點的判別具有明確性,這種明確性可能會帶來誤導。
MATLAB實現決策樹分類演算法
%% I. 清空環境變數
clear all
clc
warning off
%% II. 匯入資料
load data.mat
%%
% 1. 隨機產生訓練集/測試集
a = randperm(569);
Train = data(a(1:500),:);
Test = data(a(501:end),:);
%%
% 2. 訓練資料
P_train = Train(:,3:end);
T_train = Train(:,2);
%%
% 3. 測試資料
P_test = Test(:,3:end);
T_test = Test(:,2);
%% III. 建立決策樹分類器
ctree = ClassificationTree.fit(P_train,T_train);
%%
% 1. 檢視決策樹檢視
view(ctree);
view(ctree,'mode','graph');
%% IV. 模擬測試
T_sim = predict(ctree,P_test);
%% V. 結果分析
count_B = length(find(T_train == 1));
count_M = length(find(T_train == 2));
rate_B = count_B / 500;
rate_M = count_M / 500;
total_B = length(find(data(:,2) == 1));
total_M = length(find(data(:,2) == 2));
number_B = length(find(T_test == 1));
number_M = length(find(T_test == 2));
number_B_sim = length(find(T_sim == 1 & T_test == 1));
number_M_sim = length(find(T_sim == 2 & T_test == 2));
disp(['病例總數:' num2str(569)...
' 良性:' num2str(total_B)...
' 惡性:' num2str(total_M)]);
disp(['訓練集病例總數:' num2str(500)...
' 良性:' num2str(count_B)...
' 惡性:' num2str(count_M)]);
disp(['測試集病例總數:' num2str(69)...
' 良性:' num2str(number_B)...
' 惡性:' num2str(number_M)]);
disp(['良性乳腺腫瘤確診:' num2str(number_B_sim)...
' 誤診:' num2str(number_B - number_B_sim)...
' 確診率p1=' num2str(number_B_sim/number_B*100) '%']);
disp(['惡性乳腺腫瘤確診:' num2str(number_M_sim)...
' 誤診:' num2str(number_M - number_M_sim)...
' 確診率p2=' num2str(number_M_sim/number_M*100) '%']);
%% VI. 葉子節點含有的最小樣本數對決策樹效能的影響
leafs = logspace(1,2,10);
N = numel(leafs);
err = zeros(N,1);
for n = 1:N
t = ClassificationTree.fit(P_train,T_train,'crossval','on','minleaf',leafs(n));
err(n) = kfoldLoss(t);
end
plot(leafs,err);
xlabel('葉子節點含有的最小樣本數');
ylabel('交叉驗證誤差');
title('葉子節點含有的最小樣本數對決策樹效能的影響')
%% VII. 設定minleaf為13,產生優化決策樹
OptimalTree = ClassificationTree.fit(P_train,T_train,'minleaf',13);
view(OptimalTree,'mode','graph')
%%
% 1. 計算優化後決策樹的重取樣誤差和交叉驗證誤差
resubOpt = resubLoss(OptimalTree)
lossOpt = kfoldLoss(crossval(OptimalTree))
%%
% 2. 計算優化前決策樹的重取樣誤差和交叉驗證誤差
resubDefault = resubLoss(ctree)
lossDefault = kfoldLoss(crossval(ctree))
%% VIII. 剪枝
[~,~,~,bestlevel] = cvLoss(ctree,'subtrees','all','treesize','min')
cptree = prune(ctree,'Level',bestlevel);
view(cptree,'mode','graph')
%%
% 1. 計算剪枝後決策樹的重取樣誤差和交叉驗證誤差
resubPrune = resubLoss(cptree)
lossPrune = kfoldLoss(crossval(cptree))