
大資料學習之路【跟著阿里雲大神學習一波】
- 一、大資料相關的工作介紹
- 二、大資料工程師的技能要求
- 三、大資料學習規劃
- 四、持續學習資源推薦(書籍,部落格,網站)
- 五、專案案例分析(批處理+實時處理)
大資料介紹
大資料本質也是資料,但是又有了新的特徵,包括資料來源廣、資料格式多樣化(結構化資料、非結構化資料、Excel檔案、文字檔案等)、資料量大(最少也是TB級別的、甚至可能是PB級別)、資料增長速度快等。
針對以上主要的4個特徵我們需要考慮以下問題:
-
資料來源廣,該如何採集彙總?,對應出現了Sqoop,Cammel,Datax等工具。
-
資料採集之後,該如何儲存?,對應出現了GFS,HDFS,TFS等分散式檔案儲存系統。
-
由於資料增長速度快,資料儲存就必須可以水平擴充套件。
-
資料儲存之後,該如何通過運算快速轉化成一致的格式,該如何快速運算出自己想要的結果?
對應的MapReduce這樣的分散式運算框架解決了這個問題;但是寫MapReduce需要Java程式碼量很大,所以出現了Hive,Pig等將SQL轉化成MapReduce的解析引擎;
普通的MapReduce處理資料只能一批一批地處理,時間延遲太長,為了實現每輸入一條資料就能得到結果,於是出現了Storm/JStorm這樣的低時延的流式計算框架;
但是如果同時需要批處理和流處理,按照如上就得搭兩個叢集,Hadoop叢集(包括HDFS+MapReduce+Yarn)和Storm叢集,不易於管理,所以出現了Spark這樣的一站式的計算框架,既可以進行批處理,又可以進行流處理(實質上是微批處理)。
-
而後Lambda架構,Kappa架構的出現,又提供了一種業務處理的通用架構。
-
為了提高工作效率,加快運速度,出現了一些輔助工具:
- Ozzie,azkaban:定時任務排程的工具。
- Hue,Zepplin:圖形化任務執行管理,結果檢視工具。
- Scala語言:編寫Spark程式的最佳語言,當然也可以選擇用Python。
- Python語言:編寫一些指令碼時會用到。
- Allluxio,Kylin等:通過對儲存的資料進行預處理,加快運算速度的工具。
以上大致就把整個大資料生態裡面用到的工具所解決的問題列舉了一遍,知道了他們為什麼而出現或者說出現是為了解決什麼問題,進行學習的時候就有的放矢了。
正文
一、大資料相關工作介紹
大資料方向的工作目前主要分為三個主要方向:
- 大資料工程師
- 資料分析師
- 大資料科學家
- 其他(資料探勘等)
二、大資料工程師的技能要求
附上大資料工程師技能圖:

必須掌握的技能11條
- Java高階(虛擬機器、併發)
- Linux 基本操作
- Hadoop(HDFS+MapReduce+Yarn )
- HBase(JavaAPI操作+Phoenix )
- Hive(Hql基本操作和原理理解)
- Kafka
- Storm/JStorm
- Scala
- Python
- Spark (Core+sparksql+Spark streaming )
- 輔助小工具(Sqoop/Flume/Oozie/Hue等)
高階技能6條
- 機器學習演算法以及mahout庫加MLlib
- R語言
- Lambda 架構
- Kappa架構
- Kylin
- Alluxio
學習路徑
假設每天可以抽出3個小時的有效學習時間,加上週末每天保證10個小時的有效學習時間;
3個月會有(21*3+4*2*10)*3=423小時的學習時間。
大資料學習加群:199--427--210
第一階段(基礎階段)
1)Linux學習
- Linux作業系統介紹與安裝。
- Linux常用命令。
- Linux常用軟體安裝。
- Linux網路。
- 防火牆。
- Shell程式設計等。
2)Java 高階學習(《深入理解Java虛擬機器》、《Java高併發實戰》)—30小時
- 掌握多執行緒。
- 掌握併發包下的佇列。
- 瞭解JMS。
- 掌握JVM技術。
- 掌握反射和動態代理。
3)Zookeeper學習
- Zookeeper分散式協調服務介紹。
- Zookeeper叢集的安裝部署。
- Zookeeper資料結構、命令。
- Zookeeper的原理以及選舉機制。
第二階段(攻堅階段)
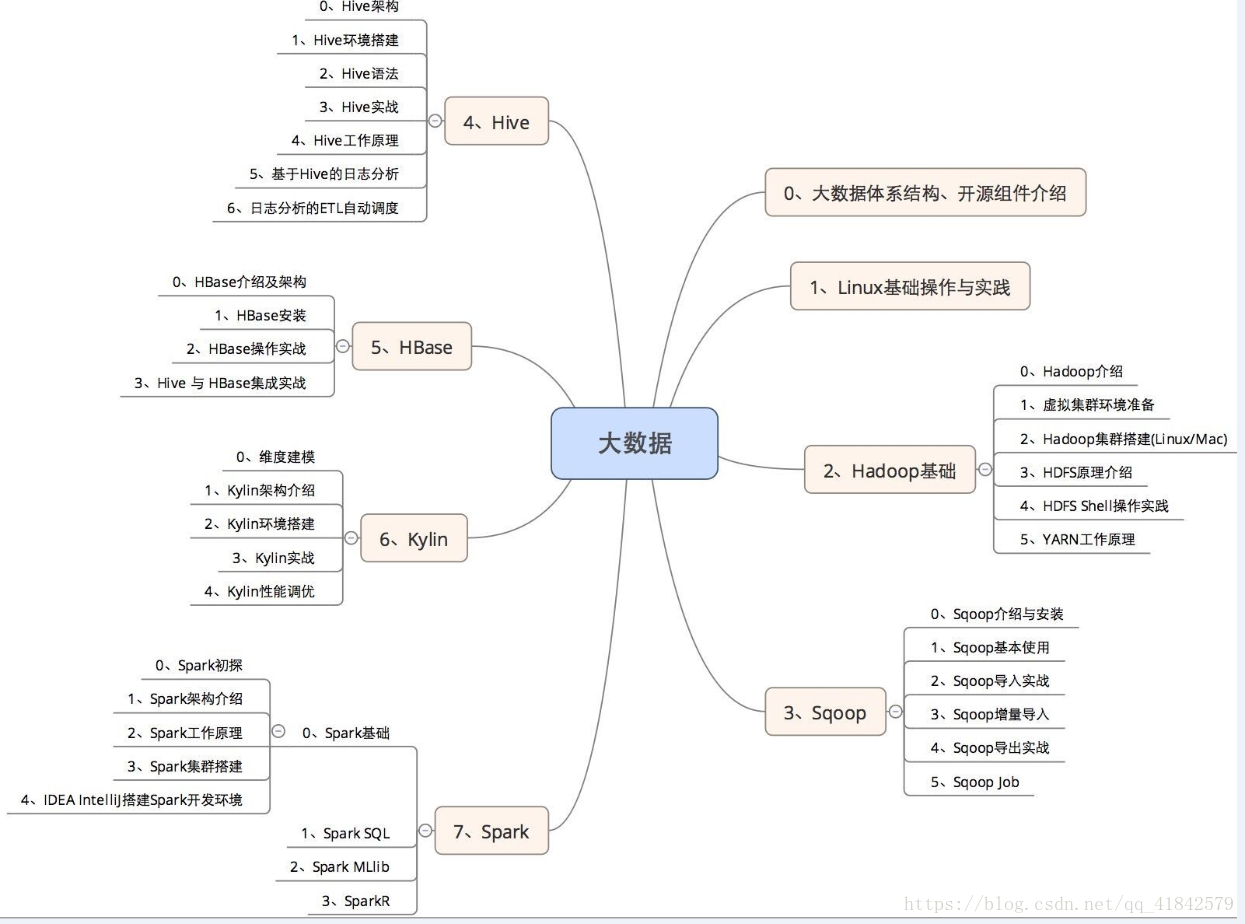
4)Hadoop (《Hadoop 權威指南》)—80小時
-
HDFS
- HDFS的概念和特性。
- HDFS的shell操作。
- HDFS的工作機制。
- HDFS的Java應用開發。
-
MapReduce
- 執行WordCount示例程式。
- 瞭解MapReduce內部的執行機制。
- MapReduce程式執行流程解析。
- MapTask併發數的決定機制。
- MapReduce中的combiner元件應用。
- MapReduce中的序列化框架及應用。
- MapReduce中的排序。
- MapReduce中的自定義分割槽實現。
- MapReduce的shuffle機制。
- MapReduce利用資料壓縮進行優化。
- MapReduce程式與YARN之間的關係。
- MapReduce引數優化。
-
MapReduce的Java應用開發
5)Hive(《Hive開發指南》)–20小時
-
Hive 基本概念
- Hive 應用場景。
- Hive 與hadoop的關係。
- Hive 與傳統資料庫對比。
- Hive 的資料儲存機制。
-
Hive 基本操作
- Hive 中的DDL操作。
- 在Hive 中如何實現高效的JOIN查詢。
- Hive 的內建函式應用。
- Hive shell的高階使用方式。
- Hive 常用引數配置。
- Hive 自定義函式和Transform的使用技巧。
- Hive UDF/UDAF開發例項
- 6)HBase(《HBase權威指南》)—20小時
- hbase簡介。
- habse安裝。
- hbase資料模型。
- hbase命令。
- hbase開發。
- hbase原理。
7)Scala(《快學Scala》)–20小時
- Scala概述。
- Scala編譯器安裝。
- Scala基礎。
- 陣列、對映、元組、集合。
- 類、物件、繼承、特質。
- 模式匹配和樣例類。
- 瞭解Scala Actor併發程式設計。
- 理解Akka。
- 理解Scala高階函式。
- 理解Scala隱式轉換。
8)Spark (《Spark 權威指南》)—60小時

-
Spark core
- Spark概述。
- Spark叢集安裝。
- 執行第一個Spark案例程式(求PI)。
-
RDD
- RDD概述。
- 建立RDD。
- RDD程式設計API(Transformation 和 Action Operations)。
- RDD的依賴關係
- RDD的快取
- DAG(有向無環圖)
-
Spark SQL and DataFrame/DataSet
- Spark SQL概述。
- DataFrames。
- DataFrame常用操作。
- 編寫Spark SQL查詢程式。
-
Spark Streaming
- park Streaming概述。
- 理解DStream。
- DStream相關操作(Transformations 和 Output Operations)。
-
Structured Streaming
-
其他(MLlib and GraphX )




自己用虛擬機器搭建一個叢集,把所有工具都裝上,自己開發一個小demo —30小時
可以自己用VMware搭建4臺虛擬機器,然後安裝以上軟體,搭建一個小叢集(本人親測,I7,64位,16G記憶體,完全可以執行起來,以下附上我學習時用虛擬機器搭建叢集的操作文件)
叢集搭建文件1.0版本
1. 叢集規劃

2. 前期準備
-
2.0 系統安裝 -
2.1 主機名配置 -
2.1.0 vi /etc/sysconfig/network -
NETWORKING=yes -
2.1.1 vi /etc/sysconfig/network -
NETWORKING=yes -
HOSTNAME=ys02 -
2.1.2 vi /etc/sysconfig/network -
NETWORKING=yes -
2.1.3 vi /etc/sysconfig/network -
NETWORKING=yes -
HOSTNAME=ys04 -
2.2 host檔案修改 -
2.2.0 vi /etc/hosts -
10.1.1.149 ys01 -
10.1.1.148 ys02 -
10.1.1.146 ys03 -
10.1.1.145 ys04 -
2.3 關閉防火牆(centos 7預設使用的是firewall,centos 6 預設是iptables) -
2.3.0 systemctl stop firewalld.service (停止firewall) -
2.3.1 systemctl disable firewalld.service (禁止firewall開機啟動) -
2.3.2 firewall-cmd --state (檢視預設防火牆狀態(關閉後顯示notrunning,開啟後顯示running) -
2.4 免密登入(ys01 ->ys02,03,04) -
ssh-keygen -t rsa -
ssh-copy-id ys02(隨後輸入密碼) -
ssh-copy-id ys03(隨後輸入密碼) -
ssh-copy-id ys04(隨後輸入密碼) -
ssh ys02(測試是否成功) -
ssh ys03(測試是否成功) -
ssh ys04(測試是否成功) -
2.5 系統時區與時間同步 -
tzselect(生成日期檔案) -
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime(將日期檔案copy到本地時間中)
3. 軟體安裝
-
3.0 安裝目錄規劃(軟體為所有使用者公用) -
3.0.0所有軟體的安裝放到/usr/local/ys/soft目錄下(mkdir /usr/local/ys/soft) -
3.0.1所有軟體安裝到/usr/local/ys/app目錄下(mkdir /usr/local/ys/app) -
3.1 JDK(jdk1.7)安裝 -
3.1.1 alt+p 後出現sftp視窗,cd /usr/local/ys/soft,使用sftp上傳tar包到虛機ys01的/usr/local/ys/soft目錄下 -
3.1.2解壓jdk -
cd /usr/local/ys/soft -
#解壓 -
tar -zxvf jdk-7u80-linux-x64.tar.gz -C /usr/local/ys/app -
3.1.3將java新增到環境變數中 -
vim /etc/profile -
#在檔案最後新增 -
export JAVA_HOME= /usr/local/ys/app/ jdk-7u80 -
export PATH=$PATH:$JAVA_HOME/bin -
3.1.4 重新整理配置 -
source /etc/profile -
3.2 Zookeeper安裝 -
3.2.0解壓 -
tar -zxvf zookeeper-3.4.5.tar.gz -C /usr/local/ys/app(解壓) -
3.2.1 重新命名 -
mv zookeeper-3.4.5 zookeeper(重新命名資料夾zookeeper-3.4.5為zookeeper) -
3.2.2修改環境變數 -
vi /etc/profile(修改檔案) -
新增內容: -
export ZOOKEEPER_HOME=/usr/local/ys/app/zookeeper -
export PATH=$PATH:$ZOOKEEPER_HOME/bin -
3.2.3 重新編譯檔案: -
source /etc/profile -
注意:3臺zookeeper都需要修改 -
3.2.4修改配置檔案 -
cd zookeeper/conf -
cp zoo_sample.cfg zoo.cfg -
vi zoo.cfg -
新增內容: -
dataDir=/usr/local/ys/app/zookeeper/data -
dataLogDir=/usr/local/ys/app/zookeeper/log -
server.1=ys01:2888:3888 (主機名, 心跳埠、資料埠) -
server.2=ys02:2888:3888 -
server.3=ys04:2888:3888 -
3.2.5 建立資料夾 -
cd /usr/local/ys/app/zookeeper/ -
mkdir -m 755 data -
mkdir -m 755 log -
3.2.6 在data資料夾下新建myid檔案,myid的檔案內容為: -
cd data -
vi myid -
新增內容: -
1 -
將叢集下發到其他機器上 -
scp -r /usr/local/ys/app/zookeeper ys02:/usr/local/ys/app/ -
scp -r /usr/local/ys/app/zookeeper ys04:/usr/local/ys/app/ -
3.2.7修改其他機器的配置檔案 -
到ys02上:修改myid為:2 -
到ys02上:修改myid為:3 -
3.2.8啟動(每臺機器) -
zkServer.sh start -
檢視叢集狀態 -
jps(檢視程序) -
zkServer.sh status(檢視叢集狀態,主從資訊) -
3.3 Hadoop(HDFS+Yarn) -
3.3.0 alt+p 後出現sftp視窗,使用sftp上傳tar包到虛機ys01的/usr/local/ys/soft目錄下 -
3.3.1 解壓jdk -
cd /usr/local/ys/soft -
#解壓 -
tar -zxvf cenos-7-hadoop-2.6.4.tar.gz -C /usr/local/ys/app -
3.3.2 修改配置檔案 -
core-site.xml

hdfs-site.xml





yarn-sifite.xml

-
svales -
ys02 -
ys03 -
ys04 -
3.3.3叢集啟動(嚴格按照下面的步驟) -
3.3.3.1啟動zookeeper叢集(分別在ys01、ys02、ys04上啟動zk) -
cd /usr/local/ys/app/zookeeper-3.4.5/bin/ -
./zkServer.sh start -
#檢視狀態:一個leader,兩個follower -
./zkServer.sh status -
3.3.3.2啟動journalnode(分別在在mini5、mini6、mini7上執行) -
cd /usr/local/ys/app/hadoop-2.6.4 -
sbin/hadoop-daemon.sh start journalnode -
#執行jps命令檢驗,ys02、ys03、ys04上多了JournalNode程序 -
3.3.3.3格式化HDFS -
#在ys01上執行命令: -
hdfs namenode -format -
#格式化後會在根據core-site.xml中的hadoop.tmp.dir配置生成個檔案,這裡我配置的是/usr/local/ys/app/hadoop-2.6.4/tmp,然後將/usr/local/ys/app/hadoop-2.6.4/tmp拷貝到ys02的/usr/local/ys/app/hadoop-2.6.4/下。 -
scp -r tmp/ ys02:/usr/local/ys /app/hadoop-2.6.4/ -
##也可以這樣,建議hdfs namenode -bootstrapStandby -
3.3.3.4格式化ZKFC(在ys01上執行一次即可) -
hdfs zkfc -formatZK -
3.3.3.5啟動HDFS(在ys01上執行) -
sbin/start-dfs.sh -
3.3.3.6啟動YARN -
sbin/start-yarn.sh -
3.3MySQL-5.6安裝 -
略過 -
3.4 Hive -
3.4.1 alt+p 後出現sftp視窗,cd /usr/local/ys/soft,使用sftp上傳tar包到虛機ys01的/usr/local/ys/soft目錄下 -
3.4.2解壓 -
cd /usr/local/ys/soft -
tar -zxvf hive-0.9.0.tar.gz -C /usr/local/ys/app -
3.4.3 .配置hive -
3.4.3.1配置HIVE_HOME環境變數 vi conf/hive-env.sh 配置其中的$hadoop_home -
3.4.3.2配置元資料庫資訊 vi hive-site.xml
新增如下內容:


-
3.4.4 安裝hive和mysq完成後,將mysql的連線jar包拷貝到$HIVE_HOME/lib目錄下 -
如果出現沒有許可權的問題,在mysql授權(在安裝mysql的機器上執行) -
mysql -uroot -p -
#(執行下面的語句 *.*:所有庫下的所有表 %:任何IP地址或主機都可以連線) -
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION; -
FLUSH PRIVILEGES; -
3.4.5 Jline包版本不一致的問題,需要拷貝hive的lib目錄中jline.2.12.jar的jar包替換掉hadoop中的 /usr/local/ys/app/hadoop-2.6.4/share/hadoop/yarn/lib/jline-0.9.94.jar -
3.4.6啟動hive -
bin/hive -
3.5 Kafka -
3.5.1 下載安裝包 -
http://kafka.apache.org/downloads.html -
在linux中使用wget命令下載安裝包 -
wget http://mirrors.hust.edu.cn/apache/kafka/0.8.2.2/kafka_2.11-0.8.2.2.tgz -
3.5.2 解壓安裝包 -
tar -zxvf /usr/local/ys/soft/kafka_2.11-0.8.2.2.tgz -C /usr/local/ys/app/ -
cd /usr/local/ys/app/ -
ln -s kafka_2.11-0.8.2.2 kafka -
3.5.3 修改配置檔案 -
cp -
/usr/local/ys/app/kafka/config/server.properties -
/usr/local/ys/app/kafka/config/server.properties.bak -
vi /usr/local/ys/kafka/config/server.properties
輸入以下內容:

-
3.5.4 分發安裝包 -
scp -r /usr/local/ys/app/kafka_2.11-0.8.2.2 ys02: /usr/local/ys/app/ -
scp -r /usr/local/ys/app/kafka_2.11-0.8.2.2 ys03: /usr/local/ys/app/ -
scp -r /usr/local/ys/app/kafka_2.11-0.8.2.2 ys04: /usr/local/ys/app/ -
然後分別在各機器上建立軟連 -
cd /usr/local/ys/app/ -
ln -s kafka_2.11-0.8.2.2 kafka -
3.5.5 再次修改配置檔案(重要) -
依次修改各伺服器上配置檔案的的broker.id,分別是0,1,2不得重複。 -
3.5.6 啟動叢集 -
依次在各節點上啟動kafka -
bin/kafka-server-start.sh config/server.properties -
3.6 Spark -
3.6.1 alt+p 後出現sftp視窗,cd /usr/local/ys/soft,使用sftp上傳tar包到虛機ys01的/usr/local/ys/soft目錄下 -
3.6.2 解壓安裝包 -
tar -zxvf /usr/local/ys/soft/ spark-1.6.1-bin-hadoop2.6.tgz -C /usr/local/ys/app/ -
3.6.3 修改Spark配置檔案(兩個配置檔案spark-env.sh和slaves) -
cd /usr/local/ys/soft/spark-1.6.1-bin-hadoop2.6 -
進入conf目錄並重命名並修改spark-env.sh.template檔案 -
cd conf/ -
mv spark-env.sh.template spark-env.sh -
vi spark-env.sh -
在該配置檔案中新增如下配置 -
export JAVA_HOME=/usr/java/jdk1.7.0_45 -
export SPARK_MASTER_PORT=7077 -
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=ys01,ys02,ys04 -Dspark.deploy.zookeeper.dir=/spark" -
儲存退出 -
重新命名並修改slaves.template檔案 -
mv slaves.template slaves -
vi slaves -
在該檔案中新增子節點所在的位置(Worker節點) -
Ys02 -
Ys03 -
Ys04 -
儲存退出 -
3.6.4 將配置好的Spark拷貝到其他節點上 -
scp -r spark-1.6.1-in-hadoop2.6/ ys02:/usr/local/ys/app -
scp -r spark-1.6.1-bin-hadoop2.6/ ys03:/usr/local/ys/app -
scp -r spark-1.6.1-bin-hadoop2.6/ ys04:/usr/local/ys/app -
3.6.5 叢集啟動 -
在ys01上執行sbin/start-all.sh指令碼 -
然後在ys02上執行sbin/start-master.sh啟動第二個Master -
3.7 Azkaban -
3.7.1 azkaban web伺服器安裝 -
解壓azkaban-web-server-2.5.0.tar.gz -
命令: tar –zxvf /usr/local/ys/soft/azkaban-web-server-2.5.0.tar.gz -C /usr/local/ys/app/azkaban -
將解壓後的azkaban-web-server-2.5.0 移動到 azkaban目錄中,並重新命名 webserver -
命令: mv azkaban-web-server-2.5.0 ../azkaban -
cd ../azkaban -
mv azkaban-web-server-2.5.0 webserver -
3.7.2 azkaban 執行服器安裝 -
解壓azkaban-executor-server-2.5.0.tar.gz -
命令:tar –zxvf /usr/local/ys/soft/azkaban-executor-server-2.5.0.tar.gz -C /usr/local/ys/app/azkaban -
將解壓後的azkaban-executor-server-2.5.0 移動到 azkaban目錄中,並重新命名 executor -
命令:mv azkaban-executor-server-2.5.0 ../azkaban -
cd ../azkaban -
mv azkaban-executor-server-2.5.0 executor -
3.7.3 azkaban指令碼匯入 -
解壓: azkaban-sql-script-2.5.0.tar.gz -
命令:tar –zxvf azkaban-sql-script-2.5.0.tar.gz -
將解壓後的mysql 指令碼,匯入到mysql中: -
進入mysql -
mysql> create database azkaban; -
mysql> use azkaban; -
Database changed -
mysql> source /usr/local/ys/soft/azkaban-2.5.0/create-all-sql-2.5.0.sql; -
3.7.4 建立SSL配置 -
參考地址: http://docs.codehaus.org/display/JETTY/How+to+configure+SSL -
命令: keytool -keystore keystore -alias jetty -genkey -keyalg RSA -
執行此命令後,會提示輸入當前生成 keystor的密碼及相應資訊,輸入的密碼請勞記,資訊如下(此處我輸入的密碼為:123456) -
輸入keystore密碼: -
再次輸入新密碼: -
您的名字與姓氏是什麼? -
[Unknown]: -
您的組織單位名稱是什麼? -
[Unknown]: -
您的組織名稱是什麼? -
[Unknown]: -
您所在的城市或區域名稱是什麼? -
[Unknown]: -
您所在的州或省份名稱是什麼? -
[Unknown]: -
該單位的兩字母國家程式碼是什麼 -
[Unknown]: CN -
CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=CN 正確嗎? -
[否]: y -
輸入<jetty>的主密碼(如果和 keystore 密碼相同,按回車): -
再次輸入新密碼 -
完成上述工作後,將在當前目錄生成 keystore 證書檔案,將keystore 考貝到 azkaban web伺服器根目錄中.如:cp keystore azkaban/webserver -
3.7.5 配置檔案 -
注:先配置好伺服器節點上的時區 -
先生成時區配置檔案Asia/Shanghai,用互動式命令 tzselect 即可 -
拷貝該時區檔案,覆蓋系統本地時區配置 -
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime -
3.7.6 azkaban web伺服器配置 -
進入azkaban web伺服器安裝目錄 conf目錄 -
修改azkaban.properties檔案 -
命令vi azkaban.properties
內容說明如下:
-
*Azkaban Personalization Settings -
azkaban.name=Test #伺服器UI名稱,用於伺服器上方顯示的名字 -
azkaban.label=My Local Azkaban #描述 -
azkaban.color=#FF3601 #UI顏色 -
azkaban.default.servlet.path=/index # -
web.resource.dir=web/ #預設根web目錄 -
default.timezone.id=Asia/Shanghai #預設時區,已改為亞洲/上海 預設為美國 -
*Azkaban UserManager class -
user.manager.class=azkaban.user.XmlUserManager #使用者許可權管理預設類 -
user.manager.xml.file=conf/azkaban-users.xml #使用者配置,具體配置參加下文 -
*Loader for projects -
executor.global.properties=conf/global.properties # global配置檔案所在位置 -
azkaban.project.dir=projects # -
database.type=mysql #資料庫型別 -
mysql.port=3306 #埠號 -
mysql.host=localhost #資料庫連線IP -
mysql.database=azkaban #資料庫例項名 -
mysql.user=root #資料庫使用者名稱 -
mysql.password=Root123456 #資料庫密碼 -
mysql.numconnections=100 #最大連線數 -
* Velocity dev mode -
velocity.dev.mode=false -
* Jetty伺服器屬性. -
jetty.maxThreads=25 #最大執行緒數 -
jetty.ssl.port=8443 #Jetty SSL埠 -
jetty.port=8081 #Jetty埠 -
jetty.keystore=keystore #SSL檔名 -
jetty.password=123456 #SSL檔案密碼 -
jetty.keypassword=123456 #Jetty主密碼 與 keystore檔案相同 -
jetty.truststore=keystore #SSL檔名 -
jetty.trustpassword=123456 # SSL檔案密碼 -
* 執行伺服器屬性 -
executor.port=12321 #執行伺服器端 -
*郵件設定 -
[email protected] #傳送郵箱 -
mail.host=smtp.163.com #傳送郵箱smtp地址 -
mail.user=xxxxxxxx #傳送郵件時顯示的名稱 -
mail.password=********** #郵箱密碼 -
[email protected] #任務失敗時傳送郵件的地址 -
[email protected] #任務成功時傳送郵件的地址 -
lockdown.create.projects=false # -
cache.directory=cache #快取目錄 -
3.7.7azkaban 執行伺服器executor配置 -
進入執行伺服器安裝目錄conf,修改azkaban.properties -
vi azkaban.properties -
*Azkaban -
default.timezone.id=Asia/Shanghai #時區 -
* Azkaban JobTypes 外掛配置 -
azkaban.jobtype.plugin.dir=plugins/jobtypes #jobtype 外掛所在位置 -
*Loader for projects -
executor.global.properties=conf/global.properties -
azkaban.project.dir=projects -
*資料庫設定 -
database.type=mysql #資料庫型別(目前只支援mysql) -
mysql.port=3306 #資料庫埠號 -
mysql.host=192.168.20.200 #資料庫IP地址 -
mysql.database=azkaban #資料庫例項名 -
mysql.user=root #資料庫使用者名稱 -
mysql.password=Root23456 #資料庫密碼 -
mysql.numconnections=100 #最大連線數 -
*執行伺服器配置 -
executor.maxThreads=50 #最大執行緒數 -
executor.port=12321 #埠號(如修改,請與web服務中一致) -
executor.flow.threads=30 #執行緒數
-
3.7.8使用者配置 -
進入azkaban web伺服器conf目錄,修改azkaban-users.xml -
vi azkaban-users.xml 增加 管理員使用者

-
3.7.9 web伺服器啟動 -
在azkaban web伺服器目錄下執行啟動命令 -
bin/azkaban-web-start.sh -
注:在web伺服器根目錄執行 -
或者啟動到後臺 -
nohup bin/azkaban-web-start.sh 1>/tmp/azstd.out 2>/tmp/azerr.out & -
3.7.10執行伺服器啟動 -
在執行伺服器目錄下執行啟動命令 -
bin/azkaban-executor-start.sh -
注:只能要執行伺服器根目錄執行 -
啟動完成後,在瀏覽器(建議使用谷歌瀏覽器)中輸入https://伺服器IP地址:8443 ,即可訪問azkaban服務了.在登入中輸入剛才新的戶用名及密碼,點選 login -
3.8 Zeppelin -
參照如下檔案: -
http://blog.csdn.net/chengxuyuanyonghu/article/details/54915817 -
http://blog.csdn.net/chengxuyuanyonghu/article/details/54915962 -
3.9 HBase -
3.9.1解壓 -
tar –zxvf /usr/local/ys/soft/hbase-0.99.2-bin.tar.gz -C /usr/local/ys/app -
3.9.2重新命名 -
cd /usr/local/ys/app -
mv hbase-0.99.2 hbase -
3.9.3修改配置檔案 -
每個檔案的解釋如下: -
hbase-env.sh -
export JAVA_HOME=/usr/local/ys/app/jdk1.7.0_80 //jdk安裝目錄 -
export HBASE_CLASSPATH=/usr/local/ys/app/hadoop-2.6.4/etc/hadoop //hadoop配置檔案的位置 -
export HBASE_MANAGES_ZK=false #如果使用獨立安裝的zookeeper這個地方就是false(此處使用自己的zookeeper) -
hbase-site.xml


-
Regionservers //是從機器的域名 -
Ys02 -
ys03 -
ys04 -
注:此處HBase配置是針對HA模式的hdfs -
3.9.4將Hadoop的配置檔案hdfs-site.xml和core-site.xml拷貝到HBase配置檔案中 -
cp /usr/local/ys/app/Hadoop-2.6.4/etc/hadoop/hdfs-site.xml /usr/local/ys/app/hbase/conf -
cp /usr/local/ys/app/hadoop-2.6.4/etc/hadoop/core-site.xml /usr/local/ys/app/hbase/conf -
3.9.5發放到其他機器 -
scp –r /usr/local/ys/app/hbase ys02: /usr/local/ys/app -
scp –r /usr/local/ys/app/hbase ys03: /usr/local/ys/app -
scp –r /usr/local/ys/app/hbase ys04: /usr/local/ys/app -
3.9.6啟動 -
cd /usr/local/ys/app/hbase/bin -
./ start-hbase.sh -
3.9.7檢視 -
程序:jps -
進入hbase的shell:hbase shell -
退出hbase的shell:quit -
頁面:http://master:60010/ -
3.10KAfkaOffsetMonitor(Kafka叢集的監控程式,本質就是一個jar包) -
3.10.1上傳jar包 -
略 -
3.10.2 執行jar包 -
nohup java -cp KafkaOffsetMonitor-assembly-0.2.1.jar com.quantifind.kafka.offsetapp.OffsetGetterWeb --zk ys01,ys02,ys04 --refresh 5.minutes --retain 1.day --port 8089 $
4. 叢集調優
-
4.1 輔助工具儘量不安裝到資料或者運算節點,避免佔用過多計算或記憶體資源。 -
4.2 dataNode和spark的slave節點儘量在一起;這樣運算的時候就可以避免通過網路拉取資料,加快運算速度。 -
4.3 Hadoop叢集機架感知配置,配置之後可以使得資料在同機架的不同機器2份,然後其他機架機器1份,可是兩臺機器四臺虛機沒有必要配感知個人感覺。 4.4 配置引數調優
第三階段(輔助工具工學習階段)
11)Sqoop(CSDN,51CTO ,以及官網)—20小時

- 資料匯出概念介紹
- Sqoop基礎知識
- Sqoop原理及配置說明
- Sqoop資料匯入實戰
- Sqoop資料匯出實戰、
- Sqoop批量作業操作
12)Flume(CSDN,51CTO ,以及官網)—20小時

- FLUME日誌採集框架介紹。
- FLUME工作機制。
- FLUME核心元件。
- FLUME引數配置說明。
- FLUME採集nginx日誌案例(案例一定要實踐一下)
13)Oozie(CSDN,51CTO ,以及官網)–20小時

- 任務排程系統概念介紹。
- 常用任務排程工具比較。
- Oozie介紹。
- Oozie核心概念。
- Oozie的配置說明。
- Oozie實現mapreduce/hive等任務排程實戰案例。
第四階段(不斷學習階段)
每天都會有新的東西出現,需要關注最新技術動態,不斷學習。任何一般技術都是先學習理論,然後在實踐中不斷完善理論的過程。
備註
1)如果你覺得自己看書效率太慢,你可以網上搜集一些課程,跟著課程走也OK 。如果看書效率不高就很網課,相反的話就自己看書。
2)企業目前更傾向於使用Spark進行微批處理,Storm只有在對時效性要求極高的情況下,才會使用,所以可以做了解。重點學習Spark Streaming。
3)快速學習的能力、解決問題的能力、溝通能力**真的很重要。
四、持續學習資源推薦
在這裡還是要推薦下我自己建的大資料學習交流群:199427210,群裡都是學大資料開發的,如果你正在學習大資料 ,小編歡迎你加入,大家都是軟體開發黨,不定期分享乾貨(只有大資料軟體開發相關的),包括我自己整理的一份2018最新的大資料進階資料和高階開發教程,歡迎進階中和進想深入大資料的小夥伴加入。