
Spark中的共享變數
spark兩種共享變數
spark中有兩種共享變數。分別為廣播變數和累加器。 廣播變數主要用於高效分發較大的資料物件,累加器主要用於對資訊進行聚合。
廣播變數
廣播變數允許我們將一個只讀的變數快取在每臺機器上,而不用在任務之間傳遞變數。廣播變數可被用於有效地給每個節點一個大輸入資料集的副本。 廣播的資料被叢集不同節點共享,且預設儲存在記憶體中,讀取速度比較快。 Spark還嘗試使用高效地廣播演算法來分發變數,進而減少通訊的開銷。 Spark的動作通過一系列的步驟執行,這些步驟由分散式的shuffle操作分開。Spark自動地廣播每個步驟每個任務需要的通用資料。這些廣播資料被序列化地快取,在執行任務之前被反序列化出來。這意味著當我們需要在多個階段的任務之間使用相同的資料,或者以反序列化形式快取資料是十分重要的時候,顯式地建立廣播變數才有用。
累加器
累加器是僅僅被相關操作累加的變數,因此可以在並行中被有效地支援。它可以被用來實現計數器和總和。Spark原生地只支援數字型別的累加器。我們可以自己新增新型別。
廣播變數的使用
廣播變數引入的原因
Spark 會自動把閉包中所有引用到的變數傳送到工作節點task上。假如你可能會在多個並行操作中使用同一個變數,但是 Spark 會為每個操作分別傳送。 例如下面一段虛擬碼:
val sparkConf: SparkConf = new SparkConf().setAppName("test").setMaster("local[2]") //建立SparkContext val sc = new SparkContext(sparkConf) //讀取日誌資料,獲取 相關資訊 val test_data= sc.textFile("D:\\tmp\\test_data.txt").map(_.split("\\|")) val ips = sc.textFile("D:\\tmp\\http.format").map(_.split("\\|")(1)) //遍歷ips中每一條資料,獲取每一個ip值 val result:RDD[((String,String),Int)]=ips.mapPartitions(iter=>{ val array = test_data.contains(iter) }).foreach(println)
test_data是任務執行需要的一份共同資料。假如test_data比較大,為1G,需要共500個task去執行,預設spark的driver會將test_data中的資料,以task的形式傳送到executor,載入到executor端裝置的記憶體中。則會導致需要記憶體為500*1G=500G,而我們的裝置不可能提供這麼大的記憶體,則會導致記憶體溢位。於是便引入了廣播變數。
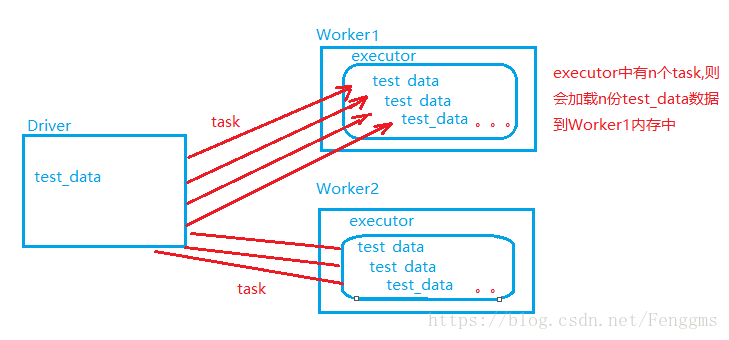
廣播變數,會將這份共同資料test_data通過driver端下發給每一個executor程序中,而不是給每個task進行傳送。後期task在執行時,直接共享executor中這份資料即可。這樣就可以減少記憶體的開銷。
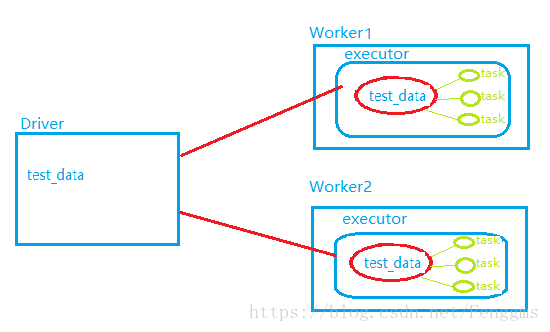
廣播變數的使用
(1) 通過對一個型別 T 的物件呼叫 SparkContext.broadcast 創建出一個 Broadcast[T] 物件。任何可序列化的型別都可以這麼實現。 (2) 通過 value 屬性訪問該物件的值(在 Java 中為 value() 方法)。 (3) 變數只會被髮到各個節點一次,應作為只讀值處理(修改這個值不會影響到別的節點)。
val sparkConf: SparkConf = new SparkConf().setAppName("test").setMaster("local[2]")
//建立SparkContext
val sc = new SparkContext(sparkConf)
//讀取日誌資料,獲取 相關資訊
val test_data= sc.textFile("D:\\tmp\\test_data.txt").map(_.split("\\|"))
val test_data_broadcast = sc.broadcast(test_data)
val ips = sc.textFile("D:\\tmp\\http.format").map(_.split("\\|")(1))
//遍歷ips中每一條資料,獲取每一個ip值
val result:RDD[((String,String),Int)]=ips.mapPartitions(iter=>{
val array = test_data_broadcast.value.contains(iter)
}).foreach(println)