【python與機器學習入門1】KNN(k近鄰)演算法2 手寫識別系統
阿新 • • 發佈:2018-12-12
參考部落格:超詳細的機器學習python入門knn乾貨 (po主Jack-Cui
參考書籍:《機器學習實戰》——第二章
KNN入門第二彈——手寫識別系統demo
——《機器學習實戰》第二章2.3 手寫識別系統
這應該是機器學習裡很經典的一個例子了,做法有很多,資料集也很多,研一時選修的計算機視覺的大作業也是這個。這篇部落格從KNN角度進行分類。KNN詳細內容見前篇
目錄
1 資料集
資料集連結: https://pan.baidu.com/s/1kwBNb3o1SV_b-_Rd4_GFUQ 密碼: qhff
每個數字是一個txt檔案,包含32x32的二進位制
trainingDigits 訓練集 總計大概2000張圖的txt,每個數字大概200個樣本
testDigits 測試集 大概900多張圖的txt
檔名格式為 數字_樣本序
2 資料處理
單個檔案是32x32,需要轉成1x1024
'''只轉單個txt''' def img2vector(path): img_vec = np.zeros([1,1024]) file = open(path) readlines = file.readlines() index = 0 '''按行讀取''' for rl in readlines: rl_strip = rl.strip() '''每行按位讀取存入相應位置''' for i in range(32): img_vec[0,index*32+i] = rl[i] index += 1 return img_vec
3 資料夾遍歷
因為訓練集和測試集都是一個資料夾,需要遍歷資料夾來準備好訓練集矩陣和測試集矩陣
遍歷資料夾用到了os包的listdir()
os.listdir(path) 返回路徑下的所有資料夾和檔名list
'''讀取資料''' def createDataSet(filepath): filenames = os.listdir(filepath) m = len(filenames) dataSet = np.zeros([m, 1024]) lables = [] index = 0 for filename in filenames: img_vec = img2vector(filepath + '/' + filename) dataSet[index, :] = img_vec # print int(filename.split('_')[0]) '''檔名提取第一位作為類別''' lables.append(int(filename.split('_')[0])) index += 1 return dataSet,lables if __name__ == "__main__": trainpath = "trainingDigits" testpath = "testDigits" k = 4 '''獲取訓練資料和測試資料''' trainSet,train_y = createDataSet(trainpath) testSet,test_y = createDataSet(testpath)
4 構建分類器和測試(附完整程式碼)
#!/usr/bin/env python
#_*_coding:utf-8_*_
import numpy as np
import operator
import os
'''只轉單個txt'''
def img2vector(path):
img_vec = np.zeros([1,1024])
file = open(path)
readlines = file.readlines()
#print readlines
index = 0
for rl in readlines:
rl_strip = rl.strip()
for i in range(32):
img_vec[0,index*32+i] = rl[i]
#print img_vec[0,index*32:(index+1)*32]
index += 1
return img_vec
'''讀取資料'''
def createDataSet(filepath):
filenames = os.listdir(filepath)
m = len(filenames)
dataSet = np.zeros([m, 1024])
lables = []
index = 0
for filename in filenames:
img_vec = img2vector(filepath + '/' + filename)
dataSet[index, :] = img_vec
# print int(filename.split('_')[0])
'''檔名提取第一位作為類別'''
lables.append(int(filename.split('_')[0]))
index += 1
return dataSet,lables
'''構建分類器並進行測試'''
def handWritingTest(trainSet,train_y,testSet,test_y,k):
test_num = testSet.shape[0]
countWrong = 0;
for i in range(test_num):
classResult = classify0(testSet[i,:],trainSet,train_y,k)
if(test_y[i] != classResult):
countWrong += 1
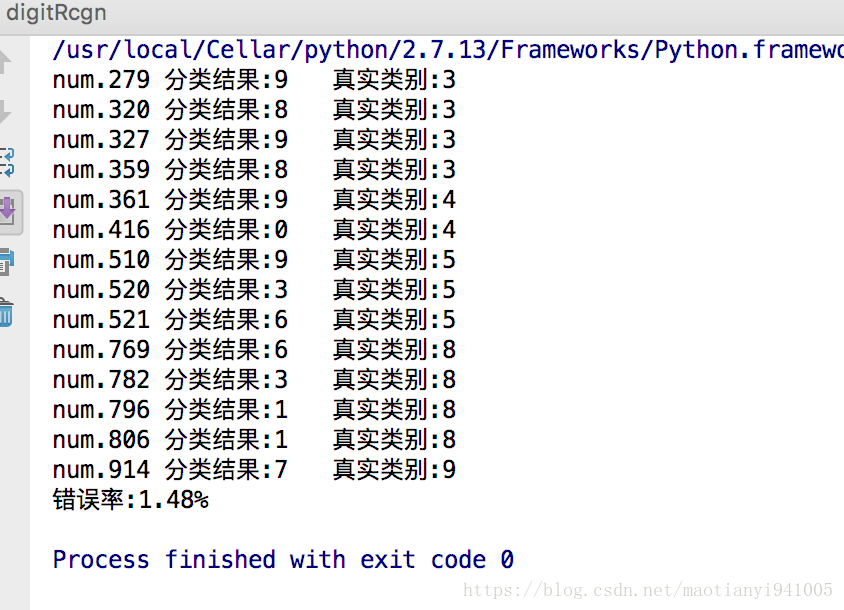
print("num.%d\t分類結果:%d\t真實類別:%d" % (i, classResult, test_y[i]))
wrongRate = countWrong / float(test_num) * 100
print("錯誤率:%.2f%%" % wrongRate)
def classify0(inX,dataSet,labels,k):
'''計算距離'''
diff = np.tile(inX,(dataSet.shape[0],1)) - dataSet
diff_2 = diff**2
distance = diff_2.sum(axis=1)**0.5
'''距離排序下標'''
sortIndex = distance.argsort()
#print(sortIndex)
classsify = {}
'''類別計數並排序'''
for i in range(k):
class_k = labels[sortIndex[i]]
classsify[class_k] = classsify.get(class_k,0) + 1
sortdata = sorted(classsify.items(),key=operator.itemgetter(1),reverse=True)
'''返回最多類別'''
return sortdata[0][0]
if __name__ == "__main__":
trainpath = "trainingDigits"
testpath = "testDigits"
k = 4
'''獲取訓練資料和測試資料'''
trainSet,train_y = createDataSet(trainpath)
testSet,test_y = createDataSet(testpath)
handWritingTest(trainSet,train_y,testSet,test_y,k)
測試結果:錯誤率1.48% 好像還不錯